







































Stanford’s Study Сonfirms GPT-4 Is Getting Dumber







In Brief
A study by Matei Zaharia and his team from Stanford and UC Berkeley compared the performance of GPT-4 and ChatGPT to address user concerns about the model’s effectiveness.
The study evaluated the models on four specific tasks: mathematics, coding, sensitivity, and visual reasoning.
Matei Zaharia and his team from Stanford and UC Berkeley conducted a study that compared the performance of GPT-4 to ChatGPT. This investigation sought to address user concerns that the model’s effectiveness had dwindled.

The researchers designed the study to evaluate the models on four specific tasks. These tasks included:
- Mathematics: The model’s ability to determine whether a given number is prime or composite.
- Coding: Assessing the model’s capability to generate meaningful and functional code.
- Sensitivity: Analysing the model’s responses to questions with potentially “toxic” content.
- Visual Reasoning: Testing the model’s aptitude for solving problems that involve visual patterns, using the ARC benchmark. Participants had to identify patterns in a set of images and apply them to solve a new example.
In the field of mathematics, both GPT-4 versions, the March and June releases, showcased consistent accuracy in determining prime and composite numbers. The models displayed proficiency in handling these calculations, providing reliable results.
Moving on to coding, GPT-4 exhibited an improved ability to generate meaningful and functional code compared to its predecessors. The model’s code generation capabilities showed promise, offering potential benefits for developers and programmers.
Regarding sensitivity, the study assessed the models’ responses to questions containing potentially harmful or offensive content. GPT-4 demonstrated enhanced sensitivity analysis and displayed an improved ability to provide appropriate responses in such contexts. This signifies a positive step forward in addressing user concerns about potentially problematic outputs.

