







































The Evolution of Chatbots from T9-Era and GPT-1 to ChatGPT






Recently, we have been bombarded almost daily with news posts about the latest records broken by large-scale neural networks and why pretty much no one’s job is safe. Nevertheless, very few people are aware of how neural networks like ChatGPT actually operate.
So, relax. Don’t lament about your job prospects just yet. In this post, we will explain everything there is to know about neural networks in a way everyone can grasp.

A caveat before we start: This piece is a collaboration. The entire technical part was written by an AI specialist who is well-known among the AI crowd.
Since no one has yet written an in-depth piece about how ChatGPT works that would explain, in layman’s terms, the ins and outs of neural networks, we decided to do this for you. We’ve tried to keep this post as simple as possible so that readers can come out of reading this post with a general understanding of the principles of language neural networks. We’ll explore how language models work there, how neural networks evolved to possess their current capabilities, and why ChatGPT’s explosive popularity surprised even its creators.
Let’s begin with the basics. To understand ChatGPT from a technical standpoint, we must first understand what it is not. This is not Marvel Comics’ Jarvis; it is not a rational being; it is not a genie. Prepare to be shocked: ChatGPT is actually your cellphone’s T9 on steroids! Yes, it is: Scientists refer to both of these technologies as “language models.” All neural networks do is guess what word should come next.

The original T9 technology only sped up push-button phone dialing by guessing the current input rather than the next word. However, technology advanced, and by the era of smartphones in the early 2010s, it was able to consider context and the word before, add punctuation, and offer a selection of words that could go next. That is exactly the analogy we are making with such an “advanced” version of T9 or autocorrect.
As a result, both T9 on a smartphone keyboard and ChatGPT have been trained to solve a ridiculously simple task: predicting the next word. This is known as “language modeling,” and it occurs when a decision is made about what should be written next based on existing text. Language models must operate on the probabilities of the occurrence of specific words in order to make such predictions. After all, you’d be annoyed if your phone’s autofill just threw you completely random words with the same probability.
For clarity, let’s imagine that you receive a message from a friend. It says: “What are your plans for the evening?” In response, you begin typing: “I’m going to…”, and this is where T9 comes in. It may come up with completely nonsensical things like “I’m going to the moon,” no complex language model required. Good smartphone auto-complete models suggest far more relevant words.
So, how does T9 know what words are more likely to follow the already-typed text and what clearly doesn’t make sense? To answer this question, we must first examine the fundamental operating principles of the simplest neural networks.
How AI models predict the next word
Let us begin with a simpler question: How do you predict the interdependence of some things on others? Assume we want to teach a computer to predict a person’s weight based on their height — how should we go about it? We should first identify the areas of interest and then collect data that would on which to search for the dependencies of interest and then attempt to “train” some mathematical model to look for patterns within this data.
To put it simply, T9 or ChatGPT are just cleverly chosen equations that attempt to predict a word (Y) based on the set of previous words (X) fed into the model input. When training a language model on a data set, the main task is to select coefficients for these x’s that truly reflect some kind of dependence (as in our example with height and weight). And by large models, we will gain a better understanding of those with a large number of parameters. In the field of artificial intelligence, they are referred to as large language models, or LLMs for short. As we will see later, a large model with many parameters is essential for generating good text.
By the way, if you’re wondering why we’re constantly talking about “predicting one next word” while ChatGPT quickly responds with whole paragraphs of text, the answer is simple. Sure, language models can generate long texts without difficulty, but the entire process is word by word. After each new word is generated, the model simply re-runs all of the text with the new word to generate the next word. The process repeats over and over again until you get the entire response.
Why do we keep trying to find the ‘correct’ words for a given text?
Language models attempt to predict the probabilities of different words that can occur in a given text. Why is this necessary, and why can’t you just keep looking for the “most correct” word? Let’s try a simple game to illustrate how this process works.
