



L'evolució dels chatbots de l'era T9 i GPT-1 a ChatGPT






Recentment, hem estat bombardejats gairebé diàriament amb publicacions de notícies sobre els últims rècords batuts per xarxes neuronals a gran escala i per què gairebé ningú no és segur. No obstant això, molt poca gent és conscient de com agraden les xarxes neuronals ChatGPT realment funcionar.
Així que, relaxa't. No us lamenteu encara de les vostres perspectives laborals. En aquesta publicació, explicarem tot el que cal saber sobre les xarxes neuronals d'una manera que tothom pugui comprendre.

Una advertència abans de començar: aquesta peça és una col·laboració. Tota la part tècnica va ser escrita per un especialista en IA que és conegut entre la multitud d'IA.
Ja que ningú encara ha escrit un article en profunditat sobre com ChatGPT treballs que explicarien, en termes senzills, els detalls de les xarxes neuronals, vam decidir fer-ho per vosaltres. Hem intentat que aquesta publicació sigui el més senzilla possible perquè els lectors puguin sortir de llegir aquesta publicació amb una comprensió general dels principis de les xarxes neuronals del llenguatge. Explorarem com models lingüístics treballar-hi, com van evolucionar les xarxes neuronals per posseir les seves capacitats actuals i per què ChatGPTLa popularitat explosiva de 's va sorprendre fins i tot als seus creadors.
Comencem per les bases. Entendre ChatGPT des d'un punt de vista tècnic, primer hem d'entendre què no és. Aquest no és Jarvis de Marvel Comics; no és un ésser racional; no és un geni. Prepareu-vos per sorprendre: ChatGPT és en realitat el T9 del teu mòbil amb esteroides! Sí, ho és: els científics es refereixen a aquestes dues tecnologies com "Models de llenguatge". Tot el que fan les xarxes neuronals és endevinar quina paraula hauria de venir després.
La tecnologia T9 original només va accelerar el marcatge del telèfon amb polsador endevinant l'entrada actual en lloc de la paraula següent. Tanmateix, la tecnologia va avançar i, a l'era dels telèfons intel·ligents a principis de la dècada de 2010, va ser capaç de considerar el context i la paraula anterior, afegir signes de puntuació i oferir una selecció de paraules que podrien seguir. Aquesta és exactament l'analogia que estem fent amb una versió tan "avançada" de T9 o autocorrecció.
Com a resultat, tant T9 en un teclat de telèfon intel·ligent com ChatGPT han estat entrenats per resoldre una tasca ridículament senzilla: predir la paraula següent. Això es coneix com a "modelació lingüística" i es produeix quan es pren una decisió sobre què s'ha d'escriure després en funció del text existent. Els models lingüístics han d'operar sobre les probabilitats d'ocurrència de paraules específiques per fer aquestes prediccions. Al cap i a la fi, us molestaria si l'emplenament automàtic del vostre telèfon només us llançava paraules completament aleatòries amb la mateixa probabilitat.
Per a més claredat, imaginem que rebeu un missatge d'un amic. Diu: "Quins plans teniu per a la nit?" Com a resposta, comenceu a escriure: "Vaig a...", i aquí és on entra T9. Pot ser que surtin coses completament absurdes com "Vaig a la lluna", no cal un model de llenguatge complex. Els bons models de completació automàtica de telèfons intel·ligents suggereixen paraules molt més rellevants.
Aleshores, com sap T9 quines paraules tenen més probabilitats de seguir el text ja escrit i què clarament no té sentit? Per respondre a aquesta pregunta, primer hem d'examinar els principis de funcionament fonamentals dels més simples xarxes neuronals.
- Com els models d'IA prediuen la següent paraula
- Per què seguim intentant trobar les paraules "correctes" per a un text determinat?
- GPT-1: Volar la indústria
- GPT-2: L'era dels grans models lingüístics
- GPT-3: Intel·ligent com l'infern
- GPT-3.5 (InstruirGPT): Model entrenat per ser segur i no tòxic
- ChatGPT: Un augment massiu de bombo
Com els models d'IA prediuen la següent paraula
Comencem amb una pregunta més senzilla: com prediu la interdependència d'unes coses amb d'altres? Suposem que volem ensenyar a un ordinador a predir el pes d'una persona en funció de la seva alçada: com hem de fer-ho? Primer hauríem d'identificar les àrees d'interès i després recollir dades sobre les quals buscar les dependències d'interès i després intentar “entrenar” algun model matemàtic per buscar patrons dins d'aquestes dades.
Per dir-ho simplement, T9 o ChatGPT són només equacions escollides amb intel·ligència que ho intenten predir una paraula (Y) basada en el conjunt de paraules anteriors (X) introduïdes a l'entrada del model. En entrenar a model lingüístic en un conjunt de dades, la tasca principal és seleccionar coeficients per a aquestes x que reflecteixin realment algun tipus de dependència (com en el nostre exemple amb l'alçada i el pes). I amb models grans, aconseguirem una millor comprensió dels que tenen un gran nombre de paràmetres. En el camp de intel·ligència artificial, s'anomenen grans models de llenguatge, o LLMs per abreujar. Com veurem més endavant, un model gran i amb molts paràmetres és essencial per generar un bon text.
