



30+ најбољих модела трансформатора у АИ: шта су и како раде







Последњих месеци у АИ су се појавили бројни модели Трансформера, сваки са јединственим и понекад забавним именима. Међутим, ова имена можда неће пружити много увида у то шта ови модели заправо раде. Овај чланак има за циљ да пружи свеобухватну и јасну листу најпопуларнијих модела Трансформера. Он ће класификовати ове моделе и такође увести важне аспекте и иновације унутар породице Трансформер. Топ листа ће покрити обучени модели кроз самоконтролисано учење, попут БЕРТ или GPT-3, као и модели који пролазе додатну обуку уз учешће људи, као што је ИнструцтGPT модел који користи ChatGPT.

| Про Типс |
|---|
| Овај водич је дизајниран да пружи свеобухватно знање и практичне вештине у брзом инжењерингу за почетнике до напредних ученика. |
| Постоји много курсева доступно за појединце који желе да науче више о АИ и сродним технологијама. |
| Погледајте ово 10+ најбољих АИ акцелератора од којих се очекује да предњаче на тржишту у погледу перформанси. |
- Шта су трансформатори у АИ?
- Шта су кодери и декодери у АИ?
- Шта су слојеви пажње у АИ?
- Шта су фино подешени модели у АИ?
- Зашто су трансформатори будућност вештачке интелигенције?
- 3 врсте архитектура за претходну обуку
- 8 врста задатака за претходно обучене моделе
- 30+ најбољих трансформатора у вештачкој интелигенцији
- ФАК
Шта су трансформатори у АИ?
Трансформатори су врста модела дубоког учења који су представљени у истраживачком раду под називом „Пажња је све што вам треба” истраживача Гоогле-а 2017. Овај рад је стекао огромно признање, акумулирајући преко 38,000 цитата за само пет година.
Оригинална архитектура трансформатора је специфичан облик модела кодер-декодер који је стекао популарност пре свог увођења. Ови модели су се углавном ослањали на ЛСТМ и друге варијације рекурентних неуронских мрежа (РНН-ови), при чему је пажња само један од механизама који се користе. Међутим, Трансформер документ предложио је револуционарну идеју да пажња може послужити као једини механизам за успостављање зависности између улаза и излаза.
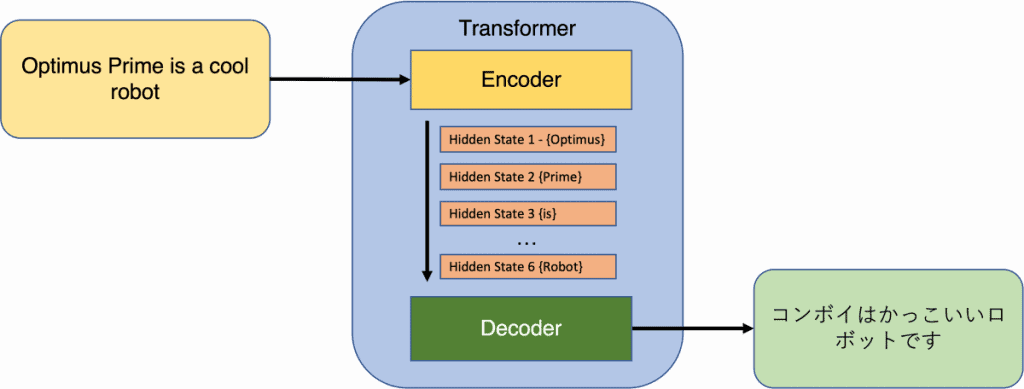
У контексту Трансформерса, улаз се састоји од низа токена, који могу бити речи или подречи у обради природног језика (НЛП). Подречи се обично користе у НЛП моделима за решавање питања речи ван речника. Излаз енкодера производи репрезентацију фиксне димензије за сваки токен, заједно са засебним уграђивањем за читав низ. Декодер узима излаз енкодера и генерише низ токена као свој излаз.
Од објављивања Трансформер папира, популарни модели попут БЕРТ GPT су усвојили аспекте оригиналне архитектуре, било користећи компоненте енкодера или декодера. Кључна сличност између ових модела лежи у архитектури слојева, која укључује механизме самопажње и слојеве за прослеђивање. У Трансформерсима, сваки улазни токен прелази свој пут кроз слојеве док одржава директне зависности са сваким другим токеном у улазној секвенци. Ова јединствена карактеристика омогућава паралелно и ефикасно израчунавање контекстуалних репрезентација токена, што није изводљиво са секвенцијалним моделима као што су РНН.
