







































StyleGAN-T: The fastest text-to-image generation that produces results in less than 0.1 second






In Brief
StyleGAN-T is a new GAN for tex2image generation.
This GAN produces good results and is even quite quick (0.1 sec for a 512×512 image).
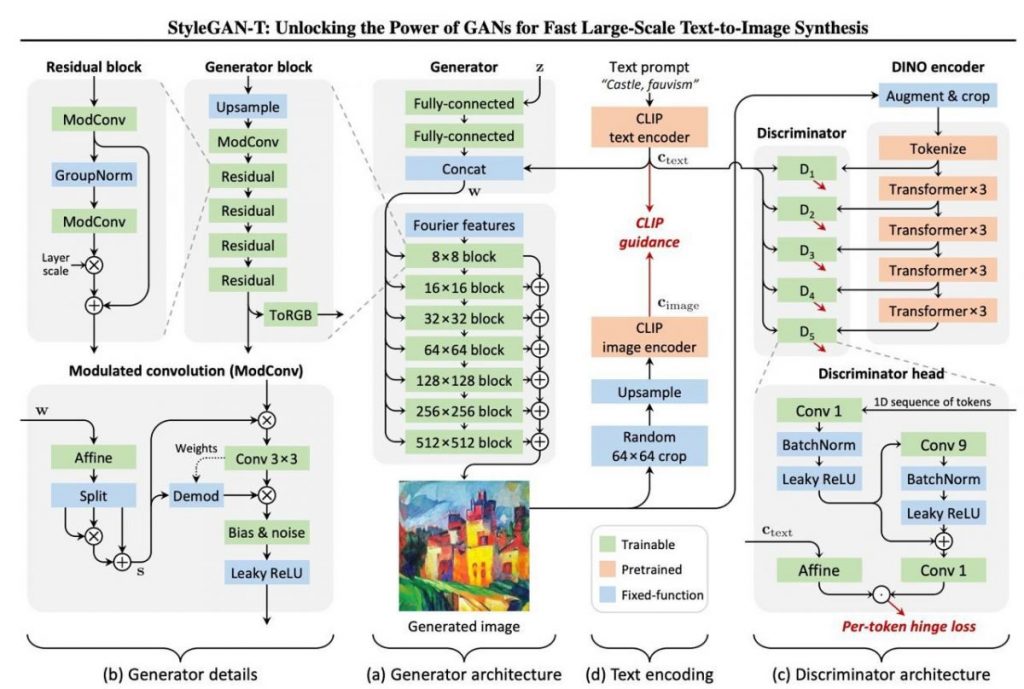
The new architecture is based on StyleGAN-XL, but it reevaluates the generator and discriminator designs.
You’ve surely noticed that GANs are no longer discussed when the topic of image generation comes up. After diffusion models like Stable Diffusion emerged, GANs somehow retreated into the background. This is because they are challenging to train and frequently trip over. The only benefit of GANs was that, unlike diffusion models, they produce an image in a single run (a “forward pass”) instead of many runs.

But now a new player from the GANs has entered the field: StyleGAN-T. This GAN for tex-to-image generation produces good results fast, as it only takes 0.1 sec for a 512×512 image. The new architecture is based on StyleGAN-XL, but it reevaluates the generator and discriminator designs and employs CLIP for text prompt alignment and generated graphics.
In general, StyleGAN-T now creates text-to-image faster and more accurately than other GANs. However, GAN is still awful and the quality of the full-size SD model is obviously out of the question. But that all will depend on ability to produce extremely high-quality images from text in less than a second in a year. Additionally, it will fall somewhere between GAN and the diffusion model.
Read more about AI:

Disclaimer
In line with the Trust Project guidelines, please note that the information provided on this page is not intended to be and should not be interpreted as legal, tax, investment, financial, or any other form of advice. It is important to only invest what you can afford to lose and to seek independent financial advice if you have any doubts. For further information, we suggest referring to the terms and conditions as well as the help and support pages provided by the issuer or advertiser. MetaversePost is committed to accurate, unbiased reporting, but market conditions are subject to change without notice.
About The Author
Damir is the team leader, product manager, and editor at Metaverse Post, covering topics such as AI/ML, AGI, LLMs, Metaverse, and Web3-related fields. His articles attract a massive audience of over a million users every month. He appears to be an expert with 10 years of experience in SEO and digital marketing. Damir has been mentioned in Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto, and other publications. He travels between the UAE, Turkey, Russia, and the CIS as a digital nomad. Damir earned a bachelor's degree in physics, which he believes has given him the critical thinking skills needed to be successful in the ever-changing landscape of the internet.
More articles
Damir is the team leader, product manager, and editor at Metaverse Post, covering topics such as AI/ML, AGI, LLMs, Metaverse, and Web3-related fields. His articles attract a massive audience of over a million users every month. He appears to be an expert with 10 years of experience in SEO and digital marketing. Damir has been mentioned in Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto, and other publications. He travels between the UAE, Turkey, Russia, and the CIS as a digital nomad. Damir earned a bachelor's degree in physics, which he believes has given him the critical thinking skills needed to be successful in the ever-changing landscape of the internet.