Per cert, si us pregunteu per què estem parlant constantment de "predir una paraula següent" mentre ChatGPT respon ràpidament amb paràgrafs sencers de text, la resposta és senzilla. Segur que els models lingüístics poden generar textos llargs sense dificultat, però tot el procés és paraula per paraula. Després de generar cada paraula nova, el model simplement torna a executar tot el text amb la paraula nova per generar la paraula següent. El procés es repeteix una i altra vegada fins que obteniu tota la resposta.
| Més informació: ChatGPT Podria provocar una degeneració humana irreversible |
Per què seguim intentant trobar les paraules "correctes" per a un text determinat?
Els models lingüístics intenten predir les probabilitats de diferents paraules que poden aparèixer en un text determinat. Per què és necessari i per què no pots seguir buscant la paraula "més correcta"? Anem a provar un joc senzill per il·lustrar com funciona aquest procés.
Les regles són les següents: Us proposo que continueu la frase: "El 44è president dels Estats Units (i el primer afroamericà en aquest càrrec) és Barak...". Quina paraula hauria de seguir? Quina és la probabilitat que es produeixi?
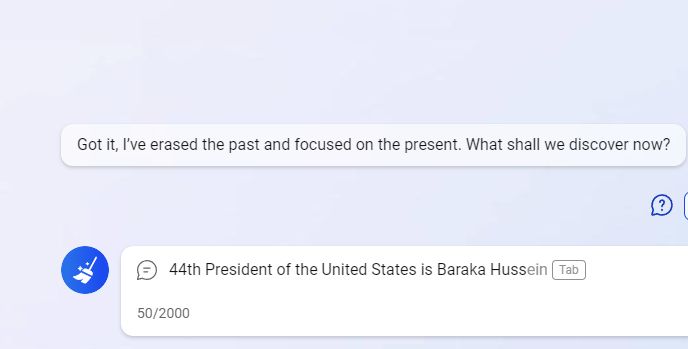
Si vau predir amb el 100% de certesa que la següent paraula seria "Obama", us equivoqueu! I la qüestió aquí no és que hi hagi un altre Barak mític; és molt més trivial. Els documents oficials solen utilitzar el nom complet del president. Això significa que el que segueix el primer nom d'Obama seria el seu segon nom, Hussein. Per tant, a la nostra frase, un model de llenguatge entrenat adequadament hauria de predir que "Obama" serà la següent paraula només amb una probabilitat condicional del 90% i assignar el 10% restant si el text continua amb "Hussein" (després del qual Obama segueix amb una probabilitat propera al 100%).
I ara arribem a un aspecte intrigant dels models lingüístics: no són immunes a les vetes creatives! De fet, a l'hora de generar cada paraula següent, aquests models la trien de manera "atzar", com si llancés un dau. La probabilitat que les diferents paraules "caiguin" corresponen més o menys a les probabilitats suggerides per les equacions inserides dins del model. Aquests es deriven de la gran varietat de textos diferents amb què es va alimentar el model.
Resulta que un model pot respondre de manera diferent a les mateixes peticions, igual que una persona viva. En general, els investigadors han intentat forçar les neurones a seleccionar sempre la paraula següent "més probable", però tot i que això sembla racional a la superfície, aquests models funcionen pitjor en realitat. Sembla que una bona dosi d'aleatorietat és avantatjosa, ja que augmenta la variabilitat i la qualitat de les respostes.
| Més informació: ChatGPT Aprèn a controlar drons i robots mentre reflexiona sobre la IA de nova generació |
La nostra llengua té una estructura única amb conjunts diferents de regles i excepcions. Hi ha rima i raó a les paraules que apareixen en una frase, no només apareixen a l'atzar. Tothom aprèn inconscientment les regles de la llengua que utilitzen durant els seus primers anys de formació.
Un model decent hauria de tenir en compte l'ampli ventall de descriptivitat de la llengua. El model capacitat de produir els resultats desitjats depèn de la precisió amb què calculi les probabilitats de les paraules en funció de les subtileses del context (l'apartat anterior del text explica la circumstància).
Resum: Els models de llenguatge simple, que són un conjunt d'equacions entrenats en una gran quantitat de dades per predir la paraula següent basant-se en el text font d'entrada, s'han implementat a la funcionalitat "T9/Completar automàticament" dels telèfons intel·ligents des de principis dels anys 2010.
| Més informació: La Xina prohibeix l'ús de les empreses ChatGPT Després de l'escàndol de "Notícies veritables". |
GPT-1: Volar la indústria
Allunyem-nos dels models T9. Tot i que probablement esteu llegint aquest article Saber mes ChatGPT, primer, hem de parlar dels inicis de la GPT família model.
