







































LLM Programs: The New Path to Fine-tuning Neural Models in Complex Situations







In Brief
The authors propose an alternative path called LLM Programs, which can be considered as the development of in-context learning.
The key to solving a problem through the LLM Program is the ability to decompose the solution to a problem into a sequence of simpler steps.
There are two main areas of LLM customization: fine-tuning (or additional training) the pre-trained base model and in-context learning. Fine-tuning requires significant computing resources, data collection, and infrastructure to do this and then host fine-tuned models. Meanwhile, in-context learning involves compiling the right prompt with examples of solving the problem, such as Chain-of-Thought (CoT). However, there are some difficulties, such as the limited size of the text that can be submitted to the model and the fact that in a complex multi-pass prompt, the steps can interfere with each other, and the model can be distracted by something that should not be distracted at the moment. The authors propose an alternative path called LLM Programs, which can be considered as the development of in-context learning.

| Recommended: Prompt Engineering Ultimate Guide 2023 |
LLM is built into the program (in a conventional programming language, for example, in Python). This external code is responsible for storing the state and maintaining the model step by step. It has a few major advantages: Programming languages are adapted for this, the size of the available context grows, and the steps do not interfere with one another. The key to solving a problem through the LLM Program is the ability to decompose the solution to a problem into a sequence of simpler steps. This approach differs from previous works, where the model used external tools such as calculators or code interpreters to maintain the state. This approach is good because it is possible to describe a complex and spreading task in this way, making it easier to test, debug, and evaluate quality.
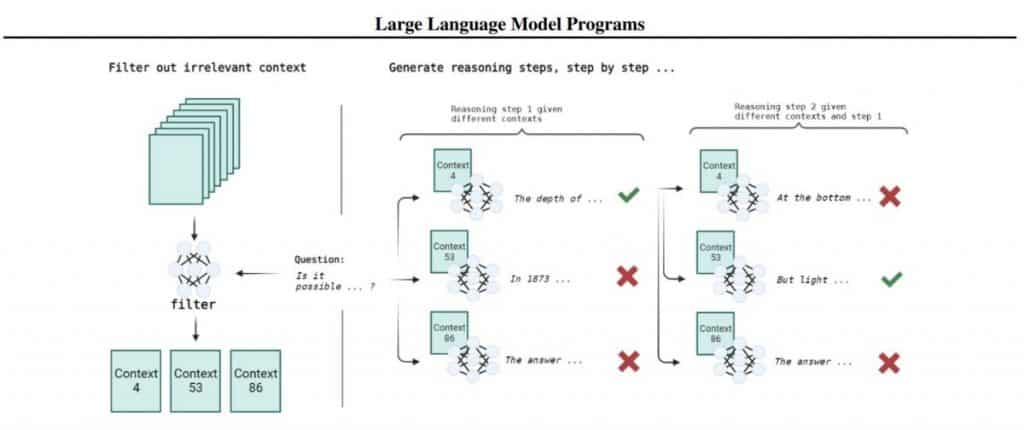
Additionally, there is no interference between the steps, making it easier to work with LLM. Question-answer systems are not new either; they’ve existed long before LLMs. How is the task of answering questions solved now?
Sites are updated frequently, so a frozen model is not an option; it will quickly become outdated and will not be able to answer questions about new products. Constant retraining of the model for each update is not a realistic option: It’s expensive and time-consuming. Instead, a website’s pages are usually indexed, put in some kind of database, and often vectored. At a user’s request, relevant documents are pulled up and sent as a context to LLM.
In such a paradigm, the problem is naturally solved through the LLM Program. As a bonus, it becomes possible to implement more complex multi-pass logic that would not fit entirely into the context.