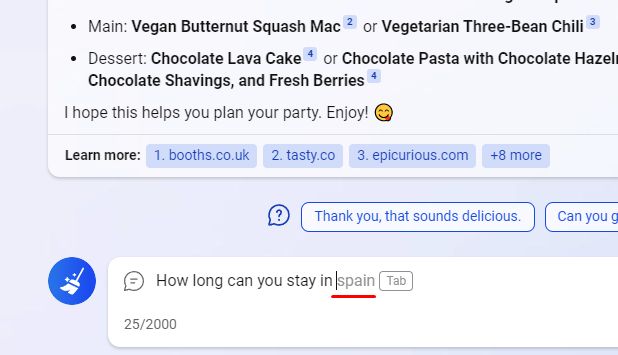
The rules are as follows: I propose that you continue the sentence: “The 44th President of the United States (and the first African American in this position) is Barak…”. What word should go next? What is the likelihood it will occur?
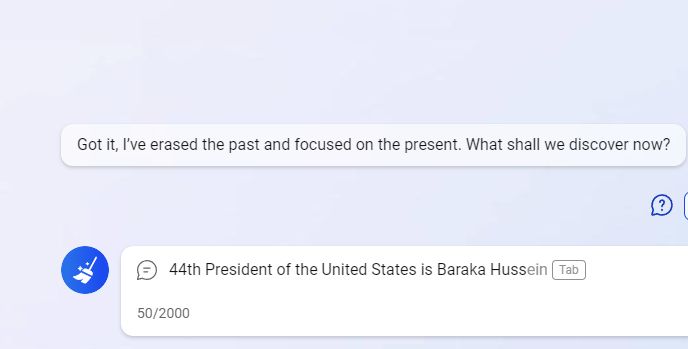
If you predicted with 100% certainty that the next word would be “Obama,” you were wrong! And the point here isn’t that there’s another mythical Barak; it’s much more trivial. Official documents usually use the president’s full name. This means what follows Obama’s first name would be his middle name, Hussein. So, in our sentence, a properly trained language model should predict that “Obama” will be the next word only with a conditional probability of 90% and allocate the remaining 10% if the text is continued by “Hussein” (after which Obama will follow with a probability close to 100%).
And now we come to an intriguing aspect of language models: They are not immune to creative streaks! In fact, when generating each next word, such models choose it in a “random” way, as if throwing a die. The probability of different words “falling out” correspond more or less to the probabilities suggested by the equations inserted inside the model. These are derived from the huge array of different texts the model was fed.
It turns out that a model can respond differently to the same requests, just like a living person. Researchers have generally attempted to force neurons to always select the “most likely” next word, but while this seems rational on the surface, such models perform worse in reality. It seems a fair dose of randomness is advantageous as it increases the variability and the quality of answers.
Our language has a unique structure with distinct sets of rules and exceptions. There is rhyme and reason to what words appear in a sentence, they don’t just occur at random. Everyone unconsciously learns the rules of the language they use during their early formative years.
A decent model should take into account the language’s wide range of descriptiveness. The model’s ability to produce the desired results depends on how precisely it calculates the probabilities of words based on the subtleties of the context (the previous section of the text explaining the circumstance).
Summary: Simple language models, which are a set of equations trained on a huge quantity of data to predict the next word based on the input source text, have been implemented in the “T9/Autofill” functionality of smartphones since the early 2010s.
GPT-1: Blowing up the industry
Let’s move away from T9 models. While you are probably reading this piece to learn about ChatGPT, first, we need to discuss the beginnings of the GPT model family.
GPT stands for “generative pre-trained transformer,” while the neural network architecture developed by Google engineers in 2017 is known as the Transformer. The Transformer is a universal computing mechanism that accepts a set of sequences (data) as input and produces the same set of sequences but in a different form that has been altered by some algorithm.
The significance of the Transformer’s creation can be seen in how aggressively it was adopted and applied in all fields of artificial intelligence (AI): translation, image, sound, and video processing. The artificial intelligence (AI) sector had a powerful shake-up, moving from the so-called “AI stagnation” to rapid development and overcoming stagnation.
The Transformer’s key strength is made up of easy-to-scale modules. When asked to process a large amount of text at once, the old, pre-transformer language models would slow down. Transformer neural networks, on the other hand, handle this task far better.
In the past, input data had to be processed sequentially or one at a time. The model would not retain the data: If it worked with a one-page narrative, it would forget the text after reading it. Meanwhile, the Transformer enables one to view everything at once, producing significantly more stunning results.
This is what enabled a breakthrough in the processing of texts by neural networks. As a result, the model no longer forgets: it reuses previously written material, better understands context, and, most crucially, is able to create connections between extremely large volumes of data by pairing words together.