Иако овај чланак само загреба површину Трансформер архитектуре, он пружа увид у њене основне аспекте. За свеобухватније разумевање, препоручујемо да се позовете на оригинални истраживачки рад или пост Тхе Иллустратед Трансформер.
Шта су кодери и декодери у АИ?
Замислите да имате два модела, енкодер и декодер, раде заједно као тим. Кодер узима улаз и претвара га у вектор фиксне дужине. Затим, декодер узима тај вектор и трансформише га у излазну секвенцу. Ови модели су обучени заједно како би били сигурни да излаз одговара улазу што је ближе могуће.
И кодер и декодер су имали неколико слојева. Сваки слој у енкодеру имао је два подслоја: слој самопажње са више глава и једноставну мрежу унапред. Слој самопажње помаже сваком токену у улазу да разуме односе са свим осталим токенима. Ови подслојеви такође имају заосталу везу и нормализацију слоја да би процес учења био лакши.
Декодер има више глава слој самопажње ради мало другачије од оног у кодеру. Он маскира жетоне десно од токена на који се фокусира. Ово осигурава да декодер гледа само токене који долазе испред оног који покушава да предвиди. Ова маскирана пажња са више глава помаже декодеру да генерише тачна предвиђања. Поред тога, декодер укључује још један подслој, који је слој пажње са више глава преко свих излаза из енкодера.
Важно је напоменути да су ови специфични детаљи модификовани у различитим варијацијама модела Трансформер. Модели попут БЕРТ и GPT, на пример, засновани су или на аспекту кодера или декодера оригиналне архитектуре.
Шта су слојеви пажње у АИ?
У архитектури модела о којој смо раније говорили, слојеви пажње са више глава су посебни елементи који га чине моћним. Али шта је заправо пажња? Замислите то као функцију која мапира питање у скуп информација и даје излаз. Сваки токен у улазу има упит, кључ и вредност придружену њему. Излазни приказ сваког токена се израчунава узимањем пондерисане суме вредности, при чему је тежина за сваку вредност одређена колико добро одговара упиту.
Трансформатори користе функцију компатибилности која се зове скалирани тачкасти производ за израчунавање ових тежина. Интересантна ствар у вези са пажњом у Трансформерсима је да сваки токен пролази кроз сопствену путању израчунавања, омогућавајући паралелно израчунавање свих жетона у улазној секвенци. То је једноставно више блокова пажње који независно израчунавају репрезентације за сваки токен. Ове репрезентације се затим комбинују да би се створила коначна репрезентација токена.
У поређењу са другим типовима мрежа као што су рекурентне и конволуционе мреже, слојеви пажње имају неколико предности. Они су рачунарски ефикасни, што значи да могу брзо да обрађују информације. Такође имају већу повезаност, што је корисно за снимање дугорочних веза у секвенцама.
Шта су фино подешени модели у АИ?
Модели темеља су моћни модели који су обучени на великој количини општих података. Затим се могу прилагодити или фино подесити за специфичне задатке тако што ће их обучити на мањем скупу подаци специфични за циљ. Овај приступ, популаризован од БЕРТ папир, довела је до доминације модела заснованих на трансформатору у задацима машинског учења у вези са језиком.
У случају модела као што је БЕРТ, они производе репрезентације улазних токена, али не остварују специфичне задатке сами. Да би били корисни, додатни неуронских слојева се додају на врх и модел се обучава од краја до краја, процес познат као фино подешавање. Међутим, са генеративни модели као GPT, приступ је мало другачији. GPT је модел језика декодера обучен да предвиди следећу реч у реченици. Обуком о огромним количинама веб података, GPT може да генерише разумне резултате на основу улазних упита или упита.
Да би GPT корисније, OpenAI истраживачи развили УпутитеGPT, који је обучен да прати људска упутства. Ово се постиже финим подешавањем GPT користећи податке означене људима из различитих задатака. ИнструцтGPT је способан за обављање широког спектра задатака и користе га популарни мотори попут ChatGPT.
Фино подешавање се такође може користити за креирање варијанти модела темеља оптимизованих за специфичне намене мимо језичког моделирања. На пример, постоје модели фино подешени за семантичке задатке као што су класификација текста и претраживање. Поред тога, трансформаторски енкодери су успешно фино подешени у оквиру више задатака оквири за учење за обављање више семантичких задатака користећи један заједнички модел.
Данас се фино подешавање користи за креирање верзија модела темеља које може да користи велики број корисника. Процес укључује генерисање одговора на унос подстицање и омогућавање људима да рангирају резултате. Ово рангирање се користи за обуку а модел награђивања, који сваком излазу додељује резултате. Учење са појачањем уз помоћ људских повратних информација се затим користи за даљу обуку модела.
