







































Top 30+ Transformer Models in AI: What They Are and How They Work







In recent months, numerous Transformer models have emerged in AI, each with unique and sometimes amusing names. However, these names might not provide much insight into what these models actually do. This article aims to provide a comprehensive and straightforward list of the most popular Transformer models. It will classify these models and also introduce important aspects and innovations within the Transformer family. The top list will cover models trained through self-supervised learning, like BERT or GPT-3, as well as models that undergo additional training with human involvement, such as the InstructGPT model utilized by ChatGPT.

| Pro Tips |
|---|
| This guide is designed to provide comprehensive knowledge and practical skills in prompt engineering for beginners to advanced learners. |
| There are many courses available for individuals who want to learn more about AI and its related technologies. |
| Take a look at the top 10+ AI accelerators that are expected to lead the market in terms of performance. |
What are Transformers in AI?
Transformers are a type of deep learning models that were introduced in a research paper called “Attention is All you Need” by Google researchers in 2017. This paper has gained immense recognition, accumulating over 38,000 citations in just five years.
The original Transformer architecture is a specific form of encoder-decoder models that had gained popularity prior to its introduction. These models predominantly relied on LSTM and other variations of Recurrent Neural Networks (RNNs), with attention being just one of the mechanisms utilized. However, the Transformer paper proposed a revolutionary idea that attention could serve as the sole mechanism to establish dependencies between input and output.
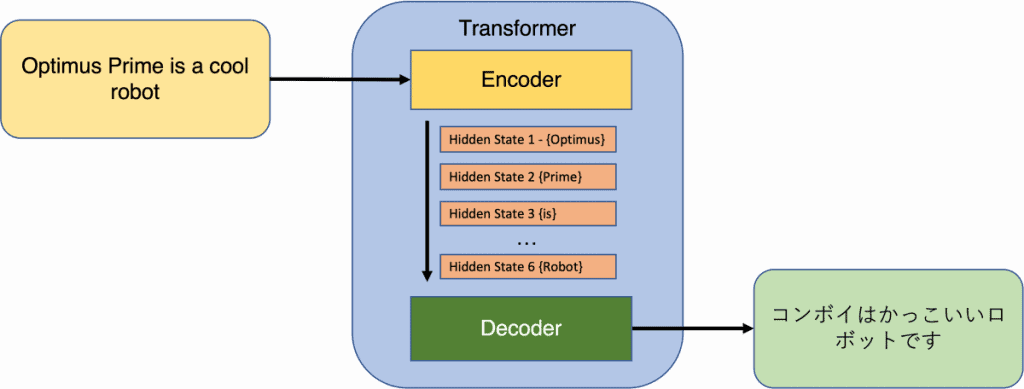
In the context of Transformers, the input consists of a sequence of tokens, which can be words or subwords in natural language processing (NLP). Subwords are commonly employed in NLP models to address the issue of out-of-vocabulary words. The output of the encoder produces a fixed-dimensional representation for each token, along with a separate embedding for the entire sequence. The decoder takes the encoder’s output and generates a sequence of tokens as its output.
Since the publication of the Transformer paper, popular models like BERT and GPT have adopted aspects of the original architecture, either using the encoder or decoder components. The key similarity between these models lies in the layer architecture, which incorporates self-attention mechanisms and feed-forward layers. In Transformers, each input token traverses its own path through the layers while maintaining direct dependencies with every other token in the input sequence. This unique feature allows for parallel and efficient computation of contextual token representations, a capability not feasible with sequential models like RNNs.

While this article only scratches the surface of the Transformer architecture, it provides a glimpse into its fundamental aspects. For a more comprehensive understanding, we recommend referring to the original research paper or The Illustrated Transformer post.
What are Encoders and Decoders in AI?
Imagine you have two models, an encoder and a decoder, working together like a team. The encoder takes an input and turns it into a fixed-length vector. Then, the decoder takes that vector and transforms it into an output sequence. These models are trained together to make sure the output matches the input as closely as possible.
Both the encoder and decoder had several layers. Each layer in the encoder had two sub layers: a multi-head self-attention layer and a simple feed forward network. The self-attention layer helps each token in the input understand the relationships with all the other tokens. These sublayers also have a residual connection and a layer normalization to make the learning process smoother.