Summary: GPT-1, which debuted in 2018, demonstrated that a neural network could produce texts using the Transformer design, which has significantly improved scalability and efficiency. If it were possible to enhance the quantity and complexity of language models, this would produce a sizable reserve.
GPT-2: The age of large language models
Language models don’t need to be specially tagged in advance and can be “fed” with any textual data, making them extremely flexible. If you give it some thought, it seems reasonable that we would want to use its abilities. Any text that has ever been penned serves as ready-made training data. Since there are already so many sequences of the type “a lot of some words and phrases => the next word after them,” this is not surprising.
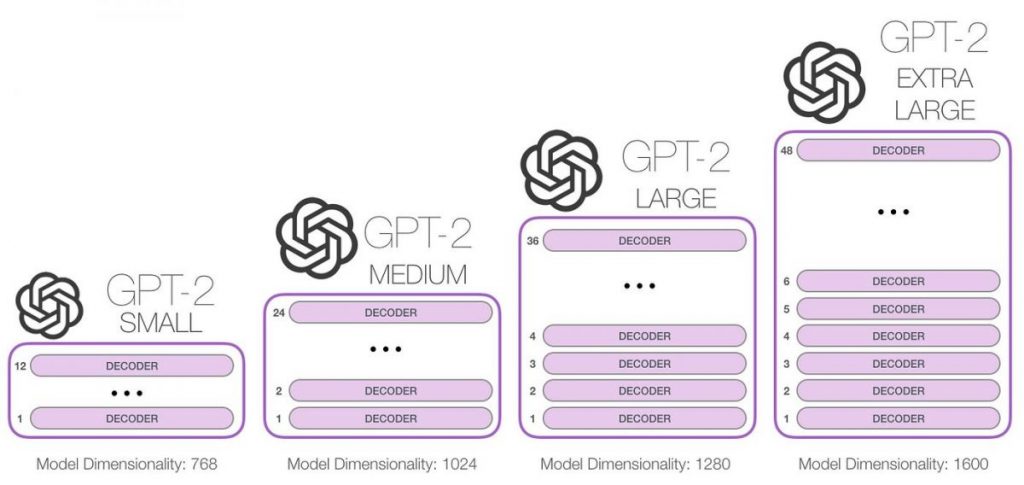
Now let’s also keep in mind that the Transformers technology tested on GPT-1 proved to be quite successful in terms of scaling: It is considerably more effective than its predecessors at handling big volumes of data. It turns out that researchers from OpenAI came to the same conclusion in 2019: “It’s time to cut expensive language models!”
The training data set and the model size, in particular, were chosen as two crucial areas where GPT-2 needed to be drastically improved.
Since there were no huge, high-quality public text data sets at the time specifically designed for training language models, each team of AI experts had to manipulate the data on their own. The OpenAI folks then made a decision to go to Reddit, the most popular English-language forum, and extract all the hyperlinks from every single post that had more than three likes. There were almost 8 million of these links, and the downloaded texts weighed 40 terabytes in total.
What number of parameters did the equation describing the largest GPT-2 model in 2019 have? Perhaps a hundred thousand or a few million? Well, let’s go even further: The formula contained up to 1.5 billion such parameters. It will take 6 terabytes to just write that many numbers into a file and save it on your computer. The model does not have to memorize this text as a whole, so on the one hand, this is far smaller than the total amount of the text data array on which trained the model; it is enough for it to simply find some dependencies (patterns, rules) that can be isolated from texts written by people.
The better the model forecasts probability and the more parameters it contains, the more complex the equation is wired into the model. This makes for a credible text. Additionally, the GPT-2 model started to perform so well that the OpenAI researchers were even reluctant to reveal the model in the open for security reasons.
It’s very interesting that when a model gets bigger, it suddenly starts to have new qualities (like the ability to write cohesive, meaningful essays instead of merely dictating the next word on the phone).
The change from quantity to quality occurs at this point. Furthermore, it happens entirely nonlinearly. For instance, a three-fold increase in the number of parameters from 115 to 350 million has no discernible impact on the model’s ability to solve problems accurately. However, a two-fold increase to 700 million produces a qualitative leap, where the neural network “sees the light” and starts to astound everyone with its ability to complete tasks.