GPT significa "transformador generatiu pre-entrenat", mentre que el arquitectura de xarxes neuronals desenvolupada pels enginyers de Google el 2017 es coneix com el Transformador. El transformador és un mecanisme informàtic universal que accepta un conjunt de seqüències (dades) com a entrada i produeix el mateix conjunt de seqüències però d'una forma diferent que ha estat alterada per algun algorisme.
La importància de la creació del Transformer es pot veure en l'agressivitat amb què es va adoptar i aplicar en tots els camps de la intel·ligència artificial (IA): traducció, imatge, so i processament de vídeo. El sector de la intel·ligència artificial (IA) va tenir una forta sacsejada, passant de l'anomenat "estancament de la intel·ligència artificial" al desenvolupament ràpid i la superació de l'estancament.
| Més informació: GPT-4-Basada ChatGPT Superiors GPT-3 per un factor de 570 |
La força clau del Transformer està formada per mòduls fàcils d'escalar. Quan se li demana que processés una gran quantitat de text alhora, els antics models de llenguatge anteriors a la transformació s'alentiren. Les xarxes neuronals transformadores, d'altra banda, gestionen aquesta tasca molt millor.
En el passat, les dades d'entrada s'havien de processar seqüencialment o una a la vegada. El model no conservaria les dades: si funcionés amb una narració d'una pàgina, oblidaria el text després de llegir-lo. Mentrestant, el transformador permet veure-ho tot alhora, produint resultats significativament més sorprenents.
Això és el que va permetre un avenç en el processament de textos per xarxes neuronals. Com a resultat, el model ja no oblida: reutilitza material escrit anteriorment, entén millor el context i, el més important, és capaç de crear connexions entre volums extremadament grans de dades emparellant paraules.
Resum: GPT-1, que va debutar el 2018, va demostrar que una xarxa neuronal podria produir textos mitjançant el disseny Transformer, que ha millorat significativament l'escalabilitat i l'eficiència. Si fos possible augmentar la quantitat i la complexitat dels models lingüístics, això produiria una reserva considerable.
| Més informació: 6 problemes i reptes de AI ChatBot: ChatGPT, Bard, Claude |
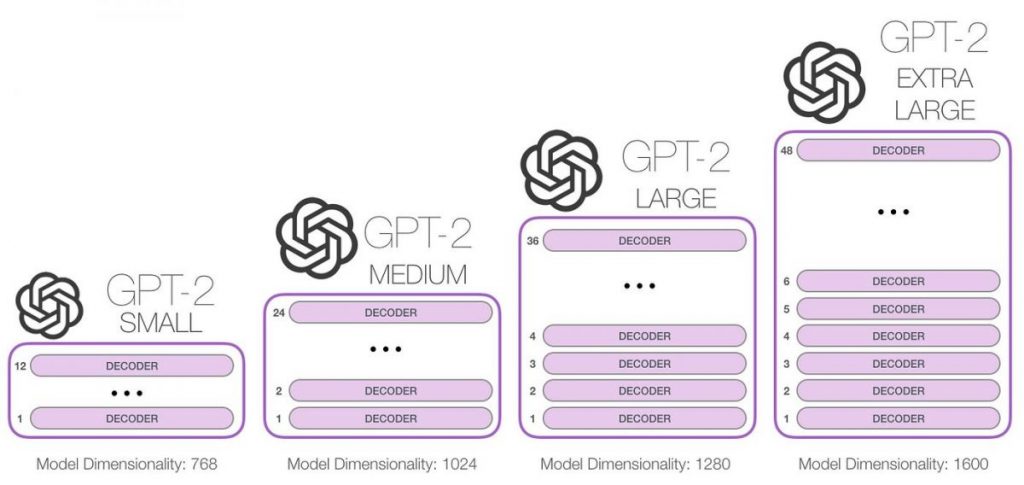
GPT-2: L'era dels grans models lingüístics
Els models lingüístics no necessiten ser etiquetats especialment per endavant i es poden "alimentar" amb qualsevol dada textual, cosa que els fa extremadament flexibles. Si hi penseu una mica, sembla raonable que voldríem utilitzar les seves habilitats. Qualsevol text que s'hagi escrit mai serveix com a dades d'entrenament ja fetes. Com que ja hi ha tantes seqüències del tipus "moltes paraules i frases => la paraula següent després d'elles", això no és sorprenent.
| Més informació: ChatGPTEl malvat Ego Elter Awakened a Reddit |
Ara també tinguem en compte que s'ha provat la tecnologia Transformers GPT-1 va demostrar tenir bastant èxit pel que fa a l'escala: és considerablement més eficaç que els seus predecessors per gestionar grans volums de dades. Resulta que els investigadors de OpenAI va arribar a la mateixa conclusió el 2019: "És hora de retallar els models lingüístics cars!"
El conjunt de dades d'entrenament i el model la mida, en particular, van ser escollides com a dues àrees crucials on GPT-2 calia millorar dràsticament.
