







































Stability AI’s Stable Diffusion 2 Algorithm Is Finally Public: new depth2img model, super-resolution upscaler, no adult content







In Brief
Stable Diffusion 2.0 model is faster, open source, scalable, more robust than previous one
Stable Diffusion gets GPU-ready with new features for real-time rendering
Depth-guided stable diffusion model – Image-to-image with new ideas for creative applications
Stability AI has released a new paper on its blog about Stable Diffusion 2. In it, Stability AI proposes a new algorithm that is more efficient and robust than the previous one while benchmarking it against other state-of-the-art methods.

CompVis’ original Stable Diffusion V1 model revolutionized the nature of open-source AI models and produced hundreds of different models and advances around the world. It saw one of the fastest climbs to 10,000 Github stars, racking up 33,000 in less than two months, faster than more programs on Github.
The original Stable Diffusion V1 release was led by the dynamic team of Robin Rombach (Stability AI) and Patrick Esser (Runway ML) from the CompVis Group at LMU Munich, led by Prof. Dr. Björn Ommer. They built on the lab’s previous work with Latent Diffusion Models and received critical support from LAION and Eleuther AI.


What makes Stable Diffusion v1 different from Stable Diffusion v2?
Stable Diffusion 2.0 includes a number of significant enhancements and features over the previous version, so let’s take a look at them.
The Stable Diffusion 2.0 release features robust text-to-image models trained with a fresh new text encoder (OpenCLIP) developed by LAION with assistance from Stability AI, which significantly enhances the quality of the generated images over previous V1 releases. This release’s text-to-image models can output images with default resolutions of 512×512 pixels and 768×768 pixels.

These models are trained using an aesthetic subset of the LAION-5B dataset generated by Stability AI’s DeepFloyd team, which is then filtered to exclude adult content using LAION’s NSFW filter.
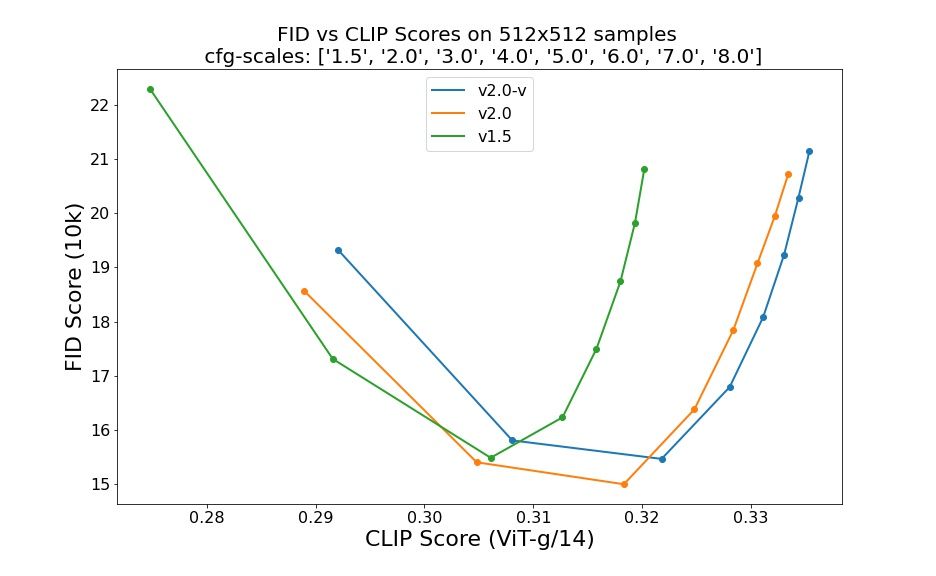
Evaluations using 50 DDIM sample steps, 50 classifier-free guiding scales, and 1.5, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, and 8.0 indicate relative improvements of the checkpoints:
Stable Diffusion 2.0 now incorporates an Upscaler Diffusion model, which increases image resolution by a factor of four. An example of our model upscaling a low-quality generated image (128×128) into a higher resolution image is shown below (512×512). Stable Diffusion 2.0, when combined with our text-to-image models, can now generate images with resolutions of 2048×2048 or higher.

The new depth-guided stable diffusion model, depth2img, extends the prior image-to-image feature from V1 with entirely new creative possibilities. Depth2img determines the depth of an input image (using an existing model) and then generates new images based on both the text and the depth information. Depth-to-Image can provide a plethora of new creative applications, offering changes that seem significantly different from the original while retaining the image’s coherence and depth.
What is new in Stable Diffusion 2?
- The new stable diffusion model offers a 768×768 resolution.
- The U-Net has the same amount of parameters as version 1.5, but it is trained from scratch and uses OpenCLIP-ViT/H as its text encoder. A so-called v-prediction model is SD 2.0-v.
- The aforementioned model was adjusted from SD 2.0-base, which is also made available and was trained as a typical noise-prediction model on 512×512 images.
- A latent text-guided diffusion model with x4 scaling has been added.
- Refined SD 2.0-base depth-guided stable diffusion model. The model can be utilized for structure-preserving img2img and shape-conditional synthesis and is conditioned on monocular depth estimates deduced by MiDaS.
- An improved text-guided inpainting model built on the SD 2.0 foundation.
Developers worked hard, just like the initial iteration of Stable Diffusion, to optimize the model to run on a single GPU—they wanted to make it accessible to as many people as possible from the outset. They’ve already seen what happens when millions of individuals get their hands on these models and collaborate to build absolutely remarkable things. This is the power of open source: harnessing the vast potential of millions of talented people who may not have the resources to train a cutting-edge model but have the ability to do incredible things with one.

This new update, combined with powerful new features like depth2img and better resolution upscaling capabilities, will serve as the foundation for a plethora of new applications and enable an explosion of new creative potential.
Read more about Stable Diffusion:
Disclaimer
In line with the Trust Project guidelines, please note that the information provided on this page is not intended to be and should not be interpreted as legal, tax, investment, financial, or any other form of advice. It is important to only invest what you can afford to lose and to seek independent financial advice if you have any doubts. For further information, we suggest referring to the terms and conditions as well as the help and support pages provided by the issuer or advertiser. MetaversePost is committed to accurate, unbiased reporting, but market conditions are subject to change without notice.
About The Author
Damir is the team leader, product manager, and editor at Metaverse Post, covering topics such as AI/ML, AGI, LLMs, Metaverse, and Web3-related fields. His articles attract a massive audience of over a million users every month. He appears to be an expert with 10 years of experience in SEO and digital marketing. Damir has been mentioned in Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto, and other publications. He travels between the UAE, Turkey, Russia, and the CIS as a digital nomad. Damir earned a bachelor's degree in physics, which he believes has given him the critical thinking skills needed to be successful in the ever-changing landscape of the internet.
More articles
Damir is the team leader, product manager, and editor at Metaverse Post, covering topics such as AI/ML, AGI, LLMs, Metaverse, and Web3-related fields. His articles attract a massive audience of over a million users every month. He appears to be an expert with 10 years of experience in SEO and digital marketing. Damir has been mentioned in Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto, and other publications. He travels between the UAE, Turkey, Russia, and the CIS as a digital nomad. Damir earned a bachelor's degree in physics, which he believes has given him the critical thinking skills needed to be successful in the ever-changing landscape of the internet.