Summary: 2019 saw the introduction of GPT-2, which 10 times outdid its predecessor in terms of the size of the model (number of parameters) and the volume of training text data. Due to this quantitative progress, the model unpredictably acquired qualitatively new talents, such as the ability to write lengthy essays with a clear meaning and solve challenging problems that call for the foundations of a worldview.
GPT-3: Smart as Hell
In general, the 2020 release of GPT-3, the next generation in the series, already boasts 116 times more parameters—up to 175 billion and an astounding 700 terabytes.
The GPT-3 training data set was also expanded, albeit not as drastically. It increased by nearly 10 times to 420 gigabytes and now contains a large number of books, Wikipedia articles, and other texts from other websites. It would take a human approximately 50 years of nonstop reading, making it an impossible feat.
You notice an intriguing difference right away: unlike GPT-2, the model itself is now 700 GB larger than the entire array of text for its training (420 GB). That turns out to be, in a sense, a paradox: in this instance, as “neurobrain” studies raw data, it generates information about various interdependencies within them that is more volumetrically abundant than the original data.
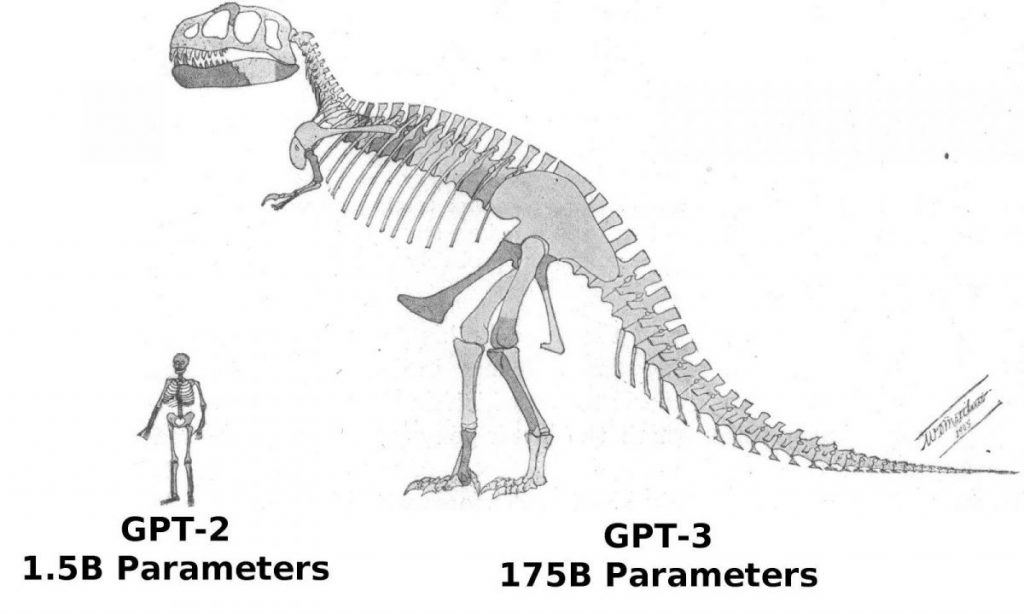
As a result of the model’s generalization, it is now able to extrapolate even more successfully than before and is successful even in text-generation tasks that occurred infrequently or not at all during training. Now, you do not need to teach the model how to tackle a certain problem; it’s enough to describe them and provide a few examples, and GPT-3 will instantly learn.
The “universal brain” in the shape of GPT-3 eventually defeated many earlier specialized models. For instance, GPT-3 started translating texts from French or German faster and more accurately than any previous neural networks created specifically for this purpose. How? Let me remind you that we are discussing a linguistic model whose sole objective was to attempt to predict the following word in a given text.
Even more astoundingly, GPT-3 was able to teach itself… math! The graph below illustrates how well neural networks perform on tasks including addition and subtraction as well as multiplication of integers up to five digits with varying numbers of parameters. As you can see, neural networks suddenly start to “be able” in mathematics while going from models with 10 billion parameters to ones with 100 billion.