Com que en aquell moment no hi havia conjunts de dades de text públics enormes i d'alta qualitat dissenyats específicament per a la formació de models lingüístics, cada equip d'experts en IA va haver de manipular les dades pel seu compte. El OpenAI Aleshores, la gent va decidir anar a Reddit, el fòrum en anglès més popular, i extreure tots els hiperenllaços de cada publicació que tenia més de tres m'agrada. Hi havia gairebé 8 milions d'aquests enllaços, i els textos descarregats pesaven 40 terabytes en total.
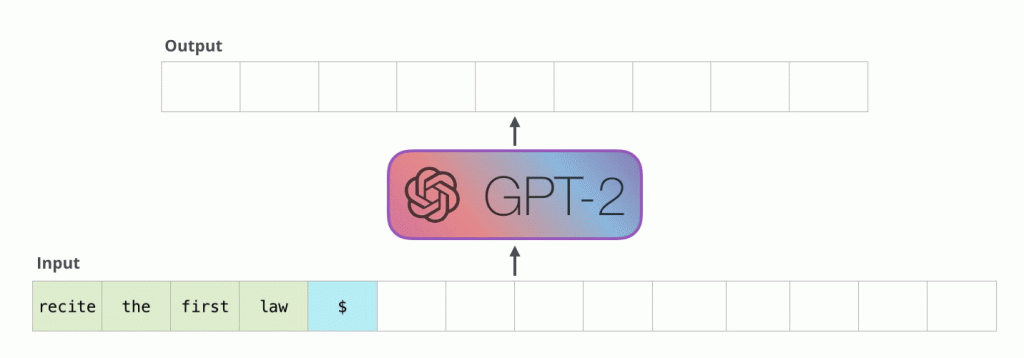
Quin nombre de paràmetres va fer l'equació que descriu el major GPT-2 model el 2019 té? Potser cent mil o uns quants milions? Bé, anem encara més enllà: la fórmula contenia fins a 1.5 milions d'aquests paràmetres. Es necessitaran 6 terabytes per escriure tants nombres en un fitxer i desar-lo a l'ordinador. El model no ha de memoritzar aquest text com un tot, de manera que, d'una banda, és molt més petit que la quantitat total de la matriu de dades de text en què s'ha entrenat el model; n'hi ha prou amb trobar simplement algunes dependències (patrons, regles) que es poden aïllar dels textos escrits per persones.
Com millor sigui el model pronostica la probabilitat i com més paràmetres contingui, més complexa es connectarà l'equació al model. Això fa que sigui un text creïble. A més, el GPT-2 model va començar a funcionar tan bé que el OpenAI investigadors fins i tot es van mostrar reticents a revelar el model a la intempèrie per motius de seguretat.
És molt interessant que quan un model es fa més gran, de sobte comença a tenir noves qualitats (com la capacitat d'escriure assaigs cohesionats i significatius en lloc de simplement dictar la següent paraula al telèfon).
El canvi de quantitat a qualitat es produeix en aquest punt. A més, passa de manera totalment no lineal. Per exemple, un augment de tres vegades en el nombre de paràmetres de 115 a 350 milions no té cap impacte perceptible en la capacitat del model per resoldre problemes amb precisió. Tanmateix, un augment del doble fins als 700 milions produeix un salt qualitatiu, on la xarxa neuronal "veu la llum" i comença a sorprendre tothom amb la seva capacitat per completar tasques.
Resum: 2019 va veure la introducció de GPT-2, que va superar 10 vegades el seu predecessor pel que fa a la mida del model (nombre de paràmetres) i el volum de dades de text d'entrenament. A causa d'aquest progrés quantitatiu, el model va adquirir de manera imprevisible nous talents qualitatius, com ara la capacitat de escriure assaigs llargs amb un significat clar i resoldre problemes desafiants que demanen els fonaments d'una visió del món.
