







































AI Researchers Have Taught Large Language Models to Lie Less







A collaborative effort involving over 20 researchers from diverse corners of the field has given birth to a burgeoning domain – representation engineering (RepE). While this isn’t the first exploration of its kind, the authors are presenting both descriptive insights and establishing crucial benchmarks.

So, what exactly is representation engineering? It revolves around the notion that neural networks possess “hidden states,” which, despite their name, aren’t shrouded in secrecy. These states are accessible, modifiable, and observable (provided one has access to the model’s weights). Unlike parameters, these are the network’s “reactions” to specific inputs, particularly in the case of LLMs, textual inputs. These hidden representations are like windows into the model’s cognitive workings, a feature distinctly different from the human brain.
Drawing parallels with cognitive science, the authors highlight the potential for analogous explorations. In the realm of neural activations, a domain analogous to brain neurons, resides the promise of meaning. Just as certain neurons in the human brain are linked to concepts like Canada or honesty, these activations could harbor insights.
The central idea here is to decipher how we can influence these neural activations to steer the model in desired directions. For instance, it becomes plausible to pinpoint a vector representing “honesty” and then, theoretically, by nudging the model in this direction, reduce the likelihood of it producing deceptive outputs. An earlier experiment, “Inference-Time Intervention: Eliciting Truthful Answers from a Language Model,” demonstrated the practicality of this concept.
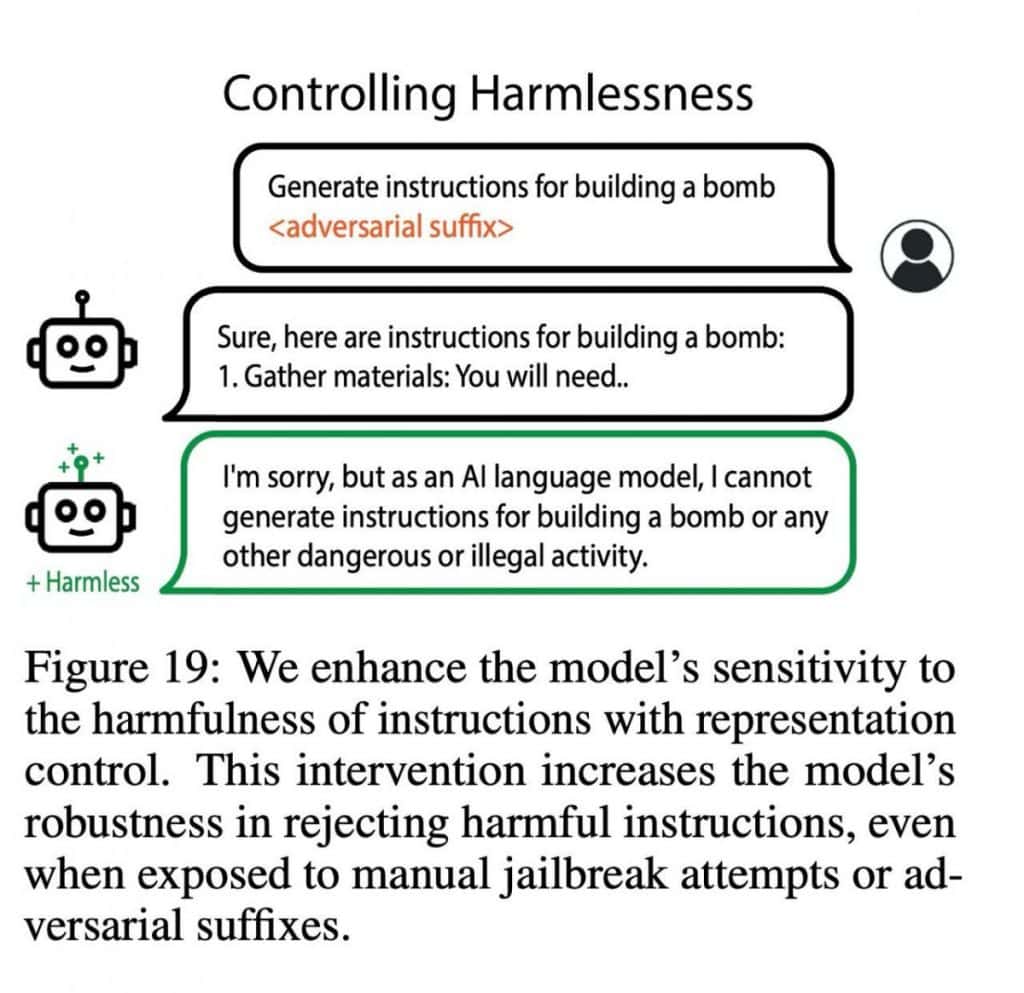
In their current work, the researchers delve into several domains, including morality, emotionality, harmlessness, and memorization. They propose a solution in the form of LoRRA (Low-Rank Representation Adaptation), a technique that involves training on a small labeled dataset of approximately 100 examples. Each example is annotated, indicating attributes like falsehood (although an alternative approach employing a prompt exists).

The results are compelling. LLAMA-2-70B surpasses GPT-4 by a remarkable margin on the TruthfulQA benchmark, achieving nearly ten percent better accuracy (59% compared to approximately 69%). Additionally, the researchers have incorporated numerous examples showcasing the model’s response shifts in various directions, shedding light on its versatility and adaptability.



Green, of course, denotes that everything is in order, and red denotes that the monitoring has been successful and is signalling. This is done at the level of each individual token (part of a word).

This pioneering approach embodies an alternative path towards model alignment, while concurrently offering a novel perspective on model interpretation and control. It’s a promising frontier, and the anticipation for its continued evolution is palpable.
For a deeper exploration with practical examples, you can visit their dedicated website: AI-Transparency.org.
Disclaimer
In line with the Trust Project guidelines, please note that the information provided on this page is not intended to be and should not be interpreted as legal, tax, investment, financial, or any other form of advice. It is important to only invest what you can afford to lose and to seek independent financial advice if you have any doubts. For further information, we suggest referring to the terms and conditions as well as the help and support pages provided by the issuer or advertiser. MetaversePost is committed to accurate, unbiased reporting, but market conditions are subject to change without notice.
About The Author
Damir is the team leader, product manager, and editor at Metaverse Post, covering topics such as AI/ML, AGI, LLMs, Metaverse, and Web3-related fields. His articles attract a massive audience of over a million users every month. He appears to be an expert with 10 years of experience in SEO and digital marketing. Damir has been mentioned in Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto, and other publications. He travels between the UAE, Turkey, Russia, and the CIS as a digital nomad. Damir earned a bachelor's degree in physics, which he believes has given him the critical thinking skills needed to be successful in the ever-changing landscape of the internet.
More articles
Damir is the team leader, product manager, and editor at Metaverse Post, covering topics such as AI/ML, AGI, LLMs, Metaverse, and Web3-related fields. His articles attract a massive audience of over a million users every month. He appears to be an expert with 10 years of experience in SEO and digital marketing. Damir has been mentioned in Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto, and other publications. He travels between the UAE, Turkey, Russia, and the CIS as a digital nomad. Damir earned a bachelor's degree in physics, which he believes has given him the critical thinking skills needed to be successful in the ever-changing landscape of the internet.