The decoder’s multi-head self-attention layer works a bit differently from the one in the encoder. It masks the tokens to the right of the token it’s focusing on. This ensures that the decoder only looks at the tokens that come before the one it’s trying to predict. This masked multi-head attention helps the decoder generate accurate predictions. Additionally, the decoder includes another sublayer, which is a multi-head attention layer over all the outputs from the encoder.
It’s important to note that these specific details have been modified in different variations of the Transformer model. Models like BERT and GPT, for example, are based on either the encoder or decoder aspect of the original architecture.
What are Attention Layers in AI?
In the model architecture we discussed earlier, the multi-head attention layers are the special elements that make it powerful. But what exactly is attention? Think of it as a function that maps a question to a set of information and gives an output. Each token in the input has a query, key, and value associated with it. The output representation of each token is calculated by taking a weighted sum of the values, where the weight for each value is determined by how well it matches the query.
Transformers use a compatibility function called scaled dot product to compute these weights. The interesting thing about attention in Transformers is that each token goes through its own calculation path, allowing for parallel computation of all the tokens in the input sequence. It’s simply multiple attention blocks that independently calculate representations for each token. These representations are then combined to create the final representation of the token.
Compared to other types of networks like recurrent and convolutional networks, attention layers have a few advantages. They are computationally efficient, meaning they can process information quickly. They also have higher connectivity, which is helpful for capturing long-term relationships in sequences.
What are Fine-tuned Models in AI?
Foundation models are powerful models that are trained on a large amount of general data. They can then be adapted or fine-tuned for specific tasks by training them on a smaller set of target-specific data. This approach, popularized by the BERT paper, has led to the dominance of Transformer-based models in language-related machine learning tasks.
In the case of models like BERT, they produce representations of input tokens but don’t accomplish specific tasks on their own. To make them useful, additional neural layers are added on top and the model is trained end-to-end, a process known as fine-tuning. However, with generative models like GPT, the approach is slightly different. GPT is a decoder language model trained to predict the next word in a sentence. By training on vast amounts of web data, GPT can generate reasonable outputs based on input queries or prompts.
To make GPT more helpful, OpenAI researchers developed InstructGPT, which is trained to follow human instructions. This is achieved by fine-tuning GPT using human-labeled data from various tasks. InstructGPT is capable of performing a wide range of tasks and is used by popular engines like ChatGPT.
Fine-tuning can also be used to create variants of foundation models optimized for specific purposes beyond language modeling. For example, there are models fine-tuned for semantic-related tasks like text classification and search retrieval. Additionally, transformer encoders have been successfully fine-tuned within multi-task learning frameworks to perform multiple semantic tasks using a single shared model.
Today, fine-tuning is used to create versions of foundation models that can be used by a large number of users. The process involves generating responses to input prompts and having humans rank the results. This ranking is used to train a reward model, which assigns scores to each output. Reinforcement learning with human feedback is then employed to further train the model.
Why are Transformers the future of AI?
Transformers, a type of powerful model, were first demonstrated in the field of language translation. However, researchers quickly realized that Transformers could be used for various language-related tasks by training them on a large amount of unlabeled text and then fine-tuning them on a smaller set of labeled data. This approach allowed Transformers to capture significant knowledge about language.
The Transformer architecture, originally designed for language tasks, has also been applied to other applications like generating images, audio, music, and even actions. This has made Transformers a key component in the field of Generative AI, which is change various aspects of society.
The availability of tools and frameworks such as PyTorch and TensorFlow has played a crucial role in the widespread adoption of Transformer models. Companies like Huggingface have built their business around the idea of commercializing open-source Transformer libraries, and specialized hardware like NVIDIA’s Hopper Tensor Cores has further accelerated the training and inference speed of these models.
One notable application of Transformers is ChatGPT, a chatbot released by OpenAI. It became incredibly popular, reaching millions of users in a short period. OpenAI has also announced the release of GPT-4, a more powerful version capable of achieving human-like performance in tasks such as medical and legal exams.
The impact of Transformers in the field of AI and their wide range of applications is undeniable. They have transformed the way we approach language-related tasks and are paving the way for new advancements in generative AI.
3 Types of Pretraining Architectures
The Transformer architecture, originally consisting of an Encoder and a Decoder, has evolved to include different variations based on specific needs. Let’s break down these variations in simple terms.
- Encoder Pretraining: These models focus on understanding complete sentences or passages. During pretraining, the encoder is used to reconstruct masked tokens in the input sentence. This helps the model learn to understand the overall context. Such models are useful for tasks like text classification, entailment, and extractive question answering.
