







































Microsoft has released a diffusion model that can build a 3D avatar from a single photo of a person






In Brief
A single 2D image of a person’s face can be used to generate a 3D avatar using the 3D Avatar Diffusion machine learning technique.
It can be used to provide a realistic 3D view of the person for gaming or other uses, or to provide a virtual reality (VR) or augmented reality (AR) experience.
The 3D Avatar Diffusion is a machine learning algorithm that can take a single 2D image of a human face and create a three-dimensional (3D) avatar. The avatar can then be used to create a virtual reality (VR) or augmented reality (AR) experience or to simply provide a realistic 3D view of the person for gaming or other purposes.
The diffusion model was developed by a team of researchers at Microsoft Research and is described in a paper published in the journal arXiv.

The 3D Avatar Diffusion is based on a type of machine-learning algorithm called a diffusion model. Diffusion models are generative models, which means they can generate new data that is similar to the training data. Diffusion models have been used before to generate 3D images from 2D images, but the ADM is the first diffusion model that can generate a realistic 3D avatar from a single 2D image.
To train the model, the researchers used a dataset of over 200,000 3D face models. The dataset included a wide variety of faces with different skin tones, hairstyles, and facial features. The ADM was then able to learn the relationship between the 2D image and the 3D face model and generate a realistic 3D avatar from a single 2D image.
The model can also be used to generate an avatar from a photo that has been taken from a different angle
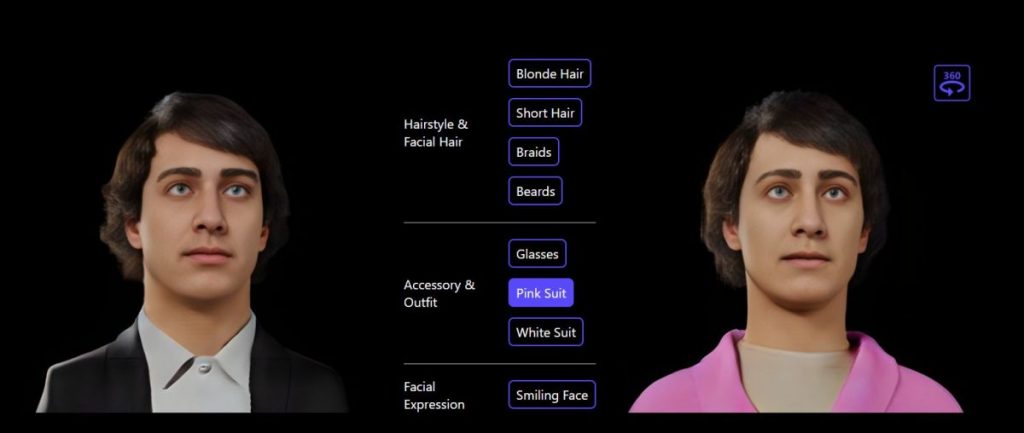
This study proposes a 3D generative model that automatically creates 3D digital avatars that are represented as neural radiance fields using diffusion models. Because of the prohibitive memory and processing requirements associated with 3D, creating the rich features necessary for high-quality avatars is a huge issue. Developers suggest the roll-out diffusion network (Rodin) address this issue.


This network rolls out numerous 2D feature maps of a neural radiance field into a single 2D feature plane, where the model then executes 3D-aware diffusion. The Rodin model uses 3D-aware convolution, which attends to projected features in the 2D feature plane according to their original relationship in 3D, to provide the much-needed computational efficiency while maintaining the integrity of diffusion in 3D.
Read more about AI:
Disclaimer
In line with the Trust Project guidelines, please note that the information provided on this page is not intended to be and should not be interpreted as legal, tax, investment, financial, or any other form of advice. It is important to only invest what you can afford to lose and to seek independent financial advice if you have any doubts. For further information, we suggest referring to the terms and conditions as well as the help and support pages provided by the issuer or advertiser. MetaversePost is committed to accurate, unbiased reporting, but market conditions are subject to change without notice.
About The Author
Damir is the team leader, product manager, and editor at Metaverse Post, covering topics such as AI/ML, AGI, LLMs, Metaverse, and Web3-related fields. His articles attract a massive audience of over a million users every month. He appears to be an expert with 10 years of experience in SEO and digital marketing. Damir has been mentioned in Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto, and other publications. He travels between the UAE, Turkey, Russia, and the CIS as a digital nomad. Damir earned a bachelor's degree in physics, which he believes has given him the critical thinking skills needed to be successful in the ever-changing landscape of the internet.
More articles
Damir is the team leader, product manager, and editor at Metaverse Post, covering topics such as AI/ML, AGI, LLMs, Metaverse, and Web3-related fields. His articles attract a massive audience of over a million users every month. He appears to be an expert with 10 years of experience in SEO and digital marketing. Damir has been mentioned in Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto, and other publications. He travels between the UAE, Turkey, Russia, and the CIS as a digital nomad. Damir earned a bachelor's degree in physics, which he believes has given him the critical thinking skills needed to be successful in the ever-changing landscape of the internet.