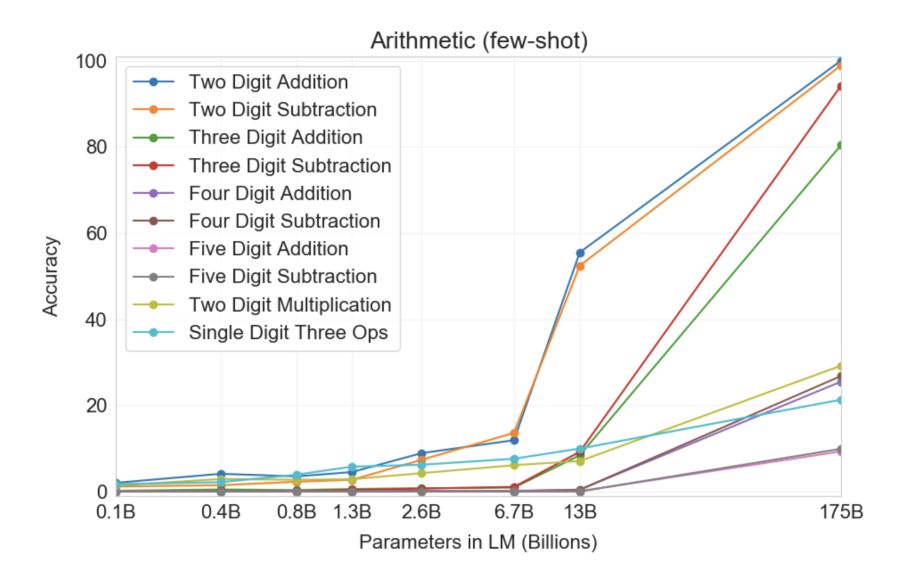
The most intriguing feature of the aforementioned graph is how, initially, nothing appears to change as the size of the model increases (from left to right), but suddenly, p times! A qualitative shift occurs, and GPT-3 starts to “understand” how to resolve a certain issue. Nobody is certain of how, what, or why it functions. Yet, it does seem to work in a variety of other difficulties as well as in mathematics.
The most intriguing feature of the aforementioned graph is that when the model’s size increases, first, nothing seems to change, and then, GPT-3 makes a qualitative leap and starts to “understand” how to resolve a certain issue.
The gif below simply demonstrates how new abilities that no one deliberately planned out “sprout” in the model as the number of parameters increases:
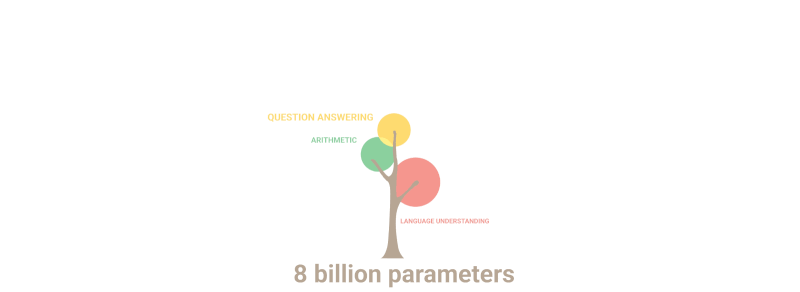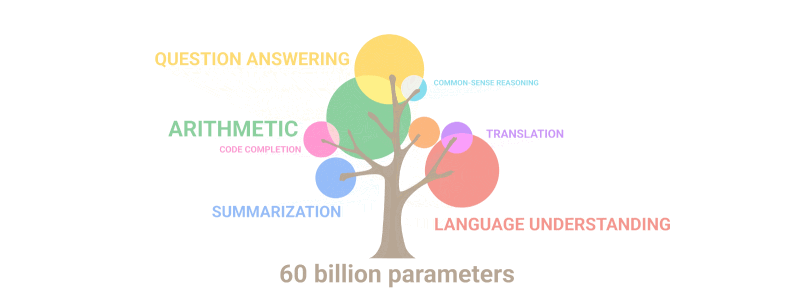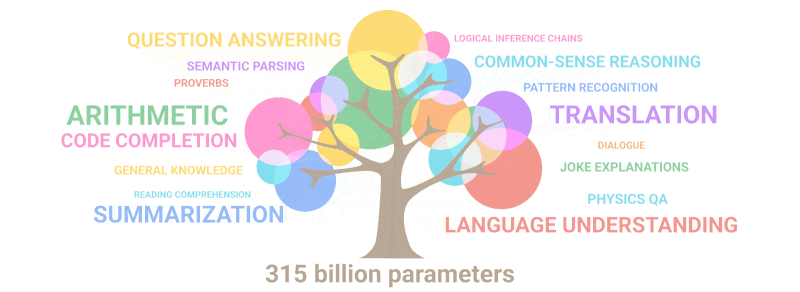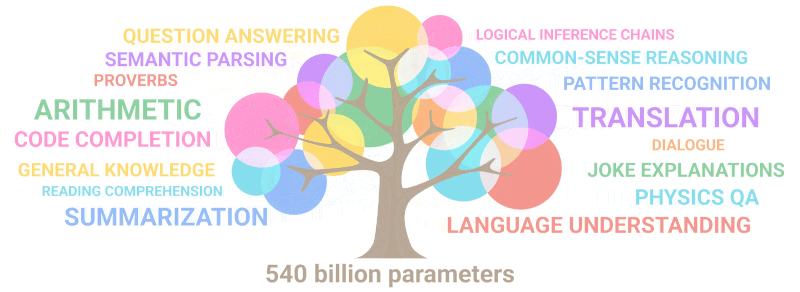
Summary: In terms of parameters, the 2020 GPT-3 was 100 times larger than its predecessor, while the training text data was 10 times larger. Once more, the model learned to translate from other languages, perform arithmetic, perform simple programming, reason sequentially, and much more as a result of the expansion in quantity that abruptly increased quality.