- Decoder Pretraining: Decoder models are trained to generate the next token based on the previous sequence of tokens. They are known as auto-regressive language models. The self-attention layers in the decoder can only access tokens before a given token in the sentence. These models are ideal for tasks involving text generation.
- Transformer (Encoder-Decoder) Pretraining: This variation combines both the encoder and decoder components. The encoder’s self-attention layers can access all input tokens, while the decoder’s self-attention layers can only access tokens before a given token. This architecture enables the decoder to use the representations learned by the encoder. Encoder-decoder models are well-suited for tasks like summarization, translation, or generative question answering.
Pretraining objectives can involve denoising or causal language modeling. These objectives are more complex for encoder-decoder models compared to encoder-only or decoder-only models. The Transformer architecture has different variations depending on the focus of the model. Whether it’s understanding complete sentences, generating text, or combining both for various tasks, Transformers offer flexibility in addressing different language-related challenges.
8 Types of Tasks for Pre-trained Models
When training a model, we need to give it a task or objective to learn from. There are various tasks in natural language processing (NLP) that can be used for pretraining models. Let’s break down some of these tasks in simple terms:
- Language Modeling (LM): The model predicts the next token in a sentence. It learns to understand the context and generate coherent sentences.
- Causal Language Modeling: The model predicts the next token in a text sequence, following a left-to-right order. It’s like a storytelling model that generates sentences one word at a time.
- Prefix Language Modeling: The model separates a ‘prefix’ section from the main sequence. It can attend to any token within the prefix, and then generates the rest of the sequence autoregressively.
- Masked Language Modeling (MLM): Some tokens in the input sentences are masked, and the model predicts the missing tokens based on the surrounding context. It learns to fill in the blanks.
- Permuted Language Modeling (PLM): The model predicts the next token based on a random permutation of the input sequence. It learns to handle different orders of tokens.
- Denoising Autoencoder (DAE): The model takes a partially corrupted input and aims to recover the original, undistorted input. It learns to handle noise or missing parts of the text.
- Replaced Token Detection (RTD): The model detects whether a token comes from the original text or a generated version. It learns to identify replaced or manipulated tokens.
- Next Sentence Prediction (NSP): The model learns to distinguish whether two input sentences are continuous segments from the training data. It understands the relationship between sentences.
These tasks help the model learn the structure and meaning of language. By pretraining on these tasks, models gain a good understanding of language before being fine-tuned for specific applications.
Top 30+ Transformers in AI
| Name | Pretraining Architecture | Task | Application | Developed by |
|---|---|---|---|---|
| ALBERT | Encoder | MLM/NSP | Same as BERT | |
| Alpaca | Decoder | LM | Text generation and classification tasks | Stanford |
| AlphaFold | Encoder | Protein folding prediction | Protein folding | Deepmind |
| Anthropic Assistant (see also) | Decoder | LM | From general dialog to code assistant. | Anthropic |
| BART | Encoder/Decoder | DAE | Text generation and text understanding tasks | |
| BERT | Encoder | MLM/NSP | Language Understanding and Question Answering | |
| BlenderBot 3 | Decoder | LM | Text generation and text understanding tasks | |
| BLOOM | Decoder | LM | Text generation and text understanding tasks | Big Science/Huggingface |
| ChatGPT | Decoder | LM | Dialog agents | OpenAI |
| Chinchilla | Decoder | LM | Text generation and text understanding tasks | Deepmind |
| CLIP | Encoder | Image/Object classification | OpenAI | |
| CTRL | Decoder | Controllable text generation | Salesforce | |
| DALL-E | Decoder | Caption prediction | Text to image | OpenAI |
| DALL-E-2 | Encoder/Decoder | Caption prediction | Text to image | OpenAI |
| DeBERTa | Decoder | MLM | Same as BERT | Microsoft |
| Decision Transformers | Decoder | Next action prediction | General RL (reinforcement learning tasks) | Google/UC Berkeley/FAIR |
| DialoGPT | Decoder | LM | Text generation in dialog settings | Microsoft |
| DistilBERT | Encoder | MLM/NSP | Language Understanding and Question Answering | Huggingface |
| DQ-BART | Encoder/Decoder | DAE | Text generation and understanding | Amazon |
| Dolly | Decoder | LM | Text generation and classification tasks | Databricks, Inc |
| ERNIE | Encoder | MLM | Knowledge intensive related tasks | Various Chinese institutions |
| Flamingo | Decoder | Caption prediction | Text to image | Deepmind |
| Galactica | Decoder | LM | Scientific QA, mathematical reasoning, summarization, document generation, molecular property prediction and entity extraction. | Meta |