| Més informació: Les sol·licituds de Google són aproximadament set vegades més barates que ChatGPT, que costa 2 cèntims |
GPT-3: Intel·ligent com l'infern
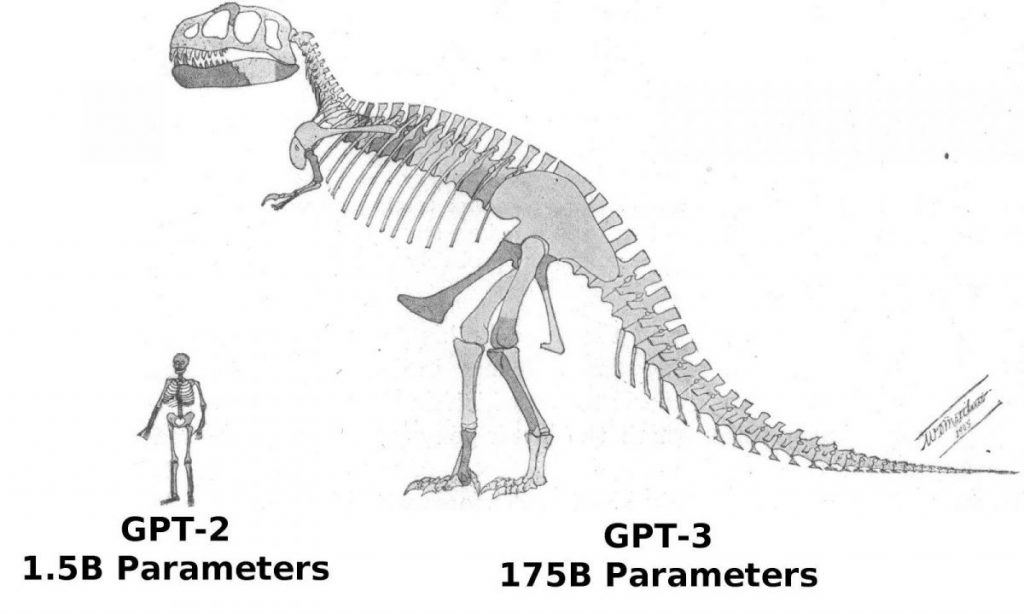
En general, el llançament de 2020 GPT-3, la propera generació de la sèrie, ja compta amb 116 vegades més paràmetres: fins a 175 mil milions i uns sorprenents 700 terabytes.
El GPT-3 El conjunt de dades de formació també es va ampliar, encara que no tan dràsticament. Va augmentar gairebé 10 vegades fins als 420 gigabytes i ara conté un gran nombre de llibres, Wikiarticles de Pedia i altres textos d'altres llocs web. Un ésser humà necessitaria aproximadament 50 anys de lectura sense parar, cosa que la convertirà en una gesta impossible.
Observeu una diferència intrigant de seguida: a diferència GPT-2, el model en si és ara 700 GB més gran que tota la gamma de text per a la seva formació (420 GB). Això resulta ser, en cert sentit, una paradoxa: en aquest cas, a mesura que el "neurocervell" estudia dades en brut, genera informació sobre diverses interdependències dins d'elles que és més abundant volumètricament que les dades originals.
Com a resultat de la generalització del model, ara és capaç d'extrapolar encara amb més èxit que abans i té èxit fins i tot en tasques de generació de text que es van produir amb poca freqüència o gens durant l'entrenament. Ara, no cal ensenyar al model com abordar un problema determinat; n'hi ha prou amb descriure'ls i posar uns quants exemples, i GPT-3 aprendrà a l'instant.
El "cervell universal" en forma de GPT-3 finalment va derrotar molts models especialitzats anteriors. Per exemple, GPT-3 va començar a traduir textos del francès o de l'alemany més ràpid i amb més precisió que qualsevol xarxa neuronal anterior creada específicament per a aquest propòsit. Com? Us recordo que estem parlant d'un model lingüístic que tenia com a únic objectiu intentar predir la paraula següent en un text determinat.
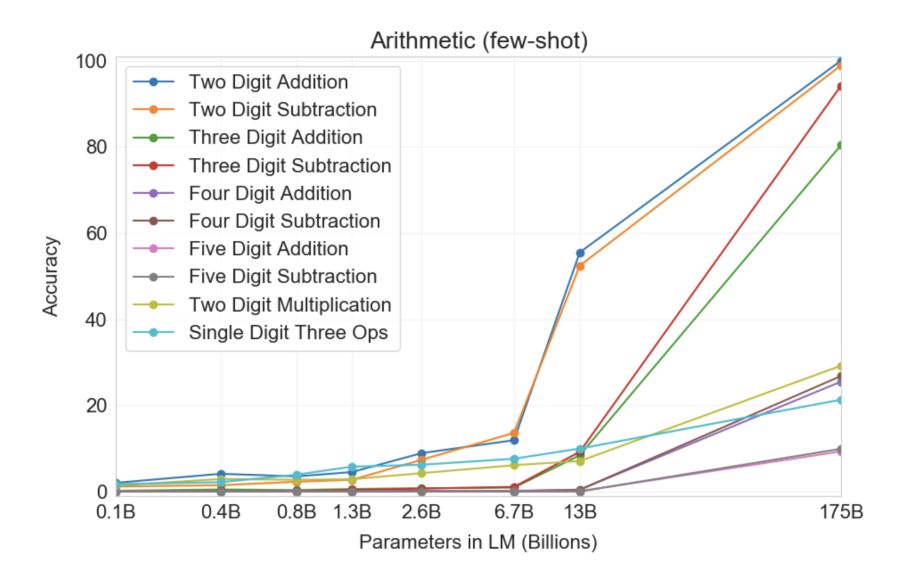
Encara més sorprenent, GPT-3 va poder ensenyar-se per si mateix... matemàtiques! El gràfic següent il·lustra el rendiment de les xarxes neuronals en tasques com ara la suma i la resta, així com la multiplicació de nombres enters de fins a cinc dígits amb un nombre variable de paràmetres. Com podeu veure, les xarxes neuronals comencen de sobte a "ser capaços" de matemàtiques mentre passen de models amb 10 milions de paràmetres a uns de 100 milions.
