







































Stability AI Releases a New Model Called SDXL Beta






In Brief
Stability AI has released a new model called SDXL Beta (Stable Diffusion XL Beta). It is a larger model with more parameters and some unknown enhancements. It is available at DreamStudio, Stability AI’s official image generator, and uses advanced algorithms and deep learning techniques to create stunning visuals.
Stability AI has unveiled a preview of a new model called SDXL Beta, short for Stable Diffusion XL Beta. So far, the company hasn’t shared a lot of information about the model, but it is available for testing for anyone who wants to do so. What is novel about this SDXL model for stable diffusion? What are its advantages and disadvantages? Let’s investigate.

| Read more: Midjourney and Dall-E Artist Styles Dump with Examples: 130 Famous AI Painting Techniques |
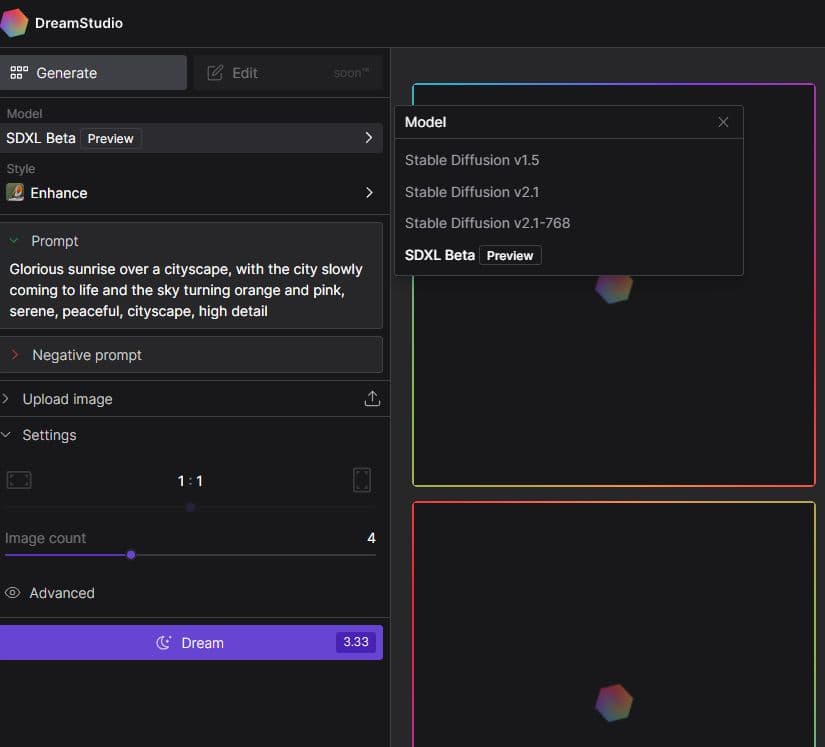
What exactly is the SDXL model?
The SDXL model is a new model that is currently being trained. It is far from being finished, and by the time it is released, a lot of details about it may change; for all we know, it may not even be called the SDXL model. All we know is that it is a larger model with more parameters and some unknown enhancements. It is a v2 model, not a v3 model (whatever that means). It is possible that the enhancements in the v2 model could improve the system’s performance, but without further information, it is difficult to determine how significant these improvements may be. Additionally, it would be helpful to know what specific parameters have been added or adjusted in this version.
The SDXL model is currently available at DreamStudio, Stability AI’s official image generator. Select SDXL Beta from the model menu to check it out. It seems to use advanced algorithms and deep learning techniques to create stunning visuals that are perfect for a wide range of applications.
Improvements
Legible text. SDXL is capable of generating legible text and it is probably its most striking feature as it wasn’t possible in the existing v1 and v2.1 models. SDXL’s generated text is not always accurate as you can see in the Stable Diffusion Text below. However, it is far superior to v2.1, let alone v1 model. This is because SDXLs uses a more advanced deep learning algorithm that allows it to understand and generate more complex language structures. With further development, it has the potential to become even more accurate and reliable.



Human anatomy. The accurate generation of anatomically correct human figures has long been a challenge for stable diffusion. The presence of additional or missing limbs is common. Inpainting is typically used to fix them, or, more recently, you can use ControlNet’s Open Pose feature to duplicate a pose from a reference image. We are glad to note that here is where the SDXL Beta model has improved. The SDXL Beta model has shown significant improvement in accurately duplicating poses from reference images. This can be a valuable tool for various applications such as animation and virtual reality.




Portrait style. SDXL Beta produces excellent portraits that look like photos – it is an upgrade compared to version 1.5. The improved algorithm in SDXL Beta enhances the details and color accuracy of the portraits, resulting in a more natural and realistic look. Users can also adjust the levels of sharpness and saturation to achieve their desired effects.



Duotone. The keyword duotone always produces black-and-white photos in the v1.5 model. However, now, the duotone images produced by SDXL Beta come in a variety of colors. It is clear that compared to v1 models, the ability to interpret the prompt has improved, resulting in more accurate and relevant responses from the v2 models, making them a more reliable tool for natural language processing tasks.



Artistic styles. There have been some minor adjustments, but it’s difficult to determine whether the new model provides better results as they are simply unique. It’s possible that these adjustments could be a matter of personal preference or subjective opinion, making it difficult to make a definitive judgment on their quality. Nonetheless, the uniqueness of the adjustments may be noteworthy and worth exploring further.




Conclusion
- Stable Diffusion can finally produce text that makes sense.
- SDXL provides more aesthetically pleasing images than the v2.1 and (to a lesser extent) the v1.5 models.
- The new model produces images that are more accurate.
- Human anatomy has improved.
- Negative prompts are not as necessary as in v2.1.
- It can create realistic portaits.
- Some oddities in the model will be fixed before release.
Read more related articles:
Disclaimer
In line with the Trust Project guidelines, please note that the information provided on this page is not intended to be and should not be interpreted as legal, tax, investment, financial, or any other form of advice. It is important to only invest what you can afford to lose and to seek independent financial advice if you have any doubts. For further information, we suggest referring to the terms and conditions as well as the help and support pages provided by the issuer or advertiser. MetaversePost is committed to accurate, unbiased reporting, but market conditions are subject to change without notice.
About The Author
Damir is the team leader, product manager, and editor at Metaverse Post, covering topics such as AI/ML, AGI, LLMs, Metaverse, and Web3-related fields. His articles attract a massive audience of over a million users every month. He appears to be an expert with 10 years of experience in SEO and digital marketing. Damir has been mentioned in Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto, and other publications. He travels between the UAE, Turkey, Russia, and the CIS as a digital nomad. Damir earned a bachelor's degree in physics, which he believes has given him the critical thinking skills needed to be successful in the ever-changing landscape of the internet.
More articles
Damir is the team leader, product manager, and editor at Metaverse Post, covering topics such as AI/ML, AGI, LLMs, Metaverse, and Web3-related fields. His articles attract a massive audience of over a million users every month. He appears to be an expert with 10 years of experience in SEO and digital marketing. Damir has been mentioned in Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto, and other publications. He travels between the UAE, Turkey, Russia, and the CIS as a digital nomad. Damir earned a bachelor's degree in physics, which he believes has given him the critical thinking skills needed to be successful in the ever-changing landscape of the internet.