Tested on the StrategyQA dataset containing binary classification problems, the solution of which involves multi-way reasoning. Like “Does sunlight penetrate into the deepest place of the Black Sea?”. To answer, you need to find the maximum depth (2 km) and how deep light penetrates water (1 km), and then draw a conclusion. Let’s have a look at another example question: “Did Aristotle use a laptop?” This question is not as straightforward and does not follow the sequence of reasoning steps explicitly as “Was Aristotle alive when the laptop was invented?” does. The dataset focuses on questions where such a sequence is implicit. There are only 2,780 questions in the dataset, of which only 918 have paragraphs with evidence that reinforce all the steps of the reasoning. In current work, it limits to this subset; otherwise, we would have to rely on LLM learning some facts during pretraining.
The OPT-175B LLM, by default, is not very good at following instructions; it did not have to finetune instructions nor on conversational data. To solve the evidence-supported question-answering problem, is divided into a data filtering stage and a tree search stage.
At the filtering stage, having a question, developers go through all the paragraphs and select the most relevant ones. For example, with a few-shot prompt, ask the LLM to answer (yes/no) whether a given paragraph is relevant to the question asked. Tested on a 300 subset of StrategyQA, where each question was matched with a paragraph, relevant or not, 50/50. OPT-175B and text-davinci-002 do not have a much higher quality than a random baseline: up to 56%. The more advanced 11B Tk-Instruct is not much better at 61.6%.
Due to the poor quality of this approach, an alternative was put together that considers the average negative log-likelihood (NLL) of the question in combination with the preceding paragraph of text and then ranks the results. Evaluated on a dataset where for each question, there were 100 paragraphs, and only one was relevant (so random guessing gives 1%). We got top-1 accuracy at 79% and top-5 at 93%. For this calculation, you usually need access to the model itself, which is not always done in the API.
Next comes the stage of building output chains. This is done through a search through a tree where the question is the root, and at each level, there are many paragraphs with possible evidence used as context to generate the next step. Each path through the tree is a potential output chain. It is unrealistic to draw a conclusion on all possible chains, so all available chains are ranked, and the highest-ranking chain is expanded. This is such a variation of beam search. The process stops when a response is made or the maximum allowed number of steps has passed.
The most important details are the two ranking strategies tested for the tree search step. The first strategy is based on the average NLL of the entire chain, while the second strategy looks at the average difference in NLL with and without a paragraph (P), with and without question (Q). On the available 918 questions from StrategyQA, this approach significantly improves the answer quality relative to the baseline with CoT (60%); both search options give around 66% (the strategy with a slightly higher delta). If golden facts are submitted, the quality becomes around 81%, which is the upper limit for OPT. Darklang seems to be going there somewhere but in a slightly different way.
The article is based on the Telegram post.
Read more about AI:
Disclaimer
In line with the Trust Project guidelines, please note that the information provided on this page is not intended to be and should not be interpreted as legal, tax, investment, financial, or any other form of advice. It is important to only invest what you can afford to lose and to seek independent financial advice if you have any doubts. For further information, we suggest referring to the terms and conditions as well as the help and support pages provided by the issuer or advertiser. MetaversePost is committed to accurate, unbiased reporting, but market conditions are subject to change without notice.
About The Author
Damir is the team leader, product manager, and editor at Metaverse Post, covering topics such as AI/ML, AGI, LLMs, Metaverse, and Web3-related fields. His articles attract a massive audience of over a million users every month. He appears to be an expert with 10 years of experience in SEO and digital marketing. Damir has been mentioned in Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto, and other publications. He travels between the UAE, Turkey, Russia, and the CIS as a digital nomad. Damir earned a bachelor's degree in physics, which he believes has given him the critical thinking skills needed to be successful in the ever-changing landscape of the internet.
More articles
Damir is the team leader, product manager, and editor at Metaverse Post, covering topics such as AI/ML, AGI, LLMs, Metaverse, and Web3-related fields. His articles attract a massive audience of over a million users every month. He appears to be an expert with 10 years of experience in SEO and digital marketing. Damir has been mentioned in Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto, and other publications. He travels between the UAE, Turkey, Russia, and the CIS as a digital nomad. Damir earned a bachelor's degree in physics, which he believes has given him the critical thinking skills needed to be successful in the ever-changing landscape of the internet.