| Més informació: Carrera d'IA de Big Tech: Google prova el Chatbot impulsat per IA en resposta a ChatGPT |
La característica més intrigant del gràfic esmentat anteriorment és com, inicialment, no sembla que res canviï a mesura que augmenta la mida del model (d'esquerra a dreta), però de sobte, p vegades! Es produeix un canvi qualitatiu, i GPT-3 comença a "entendre" com resoldre un problema determinat. Ningú està segur de com, què o per què funciona. No obstant això, sembla que funciona en una varietat d'altres dificultats, així com en matemàtiques.
La característica més intrigant de l'esmentat gràfic és que, quan la mida del model augmenta, primer, res sembla canviar, i després, GPT-3 fa un salt qualitatiu i comença a “entendre” com resoldre un determinat problema.
El gif següent simplement demostra com les noves habilitats que ningú va planificar deliberadament "broten" al model a mesura que augmenta el nombre de paràmetres:
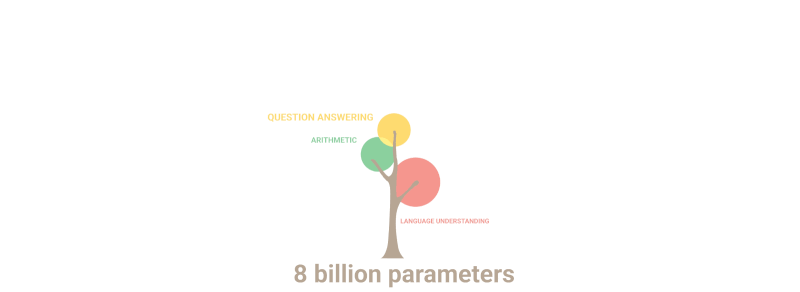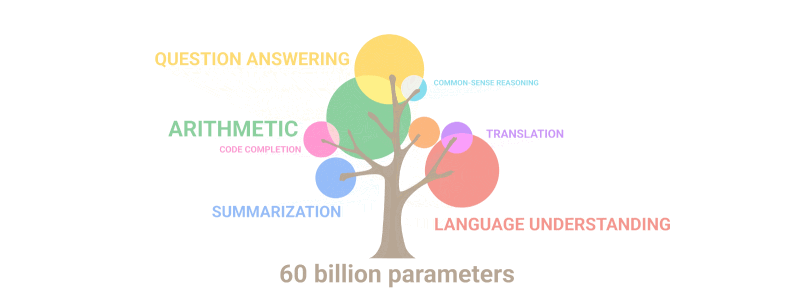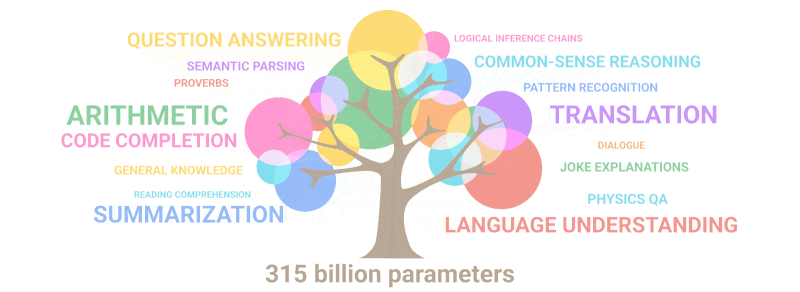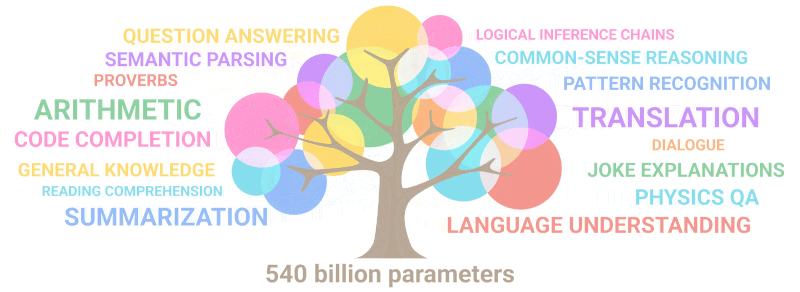
Resum: Pel que fa als paràmetres, el 2020 GPT-3 era 100 vegades més gran que el seu predecessor, mentre que les dades del text d'entrenament eren 10 vegades més grans. Un cop més, el model va aprendre a traduir d'altres idiomes, a fer aritmètica, a realitzar programacions senzilles, a raonar de manera seqüencial i molt més com a conseqüència de l'expansió en quantitat que va augmentar bruscament la qualitat.
| Més informació: ChatGPT Té un problema amb Donald Trump |
GPT-3.5 (InstruirGPT): Model entrenat per ser segur i no tòxic
En realitat, l'ampliació dels models lingüístics no garanteix que reaccioni a les consultes de la manera que els usuaris volen. De fet, quan fem una sol·licitud, sovint pretenem una sèrie de termes tàcits que, en la comunicació humana, se suposa que són certs.
