







































GPT-4 Inherits “Hallucinating” Facts and Reasoning Errors From Earlier GPT Models






In Brief
OpenAI says GPT-4 has similar limitations as earlier GPT models.
GPT-4 still hallucinates facts and makes reasoning errors.
However, GPT-4 scores 40% higher than OpenAI’s latest GPT-3.5 on the company’s internal adversarial factuality evaluations.

OpenAI has warned users that its latest language model, GPT-4, is still not fully reliable and can “hallucinate” facts and make reasoning errors. The company urges users to exercise caution when using language model outputs, especially in “high-stakes contexts.”
However, the good news is that GPT-4 significantly reduces hallucinations relative to previous models. OpenAI claims that GPT-4 scores 40% higher than the latest GPT-3.5 on internal adversarial factuality evaluations.
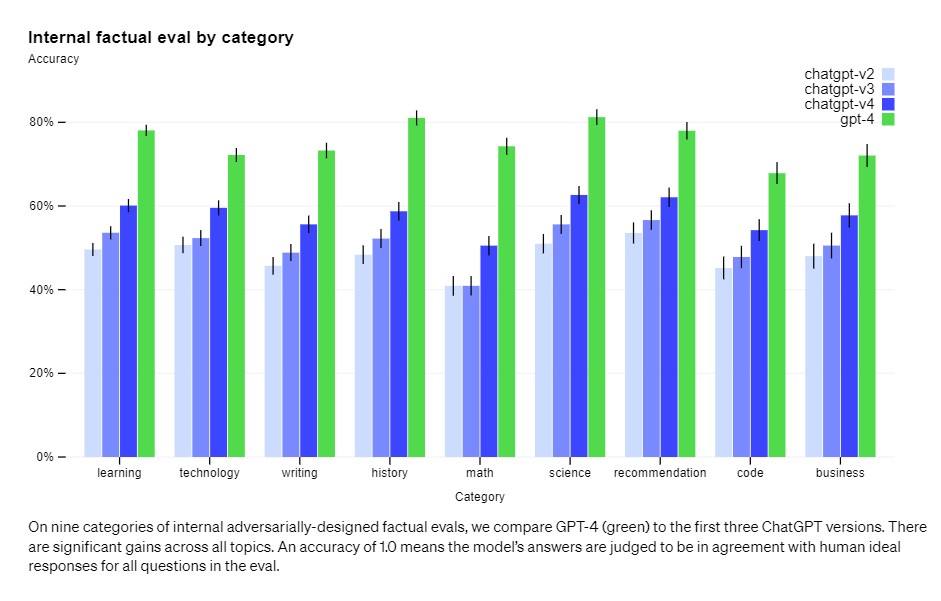
“We have made progress on external benchmarks like TruthfulQA, which tests the model’s ability to separate fact from an adversarially-selected set of incorrect statements. These questions are paired with factually incorrect answers that are statistically appealing,” OpenAI wrote in a blog post.
Despite this improvement, the model still lacks knowledge of events that occurred after September 2021 and sometimes makes simple reasoning errors, just like earlier models do. Additionally, it can be overly gullible in accepting obvious false statements from users and fail at hard problems, such as introducing security vulnerabilities into its code. It also does not fact-check the information it provides.
Like its predecessors, GPT-4 can generate harmful advice, buggy code, or inaccurate information. However, the model’s additional capabilities lead to new risk surfaces that need to be understood. To assess the extent of these risks, over 50 experts from various domains, including AI alignment risks, cybersecurity, biorisk, trust and safety, and international security, were engaged to adversarially test the model. Their feedback and data were then used to improve the model, such as collecting additional data to enhance GPT-4’s ability to refuse requests on how to synthesize dangerous chemicals.