Зашто су трансформатори будућност вештачке интелигенције?
Трансформатори, врста моћног модела, први пут су демонстрирани у области превода језика. Међутим, истраживачи су брзо схватили да се трансформатори могу користити за различите задатке везане за језик тако што ће их обучити на великој количини необиљеженог текста, а затим их фино подесити на мањем скупу означених података. Овај приступ је омогућио Трансформерсима да стекну значајно знање о језику.
Трансформер архитектура, првобитно дизајнирана за језичке задатке, такође је примењена на друге апликације као што су генерисање слика, аудио, музика, па чак и акције. Ово је учинило Трансформерс кључном компонентом у области генеративне вештачке интелигенције, која мења различите аспекте друштва.
Доступност алата и оквира као нпр ПиТорцх ТенсорФлов је одиграо кључну улогу у широком усвајању модела Трансформера. Компаније као што је Хуггингфаце су изградиле своје посао око идеје комерцијализације Трансформер библиотека отвореног кода и специјализованог хардвера као што је НВИДИА Хоппер Тенсор Цорес додатно је убрзао обуку и брзину закључивања ових модела.
Једна значајна примена Трансформерса је ChatGPT, цхатбот који је објавио OpenAI. Постао је невероватно популаран, достигавши милионе корисника за кратко време. OpenAI је такође најавио ослобађање GPT-4, моћнија верзија способна да постигне перформансе попут људи у задацима као што су лекарске и правне испите.
Утицај Трансформера у области вештачке интелигенције и њихове широке примене је неоспоран. Они имају преобразио начин приступамо задацима везаним за језик и утиремо пут новим напретцима у генеративној вештачкој интелигенцији.
3 врсте архитектура за претходну обуку
Архитектура трансформатора, која се првобитно састојала од енкодера и декодера, еволуирала је тако да укључује различите варијације засноване на специфичним потребама. Хајде да једноставно разложимо ове варијације.
- Енцодер Претраининг: Ови модели се фокусирају на разумевање целих реченица или пасуса. Током претренинга, кодер се користи за реконструкцију маскираних токена у улазној реченици. Ово помаже моделу да научи да разуме општи контекст. Такви модели су корисни за задатке као што су класификација текста, повлачење и извлачење одговора на питања.
- Претренинг декодера: Модели декодера су обучени да генеришу следећи токен на основу претходног низа токена. Они су познати као ауто-регресивни језички модели. Слојеви самопажње у декодеру могу приступити само токенима испред датог токена у реченици. Ови модели су идеални за задатке који укључују генерисање текста.
- Трансформатор (кодер-декодер) Претренинг: Ова варијација комбинује компоненте енкодера и декодера. Слојеви самопажње кодера могу приступити свим улазним токенима, док слојеви самопажње декодера могу приступити само токенима пре датог токена. Ова архитектура омогућава декодеру да користи репрезентације које је кодер научио. Модели кодер-декодер су веома погодни за задатке као што су сумирање, превођење или генеративно одговарање на питања.
Циљеви пре обуке могу укључивати деноисинг или каузално моделирање језика. Ови циљеви су сложенији за моделе кодер-декодер у поређењу са моделима који користе само кодер или само декодер. Архитектура трансформатора има различите варијације у зависности од фокуса модела. Било да се ради о разумевању целих реченица, генерисању текста или комбиновању оба за различите задатке, Трансформерс нуди флексибилност у решавању различитих изазова везаних за језик.
8 врста задатака за претходно обучене моделе
Када обучавамо модел, треба да му дамо задатак или циљ да учимо. Постоје различити задаци у обради природног језика (НЛП) који се могу користити за моделе за претходну обуку. Хајде да једноставно разложимо неке од ових задатака:
- Моделирање језика (ЛМ): Модел предвиђа следећу лексему у реченици. Учи да разуме контекст и генерише кохерентне реченице.
- Моделирање узрочног језика: Модел предвиђа следећи токен у текстуалном низу, пратећи редослед с лева на десно. То је као модел приповедања који генерише реченице једну реч по једну.
- Моделирање језика префикса: Модел одваја део 'префикса' од главне секвенце. Може да прати било који токен унутар префикса, а затим генерише остатак низа ауторегресивно.
- Моделирање маскираног језика (МЛМ): Неки токени у улазним реченицама су маскирани, а модел предвиђа токене који недостају на основу околног контекста. Учи да попуни празна места.
- Моделирање пермутираног језика (ПЛМ): Модел предвиђа следећи токен на основу случајне пермутације улазне секвенце. Учи да рукује различитим редоследом токена.