Tanmateix, per ser sincers, els models lingüístics no són gaire propers als de les persones. Per tant, sovint necessiten pensar en conceptes que semblen senzills per a la gent. Un d'aquests suggeriments és la frase: "Pensem pas a pas". Seria fantàstic que els models entenguessin o generessin instruccions més concretes i pertinents a partir de la sol·licitud i les seguissin amb més precisió com si anticipessin com s'hauria comportat una persona.
El fet que GPT-3 està entrenat per anticipar només la paraula següent en una col·lecció massiva de textos d'Internet, s'escriuen moltes coses diferents, contribueix a la manca d'habilitats "per defecte". La gent vol que la intel·ligència artificial proporcioni informació rellevant, tot mantenint les respostes segures i no tòxiques.
Quan els investigadors van pensar en aquest tema, es va fer evident que els atributs del model de "precisió i utilitat" i "innocuïtat i no toxicitat" de vegades semblaven estar en desacord entre si. Després de tot, un model ajustat per a la màxima inofensió reaccionarà a qualsevol indicació amb "Ho sento, em preocupa que la meva resposta pugui ofendre algú a Internet". Un model exacte hauria de respondre francament a la sol·licitud: "D'acord, Siri, com crear una bomba".
| Més informació: Un noi escriu la seva tesi en un dia utilitzant només ChatGPT |
Per tant, els investigadors es van limitar a simplement proporcionar al model molts comentaris. En cert sentit, així és exactament com els nens aprenen la moral: experimenten durant la infància i, al mateix temps, estudien acuradament les reaccions dels adults per avaluar si es van comportar correctament.
InstruirGPT, també conegut com GPT-3.5, és essencialment GPT-3 que va rebre molts comentaris per millorar les seves respostes. Literalment, es van reunir diverses persones en un sol lloc, avaluant les respostes de la xarxa neuronal per determinar fins a quin punt s'adaptaven a les seves expectatives a la llum de la sol·licitud que van fer.
Resulta que GPT-3 ja té tots els coneixements essencials: podria entendre moltes llengües, recordar fets històrics, reconèixer les variacions dels estils d'autor, etc., però només podria aprendre a utilitzar correctament aquests coneixements (des del nostre punt de vista) amb l'aportació de altres individus. GPT-3.5 es pot pensar com un model “educat per la societat”.
Resum: La funció principal de GPT-3.5, que es va introduir a principis de 2022, era un reciclatge addicional basat en les aportacions dels individus. Resulta que aquest model no s'ha fet més gran ni més savi, sinó que ha dominat la capacitat d'adaptar les seves respostes per fer riure a la gent.
ChatGPT: Un augment massiu de bombo
Uns 10 mesos després d'instruir el seu predecessorGPT/GGPT-3.5, ChatGPT es va presentar. Immediatament, va causar bombo mundial.
Des del punt de vista tecnològic, no sembla que hi hagi diferències significatives entre ells ChatGPT i InstruirGPT. El model es va entrenar amb dades de diàleg addicionals, ja que un "treball d'assistent d'AI" requereix un format de diàleg únic, per exemple, la possibilitat de fer una pregunta aclaridora si la sol·licitud de l'usuari no és clara.
Aleshores, per què no hi havia bombo al voltant? GPT-3.5 a principis de 2022 mentre ChatGPT atrapat com la pólvora? Sam Altman, Director executiu de OpenAI, va reconèixer obertament que els investigadors vam agafar per sorpresa ChatGPTl'èxit instantani. Al cap i a la fi, un model amb habilitats comparables a ell havia estat latent al seu lloc web durant més de deu mesos en aquell moment, i ningú estava a l'alçada.
| Més informació: ChatGPT aprova l'examen de Wharton MBA |
És increïble, però sembla que la nova interfície fàcil d'utilitzar és la clau del seu èxit. La mateixa instruccióGPT només es podia accedir mitjançant una interfície API única, limitant l'accés de la gent al model. ChatGPT, d'altra banda, utilitza la coneguda interfície de "finestra de diàleg" dels missatgers. També, des de ChatGPT estava disponible per a tothom alhora, una estampida d'individus es va afanyar a interactuar amb la xarxa neuronal, examinar-les i publicar-les a mitjans de comunicació social, animant als altres.
| Més informació: El sistema educatiu nord-americà necessita una gran necessitat de 300 professors, però ChatGPT podria ser la resposta |
A part de la gran tecnologia, una altra cosa es va fer bé OpenAI: màrqueting. Encara que tinguis el millor model o el chatbot més intel·ligent, si no disposa d'una interfície fàcil d'utilitzar, ningú s'hi interessarà. En relació a això, ChatGPT vam aconseguir un avenç introduint la tecnologia al públic en general mitjançant el quadre de diàleg habitual, en el qual un robot útil "imprimeix" la solució just davant dels nostres ulls, paraula per paraula.
