







































MiniGPT-4: The New AI Model for Complex Image Descriptions






In Brief
MiniGPT-4 is an AI model that combines visual processing with language understanding.
It uses a frozen visual encoder called Vicuna and GPT-4, the latest Large Language Model from OpenAI.
MiniGPT-4 can generate accurate image descriptions, write texts based on images, provide solutions to problems depicted in pictures, and even teach users how to do certain things based on photos.

Understanding how to interpret and describe visual content is essential for a wide range of applications, from e-commerce to social media. Enter MiniGPT-4, the latest AI model that combines the power of visual processing with cutting-edge language understanding.
MiniGPT-4 employs a frozen visual encoder and a large language model, connected through a single projection layer, to generate accurate image descriptions, write stories and poems based on images, provide solutions to problems depicted in pictures, and even teach users how to cook based on food photos.
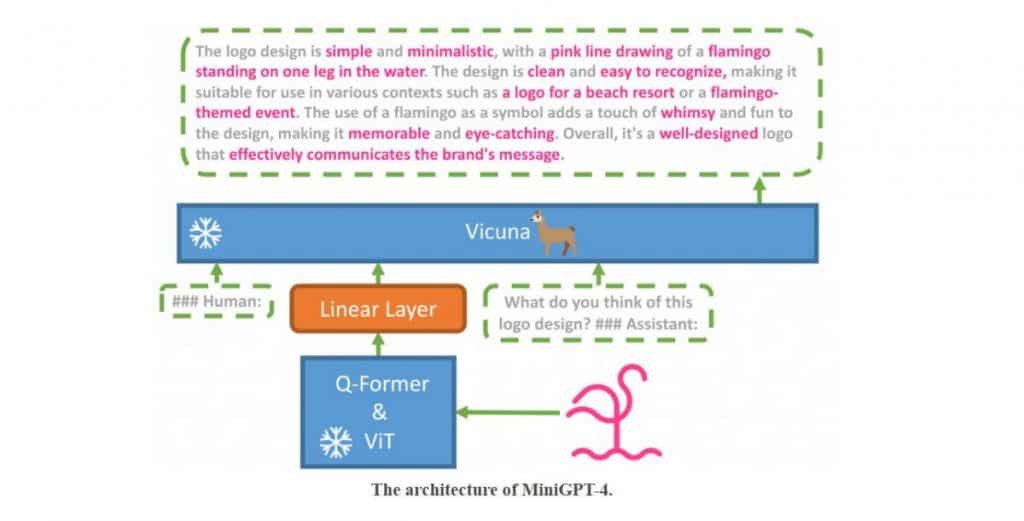
The model is highly efficient, requiring only the alignment of 5 million image-text pairs to train the linear layer that aligns visual features with the frozen large language model, Vicuna.
Vicuna is built upon LLaMA and can perform complex linguistic tasks. GPT-4, the latest Large Language Model from OpenAI, powers MiniGPT-4. The multimodal nature of GPT-4 sets it apart from its predecessors, making it suitable for various applications, including video games, Chrome extensions, and complex reasoning questions.
MiniGPT-4 has shown similar abilities to GPT-4, such as generating detailed image descriptions and creating websites from hand-written drafts. To improve the model’s language output, a better dataset was curated for further fine-tuning using a conversational template. This resulted in better language generation with improved reliability and overall usability.
The model’s exceptional capabilities stem from its two-stage training process, which allows MiniGPT to generate accurate and natural language descriptions of images. During the first stage, MiniGPT-4 is trained on millions of image-text pairs, as mentioned above, allowing it to learn about objects, people, and places and describe them in words. This pre-training takes about 10 hours and requires four A100 (80GB) GPUs. The output of this stage is generated by the vision transformer based on the input image.
However, the first stage of pre-training can produce outputs that lack coherence, such as repetitive phrases, fragmented sentences, or irrelevant content. To address this issue, MiniGPT-4 undergoes a second stage of training, where a smaller but high-quality dataset of image-text pairs is used to fine-tune the model’s text descriptions to be more accurate and natural.
From generating website layouts to providing solutions to problems depicted in images, MiniGPT-4 is an impressive step forward in the world of AI, and it’s only the beginning.
Read more:
Disclaimer
In line with the Trust Project guidelines, please note that the information provided on this page is not intended to be and should not be interpreted as legal, tax, investment, financial, or any other form of advice. It is important to only invest what you can afford to lose and to seek independent financial advice if you have any doubts. For further information, we suggest referring to the terms and conditions as well as the help and support pages provided by the issuer or advertiser. MetaversePost is committed to accurate, unbiased reporting, but market conditions are subject to change without notice.
About The Author
Agne is a journalist who covers the latest trends and developments in the metaverse, AI, and Web3 industries for the Metaverse Post. Her passion for storytelling has led her to conduct numerous interviews with experts in these fields, always seeking to uncover exciting and engaging stories. Agne holds a Bachelor’s degree in literature and has an extensive background in writing about a wide range of topics including travel, art, and culture. She has also volunteered as an editor for the animal rights organization, where she helped raise awareness about animal welfare issues. Contact her on [email protected].
More articles
Agne is a journalist who covers the latest trends and developments in the metaverse, AI, and Web3 industries for the Metaverse Post. Her passion for storytelling has led her to conduct numerous interviews with experts in these fields, always seeking to uncover exciting and engaging stories. Agne holds a Bachelor’s degree in literature and has an extensive background in writing about a wide range of topics including travel, art, and culture. She has also volunteered as an editor for the animal rights organization, where she helped raise awareness about animal welfare issues. Contact her on [email protected].