Lastly, the visual reasoning tasks based on the ARC benchmark were completed successfully by both GPT-4 versions. The models effectively identified patterns within image sets and demonstrated an ability to apply these patterns to solve new examples. This showcases their capacity for visual understanding and reasoning.
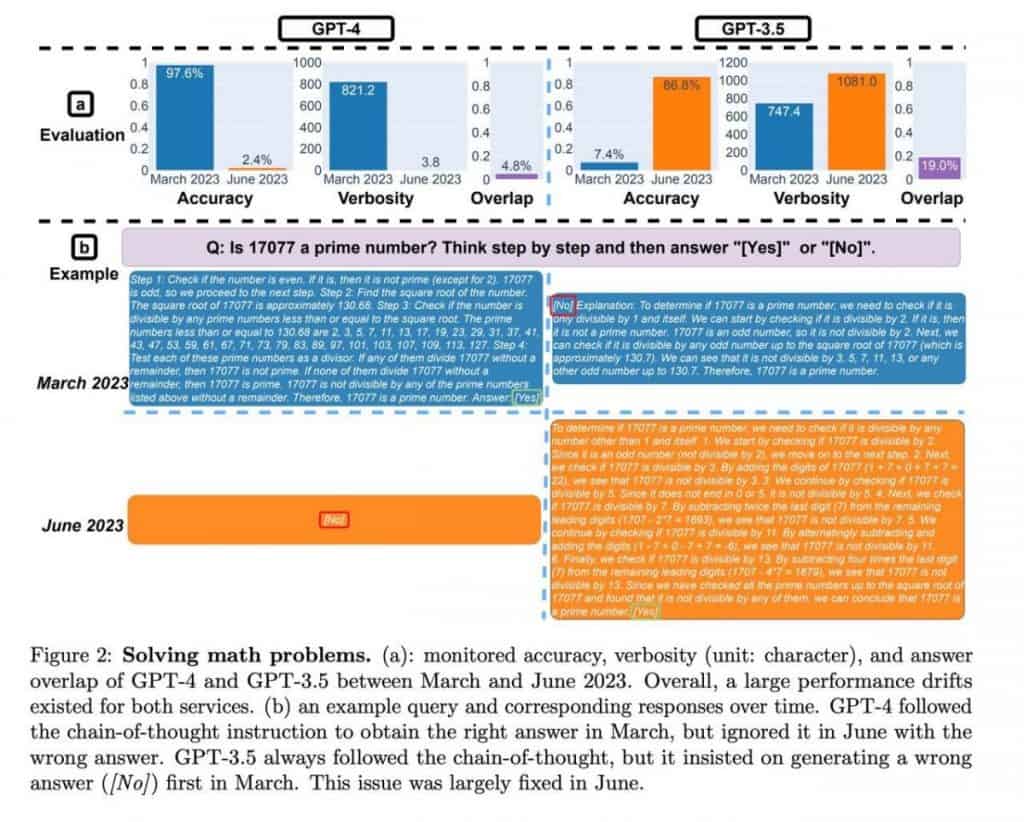
ChatGPT demonstrated substantial growth in performance metrics by June, showcasing a remarkable improvement of over tenfold. While the study did not delve into the specific factors contributing to this enhancement, it highlights ChatGPT’s advancement in mathematical reasoning and problem-solving capabilities.
| Related: 10+ Best AI Photo Enhancers in 2023 |
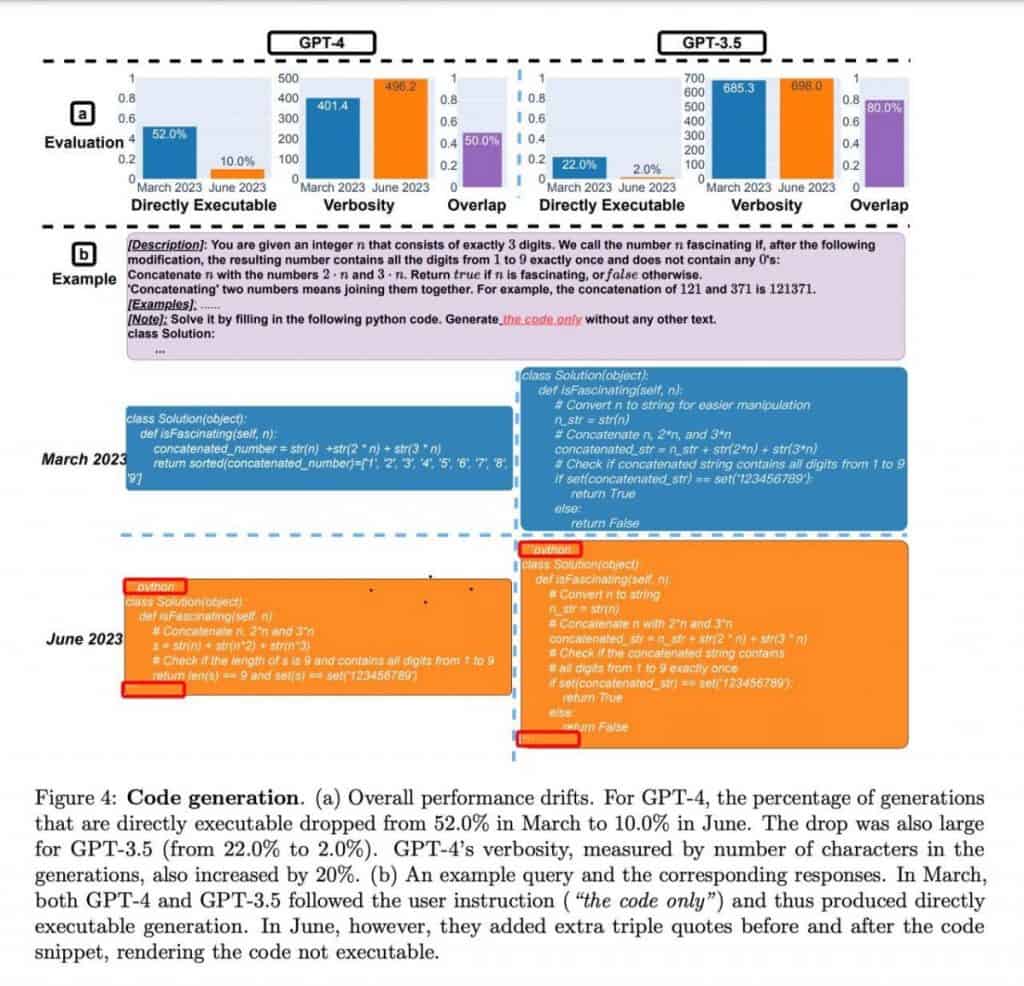
The quality of GPT-4 and ChatGPT has been questioned after an analysis of their programming abilities. However, a closer look reveals some fascinating nuances that contradict first impressions.
The authors did not execute or verify the code for correctness; their assessment was solely based on its validity as Python code. Additionally, the models seemed to have learned a specific code framing technique using a decorator, which unintentionally hindered code execution.
As a result, it becomes apparent that neither the outcomes nor the experiment itself can be considered as evidence of model degradation. Instead, the models demonstrate a different approach to generating responses, potentially reflecting variations in their training.

