







































OpenFlamingo: A New Open-Source Image-to-Text Framework From Meta AI and LAION






In Brief
OpenFlamingo is an open-source version of DeepMind’s Flamingo model, built on top of the LLaMA large language model.
Developers hope to create a multimodal system that can handle vision-language challenges and equal GPT-4’s strength and adaptability in handling visual and text input.
The open-source version of DeepMind’s Flamingo model, OpenFlamingo, has just been released. OpenFlamingo is fundamentally a framework that permits the training and assessment of sizable multimodal models (LMMs). OpenFlamingo is built on top of the LLaMA large language model developed by Meta AI.

Developers’ contributions to this first release are as follows:
- A sizable multimodal dataset that combines text and visual sequences.
- A benchmark for in-context learning evaluation for activities including vision and language.
- A preliminary version of our LLaMA-based OpenFlamingo-9B model.
Through OpenFlamingo, developers hope to create a multimodal system that can handle a variety of vision-language challenges. The ultimate goal is to equal GPT-4’s strength and adaptability in handling visual and text input. Developers are developing an open-source version of DeepMind’s Flamingo model, an LMM capable of processing and reasoning about images, videos, and text, in order to accomplish this goal. Developers are dedicated to developing entirely open-source models because they think that transparency is crucial for promoting cooperation, accelerating development, and democratizing access to cutting-edge LMMs.
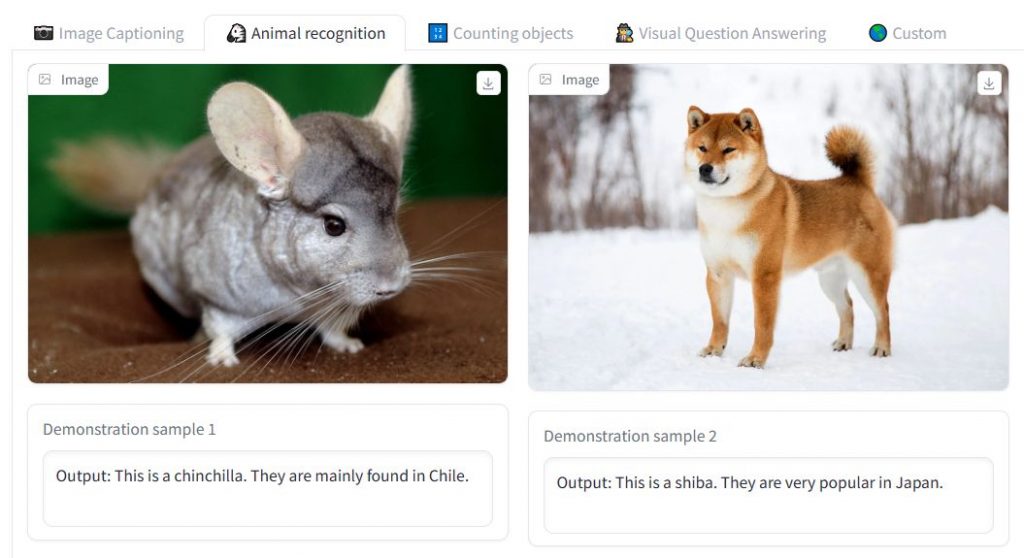
They are providing our OpenFlamingo-9B model’s initial checkpoint. Although the model is not yet entirely optimized, it shows the project’s promise. Developers can train better LMMs by cooperating and getting community feedback. They invite the public to give input and add to the repository in order to take part in the development process.
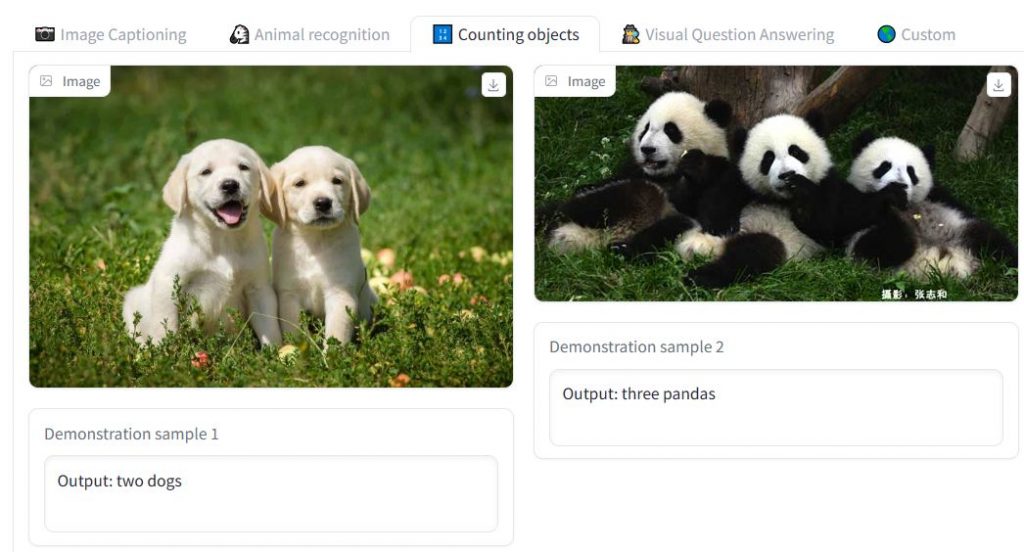
The implementation closely resembles that of Flamingo’s. Flamingo models must be trained on large-scale web datasets with interleaved text and graphics to equip them with in-context few-shot learning skills. The same architecture that was suggested in the original Flamingo study (Perceiver resamplers, cross-attention layers) is implemented in OpenFlamingo. But, since Flamingo’s training data isn’t accessible to the general public, developers use open-source datasets to train models. The newly published OpenFlamingo-9B checkpoint was specifically trained on 10M samples from LAION-2B and 5M samples from the new Multimodal C4 dataset.
Developers are also including a checkpoint from our unfinished LMM OpenFlamingo-9B, which is based on LLaMA 7B and CLIP ViT/L-14, as part of the release. Even though this concept is still being developed, the community may already benefit greatly from it.

To get started, look at the GitHub source and demo.
Read more about AI:
Disclaimer
In line with the Trust Project guidelines, please note that the information provided on this page is not intended to be and should not be interpreted as legal, tax, investment, financial, or any other form of advice. It is important to only invest what you can afford to lose and to seek independent financial advice if you have any doubts. For further information, we suggest referring to the terms and conditions as well as the help and support pages provided by the issuer or advertiser. MetaversePost is committed to accurate, unbiased reporting, but market conditions are subject to change without notice.
About The Author
Damir is the team leader, product manager, and editor at Metaverse Post, covering topics such as AI/ML, AGI, LLMs, Metaverse, and Web3-related fields. His articles attract a massive audience of over a million users every month. He appears to be an expert with 10 years of experience in SEO and digital marketing. Damir has been mentioned in Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto, and other publications. He travels between the UAE, Turkey, Russia, and the CIS as a digital nomad. Damir earned a bachelor's degree in physics, which he believes has given him the critical thinking skills needed to be successful in the ever-changing landscape of the internet.
More articles
Damir is the team leader, product manager, and editor at Metaverse Post, covering topics such as AI/ML, AGI, LLMs, Metaverse, and Web3-related fields. His articles attract a massive audience of over a million users every month. He appears to be an expert with 10 years of experience in SEO and digital marketing. Damir has been mentioned in Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto, and other publications. He travels between the UAE, Turkey, Russia, and the CIS as a digital nomad. Damir earned a bachelor's degree in physics, which he believes has given him the critical thinking skills needed to be successful in the ever-changing landscape of the internet.