- Деноисинг Аутоенцодер (ДАЕ): Модел узима делимично оштећен улаз и има за циљ да поврати оригинални, неискривљени улаз. Учи да се носи са буком или деловима текста који недостају.
- Детекција замењеног токена (РТД): Модел открива да ли токен потиче из оригиналног текста или генерисане верзије. Учи да идентификује замењене или изманипулисане токене.
- Предвиђање следеће реченице (НСП): Модел учи да разликује да ли су две улазне реченице континуирани сегменти од података обуке. Разуме однос између реченица.
Ови задаци помажу моделу да научи структуру и значење језика. Предобуком за ове задатке, модели стичу добро разумевање језика пре него што буду фино подешени за специфичне апликације.
30+ најбољих трансформатора у вештачкој интелигенцији
| Име | Претраининг Арцхитецтуре | Задатак | апликација | Развијен од стране |
|---|---|---|---|---|
| АЛБЕРТ | енцодер | МЛМ/НСП | Исто као БЕРТ | гоогле |
| Алпаца | декодер | LM | Задаци генерисања и класификације текста | Станфорд |
| АлпхаФолд | енцодер | Предвиђање савијања протеина | Протеин фолдинг | Дубок ум |
| Антропски асистент (види такође) | декодер | LM | Од општег дијалога до помоћника кода. | Антропски |
| БАРТ | Енцодер/Децодер | ДАЕ | Задаци генерисања текста и разумевања текста | фацебоок |
| БЕРТ | енцодер | МЛМ/НСП | Разумевање језика и одговарање на питања | гоогле |
| БлендерБот 3 | декодер | LM | Задаци генерисања текста и разумевања текста | фацебоок |
| БЛООМ | декодер | LM | Задаци генерисања текста и разумевања текста | Велика наука/Хуггингфаце |
| ChatGPT | декодер | LM | Дијалог агенти | OpenAI |
| цинцила | декодер | LM | Задаци генерисања текста и разумевања текста | Дубок ум |
| ЦЛИП | енцодер | Класификација слика/објеката | OpenAI | |
| ЦТРЛ | декодер | Генерисање текста које се може контролисати | Салесфорце | |
| ДАЛЛ-Е | декодер | Предвиђање натписа | Текст у слику | OpenAI |
| ДАЛЛ-Е-2 | Енцодер/Децодер | Предвиђање натписа | Текст у слику | OpenAI |
| ДеБЕРТа | декодер | МЛМ | Исто као БЕРТ | Microsoft |
| Децисион Трансформерс | декодер | Предвиђање следеће акције | Општи РЛ (задаци учења са појачањем) | Гоогле/УЦ Беркелеи/ФАИР |
| ДиалоGPT | декодер | LM | Генерисање текста у подешавањима дијалога | Microsoft |
| ДистилБЕРТ | енцодер | МЛМ/НСП | Разумевање језика и одговарање на питања | хуггингфаце |
| ДК-БАРТ | Енцодер/Децодер | ДАЕ | Генерисање и разумевање текста | амазонка |
| луткица | декодер | LM | Задаци генерисања и класификације текста | Датабрицкс, Инц |
| ЕРНИЕ | енцодер | МЛМ | Задаци у вези са интензивним знањем | Разне кинеске институције |
| Фламинго | декодер | Предвиђање натписа | Текст у слику | Дубок ум |
| Галацтица | декодер | LM | Научни КА, математичко резоновање, сумирање, генерисање докумената, предвиђање молекуларних својстава и екстракција ентитета. | мета |
| ГЛИДЕ | енцодер | Предвиђање натписа | Текст у слику | OpenAI |
| GPT-3.5 | декодер | LM | Дијалошки и општи језик | OpenAI |
| GPTУпутите | декодер | LM | Задаци за дијалог или језик који захтевају много знања | OpenAI |
| ХТМЛ- | Енцодер/Децодер | ДАЕ | Језички модел који омогућава структурирано ХТМЛ упите | фацебоок |
| Слика | T5 | Предвиђање натписа | Текст у слику | гоогле |
| ЛАМДА | декодер | LM | Опште језичко моделовање | гоогле |
| LLaMA | декодер | LM | Здрав разум, одговарање на питања, генерисање кода и разумевање читања. | мета |
| Минерва | декодер | LM | Математичко резоновање | гоогле |
| палма | декодер | LM | Разумевање језика и генерација | гоогле |
| РоБЕРТа | енцодер | МЛМ | Разумевање језика и одговарање на питања | УВ/Гоогле |
| врабац | декодер | LM | Агенти за дијалог и опште апликације за генерисање језика као што су питања и одговори | Дубок ум |
| СтаблеДиффусион | Енцодер/Децодер | Предвиђање натписа | Текст у слику | ЛМУ Минхен + Стабилност.аи + Елеутхер.аи |
| Вицуна | декодер | LM | Дијалог агенти | УЦ Беркелеи, ЦМУ, Станфорд, УЦ Сан Диего и МБЗУАИ |
ФАК
Трансформатори у АИ су врста архитектура дубоког учења то је променило обраду природног језика и друге задатке. Они користе механизме самопажње да би ухватили односе између речи у реченици, омогућавајући им да разумеју и генеришу текст сличан човеку.