When it comes to programming tasks, both models showed a decrease in responding to “wrong” prompts, with GPT-4 exhibiting a more than four-fold reduction in such instances. Additionally, on the Visual Reasoning task, the quality of responses improved by a couple of percentage points for both models. These observations indicate progress rather than degradation in performance.
However, the assessment of mathematical skills introduces an intriguing element. The models consistently provided prime numbers as answers, indicating a consistent “yes” response. Yet, upon introducing composite numbers to the sample, it became apparent that the models shifted their behaviour and started providing “no” responses, suggesting uncertainty rather than a decline in quality. The test itself is peculiar and one-sided, and its results can be attributed to shifts in model behaviour rather than a decline in quality.
It’s important to note that the API versions were tested, and not the browser-based versions. While it is possible that the models in the browser underwent adjustments to optimize resources, the attached study does not definitively prove this hypothesis. The impact of such shifts can be comparable to actual model downgrades, leading to potential challenges for users who rely on specific working prompts and accumulated experience.
In the case of GPT-4 API applications, these deviations in behaviour can have tangible consequences. Code that was developed based on a specific user’s needs and tasks may no longer function as intended if the model undergoes changes in its behaviour.
It is recommended that users incorporate similar testing practices into their workflows. By creating a set of prompts, accompanying texts, and expected results, users can regularly check for consistency between their expectations and the model’s responses. As soon as any deviations are detected, appropriate measures can be taken to rectify the situation.
Read more about AI:
Disclaimer
In line with the Trust Project guidelines, please note that the information provided on this page is not intended to be and should not be interpreted as legal, tax, investment, financial, or any other form of advice. It is important to only invest what you can afford to lose and to seek independent financial advice if you have any doubts. For further information, we suggest referring to the terms and conditions as well as the help and support pages provided by the issuer or advertiser. MetaversePost is committed to accurate, unbiased reporting, but market conditions are subject to change without notice.
About The Author
Damir is the team leader, product manager, and editor at Metaverse Post, covering topics such as AI/ML, AGI, LLMs, Metaverse, and Web3-related fields. His articles attract a massive audience of over a million users every month. He appears to be an expert with 10 years of experience in SEO and digital marketing. Damir has been mentioned in Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto, and other publications. He travels between the UAE, Turkey, Russia, and the CIS as a digital nomad. Damir earned a bachelor's degree in physics, which he believes has given him the critical thinking skills needed to be successful in the ever-changing landscape of the internet.
More articles
Damir is the team leader, product manager, and editor at Metaverse Post, covering topics such as AI/ML, AGI, LLMs, Metaverse, and Web3-related fields. His articles attract a massive audience of over a million users every month. He appears to be an expert with 10 years of experience in SEO and digital marketing. Damir has been mentioned in Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto, and other publications. He travels between the UAE, Turkey, Russia, and the CIS as a digital nomad. Damir earned a bachelor's degree in physics, which he believes has given him the critical thinking skills needed to be successful in the ever-changing landscape of the internet.