GPT-3.5 (InstructGPT): Model trained to be safe and non-toxic
In actuality, expanding language models does not guarantee that it will react to inquiries the way users want it to. In fact, when we make a request, we frequently intend a number of unspoken terms that, in human communication, are assumed to be true.
Yet, to be honest, language models are not very close to those of people. Thus, they frequently need to think on concepts that appear simple to people. One such suggestion is the phrase, “let’s think step by step.” It would be fantastic if the models understood or generated more specific and pertinent instructions from the request and followed them more precisely as if anticipating how a person would have behaved.
The fact that GPT-3 is trained to only anticipate the next word in a massive collection of texts from the Internet, a lot of different things are written, contributes to the lack of such “default” abilities. People want artificial intelligence to provide relevant information, all while keeping the responses safe and non-toxic.
When researchers gave this issue some thought, it became evident that the model’s attributes of “accuracy and usefulness” and “harmlessness and non-toxicity” sometimes appeared to be at odds with one another. After all, a model tuned for maximal harmlessness will react to any prompt with “Sorry, I’m concerned that my answer may offend someone on the Internet.” An exact model should frankly respond to the request, “Alright, Siri, how to create a bomb.”
The researchers were, therefore, limited to simply providing the model with a lot of feedback. In a sense, this is exactly how children learn morality: They experiment in childhood, and at the same time, they carefully study the reactions of adults to assess whether they behaved correctly.
InstructGPT, also known as GPT-3.5, is essentially GPT-3 that got a lot of feedback to enhance its replies. Literally, a number of individuals were gathered in one place, assessing neural network replies to determine how well they matched their expectations in light of the request they made.
It turns out that GPT-3 already has already had all the essential knowledge: It could understand many languages, recall historical occurrences, recognize the variations in authorial styles, and so forth, but it could only learn to use this knowledge correctly (from our point of view) with input from other individuals. GPT-3.5 can be thought of as a “society-educated” model.
Summary: The primary function of GPT-3.5, which was introduced in early 2022, was additional retraining based on input from individuals. It turns out that this model has not actually become larger and wiser, but rather, it has mastered the ability to tailor its responses to give people the wildest laughs.
ChatGPT: A Massive Surge of Hype
About 10 months after its predecessor InstructGPT/GGPT-3.5, ChatGPT was introduced. Immediately, it caused global hype.
From a technological standpoint, it doesn’t appear there are any significant differences between ChatGPT and InstructGPT. The model was trained with additional dialog data since an “AI assistant job” requires a unique dialog format, for instance, the ability to ask a clarifying question if the user’s request is unclear.
So, why was there no hype surrounding GPT-3.5 at the beginning of 2022 while ChatGPT caught on like wildfire? Sam Altman, Executive Director of OpenAI, openly acknowledged that the researchers we caught by surprise by ChatGPT’s instant success. After all, a model with abilities comparable to it had been lying dormant on their website for more than ten months at that point, and no one was up to the task.
It’s incredible, but it appears that the new user-friendly interface is the key to its success. The same InstructGPT could only be accessed via a unique API interface, limiting people’s access to the model. ChatGPT, ob the other hand, uses the well-known “dialog window” interface of messengers. Also, since ChatGPT was available to everyone at once, a stampede of individuals hurried to interact with the neural network, screen them, and post them on social media, hyping up others.
