







































GPT-4 Outperforms GPT-3.5 Across the Board on a Variety of Study Benchmarks






In Brief
The GPT-4 has achieved a higher grade threshold than the GPT-3.5 on a variety of benchmarks.
This is a major achievement as it shows that machines are not only capable of human-like intelligence but can also outperform us, which raises questions about the future of AI and its potential impact on the job market.
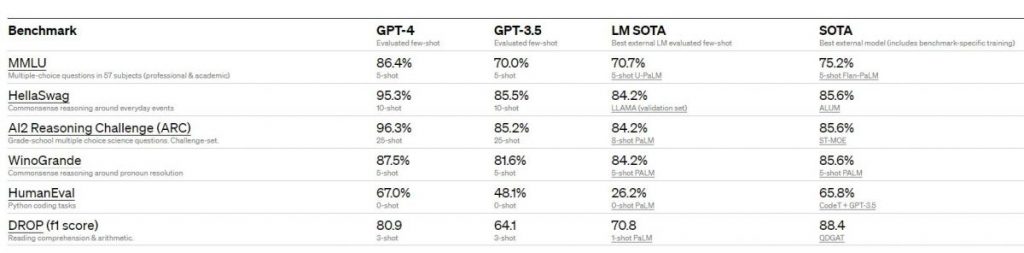
GPT-4 is significantly outperformed by state-of-the-art (SOTA) models, including those that use additional training protocols or benchmark-specific design, as well as existing big language models.
The GPT-4 has achieved higher scores than the GPT-3.5 on a variety of benchmarks. This is a major breakthrough for machines as it proves that they can now not only solve problems that are originally designed for but can also do so better than university students.

There are a few things to take into consideration when looking at this result. Firstly, the GPT-4 was not given any specific training for these exams. It proceeded by using the most recent publicly-available tests (in the case of the Olympiads and AP free response questions) or by purchasing 2022–2023 editions of practice exams. Secondly, it is important to note that the GPT-4’s performance may not necessarily reflect the abilities of human test-takers, as it operates on a different set of principles and algorithms.
This is a major achievement as it shows that machines are not only capable of human-like intelligence but can also outperform us. This paves the way for a future where machines can take on more and more complex tasks, ultimately leading to a future in which they can assist us in our everyday lives.
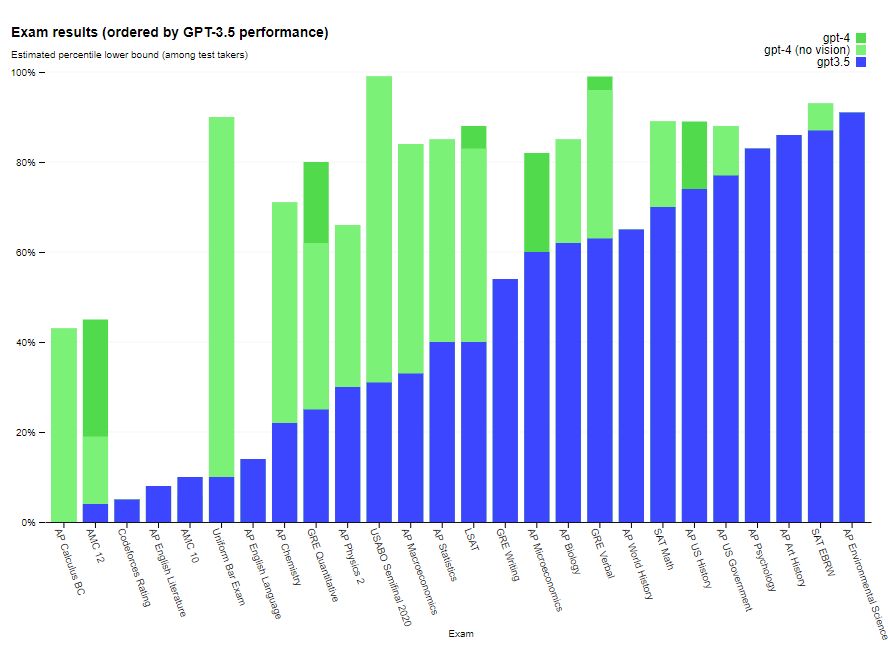
GPT-4, for example, passes a simulated bar exam with a score in the top 10% of test takers; GPT-3.5’s score was in the bottom 10%. This significant improvement in GPT-4’s performance is due to its larger training data and improved architecture. It is expected to have a wide range of applications in various fields, including natural language processing and automated writing.