| GLIDE | Encoder | Caption prediction | Text to image | OpenAI |
| GPT-3.5 | Decoder | LM | Dialog and general language | OpenAI |
| GPTInstruct | Decoder | LM | Knowledge-intensive dialog or language tasks | OpenAI |
| HTML | Encoder/Decoder | DAE | Language model that allows structured HTML prompting | |
| Imagen | T5 | Caption prediction | Text to image | |
| LAMDA | Decoder | LM | General language modeling | |
| LLaMA | Decoder | LM | Commonsense reasoning, Question answering, Code generation and Reading comprehension. | Meta |
| Minerva | Decoder | LM | Mathematical reasoning | |
| Palm | Decoder | LM | Language understanding and generation | |
| RoBERTa | Encoder | MLM | Language Understanding and Question Answering | UW/Google |
| Sparrow | Decoder | LM | Dialog agents and general language generation applications like Q&A | Deepmind |
| StableDiffusion | Encoder/Decoder | Caption Prediction | Text to image | LMU Munich + Stability.ai + Eleuther.ai |
| Vicuna | Decoder | LM | Dialog agents | UC Berkeley, CMU, Stanford, UC San Diego, and MBZUAI |
FAQs
Transformers in AI are a type of deep learning architecture that has changed natural language processing and other tasks. They use self-attention mechanisms to capture relationships between words in a sentence, enabling them to understand and generate human-like text.
Encoders and decoders are components commonly used in sequence-to-sequence models. Encoders process input data, such as text or images, and convert it into a compressed representation, while decoders generate output data based on the encoded representation, enabling tasks like language translation or image captioning.
Attention layers are components used in neural networks, particularly in Transformer models. They enable the model to selectively focus on different parts of the input sequence, assigning weights to each element based on its relevance, allowing for capturing dependencies and relationships between elements effectively.
Fine-tuned models refer to pre-trained models that have been further trained on a specific task or dataset to improve their performance and adapt them to the specific requirements of that task. This fine-tuning process involves adjusting the parameters of the model to optimize its predictions and make it more specialized for the target task.
Transformers are considered the future of AI because they have demonstrated exceptional performance in a wide range of tasks, including natural language processing, image generation, and more. Their ability to capture long-range dependencies and process sequential data efficiently makes them highly adaptable and effective for various applications, paving the way for advancements in generative AI and revolutionizing many aspects of society.
The most famous transformer models in AI include BERT (Bidirectional Encoder Representations from Transformers), GPT (Generative Pre-trained Transformer), and T5 (Text-to-Text Transfer Transformer). These models have achieved remarkable results in various natural language processing tasks and have gained significant popularity in the AI research community.
Read more about AI:
Disclaimer
In line with the Trust Project guidelines, please note that the information provided on this page is not intended to be and should not be interpreted as legal, tax, investment, financial, or any other form of advice. It is important to only invest what you can afford to lose and to seek independent financial advice if you have any doubts. For further information, we suggest referring to the terms and conditions as well as the help and support pages provided by the issuer or advertiser. MetaversePost is committed to accurate, unbiased reporting, but market conditions are subject to change without notice.
About The Author
Damir is the team leader, product manager, and editor at Metaverse Post, covering topics such as AI/ML, AGI, LLMs, Metaverse, and Web3-related fields. His articles attract a massive audience of over a million users every month. He appears to be an expert with 10 years of experience in SEO and digital marketing. Damir has been mentioned in Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto, and other publications. He travels between the UAE, Turkey, Russia, and the CIS as a digital nomad. Damir earned a bachelor's degree in physics, which he believes has given him the critical thinking skills needed to be successful in the ever-changing landscape of the internet.
More articles
Damir is the team leader, product manager, and editor at Metaverse Post, covering topics such as AI/ML, AGI, LLMs, Metaverse, and Web3-related fields. His articles attract a massive audience of over a million users every month. He appears to be an expert with 10 years of experience in SEO and digital marketing. Damir has been mentioned in Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto, and other publications. He travels between the UAE, Turkey, Russia, and the CIS as a digital nomad. Damir earned a bachelor's degree in physics, which he believes has given him the critical thinking skills needed to be successful in the ever-changing landscape of the internet.