One of the main ways OpenAI is reducing harmful outputs is by incorporating an additional safety reward signal during RLHF (Reinforcement Learning from Human Feedback) training. The signal trains the model to refuse requests for harmful content, as defined by the model’s usage guidelines. The reward is provided by a GPT-4 zero-shot classifier, which judges safety boundaries and completion style on safety-related prompts.
OpenAI also said that it had decreased the model’s tendency to respond to requests for disallowed content by 82% compared to GPT-3.5, and GPT-4 responds to sensitive requests such as medical advice and self-harm in accordance with the company’s policies 29% more often.
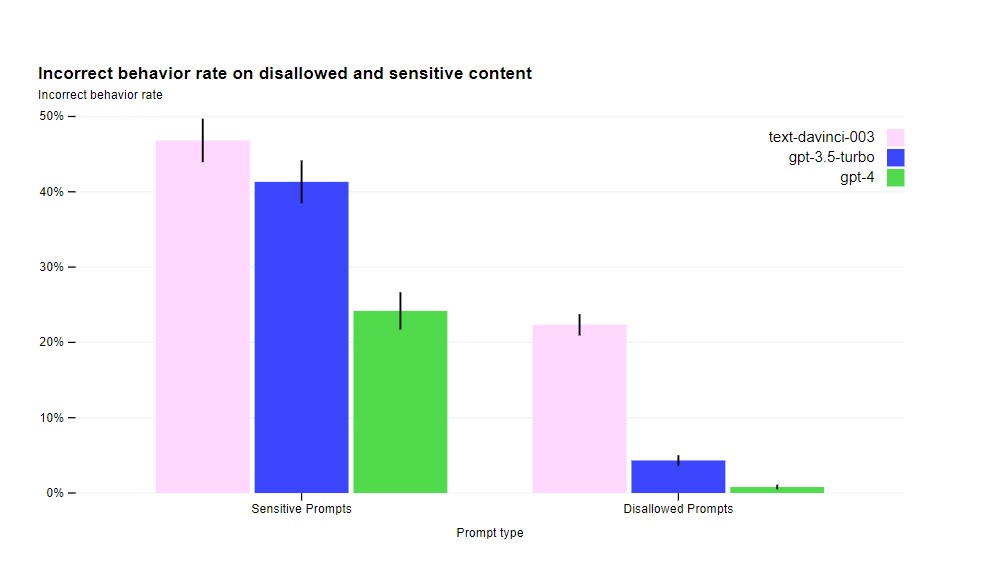
While OpenAI’s interventions have increased the difficulty of eliciting bad behavior from GPT-4, it is still possible, and there are still jailbreaks that can generate content that violates usage guidelines.
“As AI systems become more prevalent, achieving high degrees of reliability in these interventions will become increasingly critical. For now, it’s essential to complement these limitations with deployment-time safety techniques like monitoring for abuse,” the company added.
OpenAI is collaborating with external researchers to better understand and assess the potential impacts of GPT-4 and its successor models. The team is also developing evaluations for dangerous capabilities that may emerge in future AI systems. As they continue to study the potential social and economic impacts of GPT-4 and other AI systems, OpenAI will share their findings and insights with the public in due time.
Read more:
Disclaimer
In line with the Trust Project guidelines, please note that the information provided on this page is not intended to be and should not be interpreted as legal, tax, investment, financial, or any other form of advice. It is important to only invest what you can afford to lose and to seek independent financial advice if you have any doubts. For further information, we suggest referring to the terms and conditions as well as the help and support pages provided by the issuer or advertiser. MetaversePost is committed to accurate, unbiased reporting, but market conditions are subject to change without notice.
About The Author
Cindy is a journalist at Metaverse Post, covering topics related to web3, NFT, metaverse and AI, with a focus on interviews with Web3 industry players. She has spoken to over 30 C-level execs and counting, bringing their valuable insights to readers. Originally from Singapore, Cindy is now based in Tbilisi, Georgia. She holds a Bachelor's degree in Communications & Media Studies from the University of South Australia and has a decade of experience in journalism and writing. Get in touch with her via [email protected] with press pitches, announcements and interview opportunities.
More articles
Cindy is a journalist at Metaverse Post, covering topics related to web3, NFT, metaverse and AI, with a focus on interviews with Web3 industry players. She has spoken to over 30 C-level execs and counting, bringing their valuable insights to readers. Originally from Singapore, Cindy is now based in Tbilisi, Georgia. She holds a Bachelor's degree in Communications & Media Studies from the University of South Australia and has a decade of experience in journalism and writing. Get in touch with her via [email protected] with press pitches, announcements and interview opportunities.