Кодери и декодери су компоненте које се обично користе у моделима од секвенце до секвенце. Кодери обрађују улазне податке, као што су текст или слике, и конвертују их у компримовани приказ, док декодери генеришу излазне податке на основу кодиране репрезентације, омогућавајући задатке као што су превод језика или титловање слика.
Слојеви пажње су компоненте које се користе у неуронске мреже, посебно у моделима Трансформер. Они омогућавају моделу да се селективно фокусира на различите делове улазне секвенце, додељујући тежине сваком елементу на основу његове релевантности, омогућавајући ефикасно хватање зависности и односа између елемената.
Фино подешени модели се односе на унапред обучене моделе који су додатно обучени за одређени задатак или скуп података како би побољшали своје перформансе и прилагодили их специфичним захтевима тог задатка. Овај процес финог подешавања укључује прилагођавање параметара модела како би се оптимизовала његова предвиђања и учинила специјализованијим за циљни задатак.
Трансформатори се сматрају будућношћу вештачке интелигенције јер су показали изузетне перформансе у широком спектру задатака, укључујући обраду природног језика, генерисање слика и још много тога. Њихова способност да ухвате дугорочне зависности и ефикасно обраде секвенцијалне податке чини их веома прилагодљивим и ефикасним за различите апликације, утирући пут напретку у генеративној вештачкој интелигенцији и револуционишући многе аспекте друштва.
Најпознатији модели трансформатора у АИ укључују БЕРТ (Бидирецтионал Енцодер Репресентатионс фром Трансформерс), GPT (Генеративни унапред обучени трансформатор) и Т5 (Тект-то-Тект Трансфер Трансформер). Ови модели су постигли изузетне резултате у различитим задацима обраде природног језика и стекли су значајну популарност у истраживачкој заједници АИ.
Прочитајте више о АИ:
Одрицање од одговорности
У складу са Смернице пројекта Труст, имајте на уму да информације дате на овој страници нису намењене и не треба да се тумаче као правни, порески, инвестициони, финансијски или било који други облик савета. Важно је да инвестирате само оно што можете приуштити да изгубите и да тражите независан финансијски савет ако сумњате. За додатне информације, предлажемо да погледате одредбе и услове, као и странице помоћи и подршке које пружа издавач или оглашивач. MetaversePost је посвећен тачном, непристрасном извештавању, али тржишни услови су подложни променама без претходне најаве.
О аутору
Дамир је вођа тима, менаџер производа и уредник у Metaverse Post, покривајући теме као што су АИ/МЛ, АГИ, ЛЛМ, Метаверсе и Web3-сродна поља. Његови чланци привлаче огромну публику од преко милион корисника сваког месеца. Чини се да је стручњак са 10 година искуства у СЕО и дигиталном маркетингу. Дамир се помиње у Масхабле, Виред, Cointelegraph, Тхе Нев Иоркер, Инсиде.цом, Ентрепренеур, БеИнЦрипто и друге публикације. Путује између УАЕ, Турске, Русије и ЗНД као дигитални номад. Дамир је стекао диплому физике, за коју верује да му је дало вештине критичког размишљања које су му потребне да буде успешан у свету интернета који се стално мења.
više чланака
Дамир је вођа тима, менаџер производа и уредник у Metaverse Post, покривајући теме као што су АИ/МЛ, АГИ, ЛЛМ, Метаверсе и Web3-сродна поља. Његови чланци привлаче огромну публику од преко милион корисника сваког месеца. Чини се да је стручњак са 10 година искуства у СЕО и дигиталном маркетингу. Дамир се помиње у Масхабле, Виред, Cointelegraph, Тхе Нев Иоркер, Инсиде.цом, Ентрепренеур, БеИнЦрипто и друге публикације. Путује између УАЕ, Турске, Русије и ЗНД као дигитални номад. Дамир је стекао диплому физике, за коју верује да му је дало вештине критичког размишљања које су му потребне да буде успешан у свету интернета који се стално мења.