Apart from great technology, another thing was done right by OpenAI: marketing. Even if you have the best model or the most intelligent chatbot, if it doesn’t have an easy-to-use interface, no one will be interested in it. In this regard, ChatGPT achieved a breakthrough by introducing the technology to the general public using the customary dialog box, in which a helpful robot “prints” the solution right in front of our eyes, word by word.
Unsurprisingly, ChatGPT hit all previous records for attracting new users, surpassing the milestone of 1 million users in just five days of its launch and crossing 100 million users in just two months.
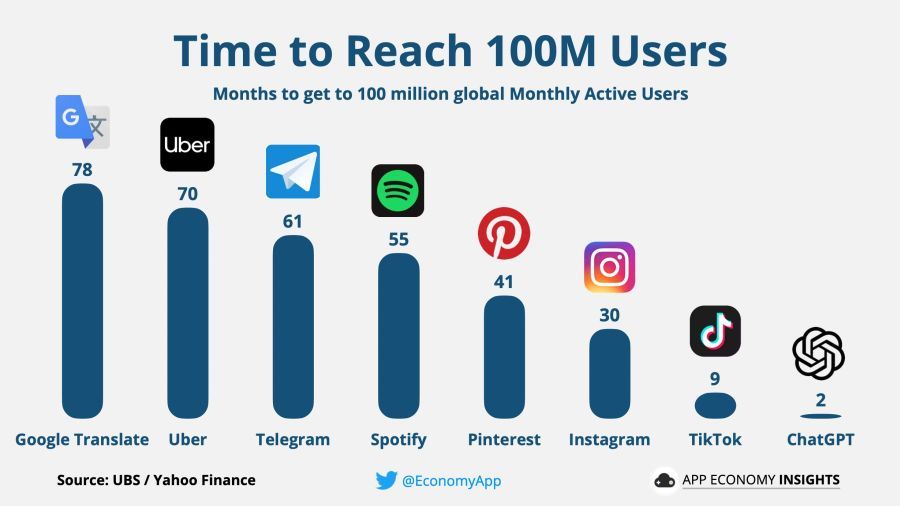
Of course, where there is a record-breaking surge in users, there is tremendous money. The Chinese urgently announced the impending release of their own chatbot, Microsoft quickly struck a deal with OpenAI to invest tens of billions of dollars in them, and Google engineers sounded the alarm and began formulating plans to protect their search service from the competition with the neural network.
Summary: When the ChatGPT model was introduced in November 2022, there weren’t any notable technological advancements. It did, however, have a convenient interface for user engagement and open access, which immediately sparked a massive surge of hype. Since this is the most crucial issue in the modern world, everyone started tackling language models right away.
Read more about AI:
Disclaimer
In line with the Trust Project guidelines, please note that the information provided on this page is not intended to be and should not be interpreted as legal, tax, investment, financial, or any other form of advice. It is important to only invest what you can afford to lose and to seek independent financial advice if you have any doubts. For further information, we suggest referring to the terms and conditions as well as the help and support pages provided by the issuer or advertiser. MetaversePost is committed to accurate, unbiased reporting, but market conditions are subject to change without notice.
About The Author
Damir is the team leader, product manager, and editor at Metaverse Post, covering topics such as AI/ML, AGI, LLMs, Metaverse, and Web3-related fields. His articles attract a massive audience of over a million users every month. He appears to be an expert with 10 years of experience in SEO and digital marketing. Damir has been mentioned in Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto, and other publications. He travels between the UAE, Turkey, Russia, and the CIS as a digital nomad. Damir earned a bachelor's degree in physics, which he believes has given him the critical thinking skills needed to be successful in the ever-changing landscape of the internet.
More articles
Damir is the team leader, product manager, and editor at Metaverse Post, covering topics such as AI/ML, AGI, LLMs, Metaverse, and Web3-related fields. His articles attract a massive audience of over a million users every month. He appears to be an expert with 10 years of experience in SEO and digital marketing. Damir has been mentioned in Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto, and other publications. He travels between the UAE, Turkey, Russia, and the CIS as a digital nomad. Damir earned a bachelor's degree in physics, which he believes has given him the critical thinking skills needed to be successful in the ever-changing landscape of the internet.