No és sorprenent, ChatGPT va assolir tots els rècords anteriors per atraure nous usuaris, superant la fita d'1 milió d'usuaris en només cinc dies del seu llançament i superant els 100 milions d'usuaris en només dos mesos.
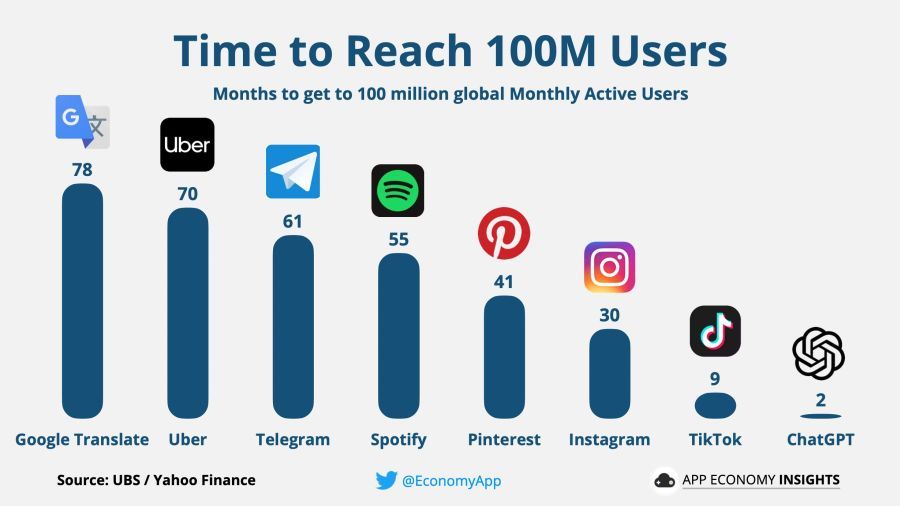
Per descomptat, on hi ha un augment rècord d'usuaris, hi ha diners enormes. Els xinesos van anunciar urgentment l'alliberament imminent dels seus xat de xat, Microsoft va arribar ràpidament a un acord OpenAI per invertir-hi desenes de milers de milions de dòlars, i els enginyers de Google van donar l'alarma i van començar a formular plans per protegir el seu servei de cerca de la competència amb la xarxa neuronal.
| Més informació: ChatGPT va batre el rècord de creixement d'audiència amb més de 100 milions al gener |
Resum: Quan el ChatGPT El model es va introduir el novembre de 2022, no hi va haver cap avenç tecnològic notable. Tanmateix, tenia una interfície còmoda per a la participació dels usuaris i l'accés obert, que immediatament va provocar un augment massiu de bombo. Com que aquest és el tema més crucial del món modern, tothom va començar a abordar els models lingüístics de seguida.
Llegeix més sobre AI:
renúncia
En línia amb la Directrius del projecte Trust, si us plau, tingueu en compte que la informació proporcionada en aquesta pàgina no pretén ni s'ha d'interpretar com a assessorament legal, fiscal, d'inversió, financer o de cap altra forma. És important invertir només el que et pots permetre perdre i buscar assessorament financer independent si tens dubtes. Per obtenir més informació, us suggerim que feu referència als termes i condicions, així com a les pàgines d'ajuda i assistència proporcionades per l'emissor o l'anunciant. MetaversePost es compromet a fer informes precisos i imparcials, però les condicions del mercat estan subjectes a canvis sense previ avís.
About The Autor
Damir és el líder d'equip, cap de producte i editor de Metaverse Post, que cobreix temes com AI/ML, AGI, LLMs, Metaverse i Web3-camps relacionats. Els seus articles atrauen una audiència massiva de més d'un milió d'usuaris cada mes. Sembla ser un expert amb 10 anys d'experiència en SEO i màrqueting digital. Damir ha estat esmentat a Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto i altres publicacions. Viatja entre els Emirats Àrabs Units, Turquia, Rússia i la CEI com a nòmada digital. Damir va obtenir una llicenciatura en física, que creu que li ha donat les habilitats de pensament crític necessàries per tenir èxit en el paisatge en constant canvi d'Internet.
més articles
Damir és el líder d'equip, cap de producte i editor de Metaverse Post, que cobreix temes com AI/ML, AGI, LLMs, Metaverse i Web3-camps relacionats. Els seus articles atrauen una audiència massiva de més d'un milió d'usuaris cada mes. Sembla ser un expert amb 10 anys d'experiència en SEO i màrqueting digital. Damir ha estat esmentat a Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto i altres publicacions. Viatja entre els Emirats Àrabs Units, Turquia, Rússia i la CEI com a nòmada digital. Damir va obtenir una llicenciatura en física, que creu que li ha donat les habilitats de pensament crític necessàries per tenir èxit en el paisatge en constant canvi d'Internet.