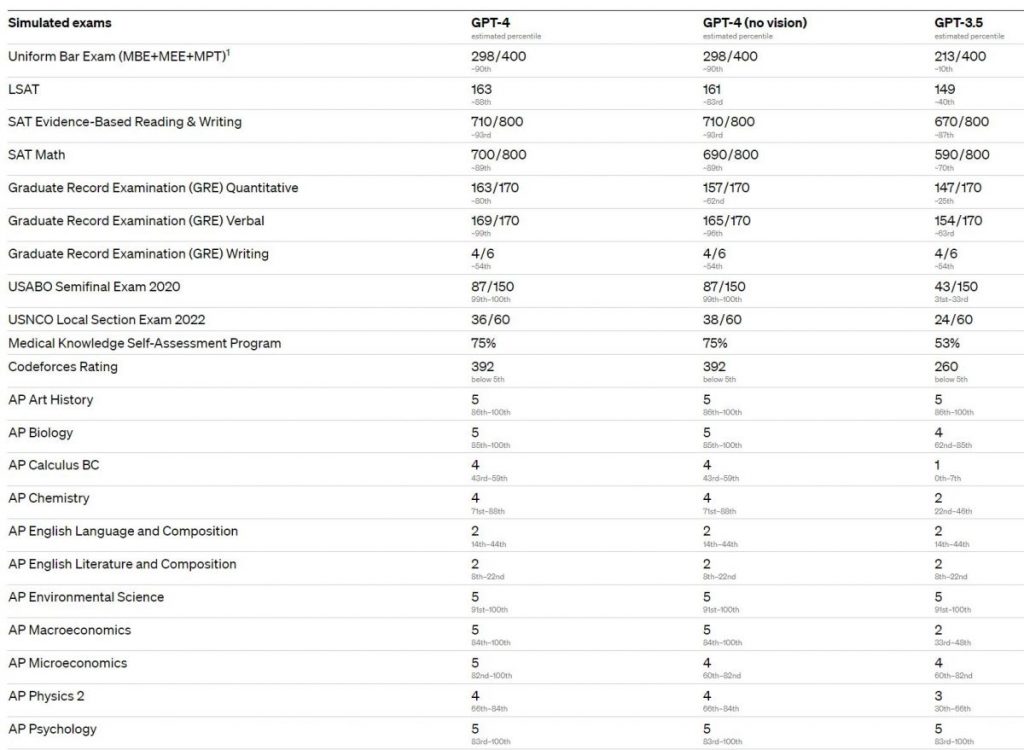
GPT-4 exhibits human-level performance on the majority of these professional and academic exams. Notably, it passed a simulated version of the Uniform Bar Examination with a score in the top 10% of test takers. The model’s capabilities on exams appear to stem primarily from the pre-training process and are not significantly affected by RLHF. On multiple-choice questions, both the base GPT-4 model and the RLHF model performed equally well on average across the developers of the exam tested.
The majority of state-of-the-art (SOTA) models, including those that may use additional training protocols or benchmark-specific design, as well as existing big language models, are significantly outperformed by GPT-4.

Internally, developers have been utilizing GPT-4, which has had a significant impact on activities like programming, sales, support, and content moderation. The second stage of our alignment method is now underway as developers use it to aid humans in reviewing AI outcomes.
MMLU (Massive Multi-Task Language Understanding) dataset contains questions from a very wide range of topics on language understanding in different tasks (spanning 57 domains, including mathematics, biology, law, social and human sciences, etc.). There are four possible answers to the question, one of which is correct. That is, random guessing shows a result of 25% correct answers. See the picture below for examples of questions and their difficulties. The average person-marker (that is, this is not a scientist, not a professor—an ordinary person who moonlights as a markup) answers correctly to 35% of the questions; however, the experts can reach a score of +/- 90%.
| Read more: 5 Reasons to Use AI-Powered Bing Over Google |
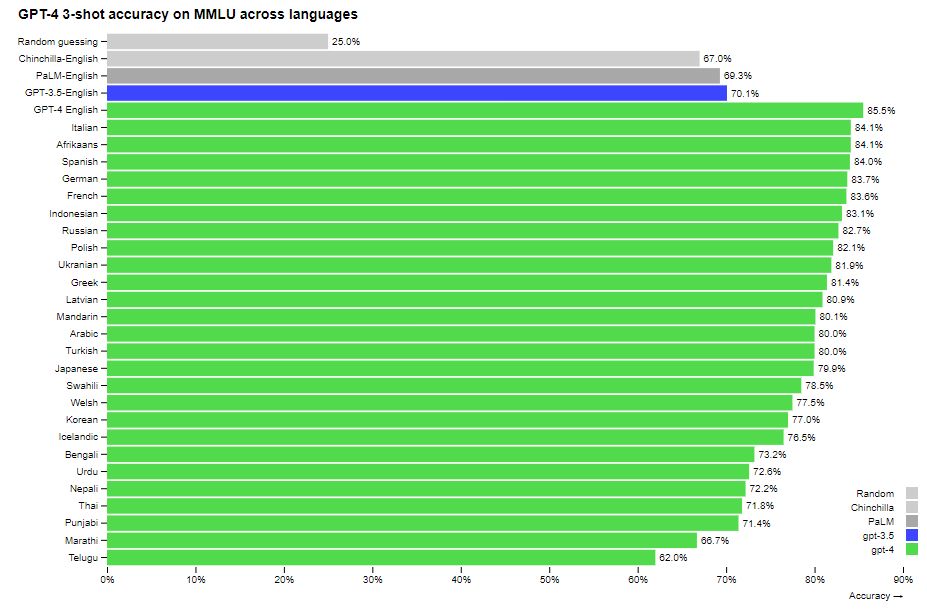
Originally, the entire dataset was in English. But what if questions and answers are translated into other languages, especially less common ones? Will the model work for them somehow? In this test, the Microsoft Azure Translate service was used for translation. Translations are not perfect; in some cases, important information is lost. However, even in this case, the GPT-4 performs well in other languages. In the translated versions of the MMLU, GPT-4 outperforms the English level of other large models (including Google’s) by 24 of the 26 languages examined.
What’s more, GPT-4 performs better in rare languages than ChatGPT did in English (ChatGPT achieved a score of 70.1%, while the new model’s score for Thai was 71.8%). The score for the test in English was the highest, with GPT-4 performing 10% better than other models, including the largest PaLM from Google. It achieved a score of 86.4%, while a group of experts—90%.
- By the summer of 2023, AI might have reached a new level of power thanks to ChatGPT, a chatbot that uses the GPT-4 algorithm and outperforms GPT-3 by a factor of 570. A variety of elements contribute to ChatGPT’s success, including its design to be more “human-like” and its use of cutting-edge data mining and natural language processing to increase its effectiveness and accuracy.
- Microsoft and OpenAI announced their collaboration renewal and plans for Bing search to adopt AI-enhanced lookup capabilities in January. The very sophisticated GPT3.5 model’s replacement, GPT4, has just been launched, and it has the potential to greatly enhance Bing search’s capacity to comprehend natural language queries and deliver more accurate results. It is a good idea to have a good backup plan in case something goes wrong.
Read more related news:
Disclaimer
In line with the Trust Project guidelines, please note that the information provided on this page is not intended to be and should not be interpreted as legal, tax, investment, financial, or any other form of advice. It is important to only invest what you can afford to lose and to seek independent financial advice if you have any doubts. For further information, we suggest referring to the terms and conditions as well as the help and support pages provided by the issuer or advertiser. MetaversePost is committed to accurate, unbiased reporting, but market conditions are subject to change without notice.
About The Author
Damir is the team leader, product manager, and editor at Metaverse Post, covering topics such as AI/ML, AGI, LLMs, Metaverse, and Web3-related fields. His articles attract a massive audience of over a million users every month. He appears to be an expert with 10 years of experience in SEO and digital marketing. Damir has been mentioned in Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto, and other publications. He travels between the UAE, Turkey, Russia, and the CIS as a digital nomad. Damir earned a bachelor's degree in physics, which he believes has given him the critical thinking skills needed to be successful in the ever-changing landscape of the internet.
More articles
Damir is the team leader, product manager, and editor at Metaverse Post, covering topics such as AI/ML, AGI, LLMs, Metaverse, and Web3-related fields. His articles attract a massive audience of over a million users every month. He appears to be an expert with 10 years of experience in SEO and digital marketing. Damir has been mentioned in Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto, and other publications. He travels between the UAE, Turkey, Russia, and the CIS as a digital nomad. Damir earned a bachelor's degree in physics, which he believes has given him the critical thinking skills needed to be successful in the ever-changing landscape of the internet.





