



Еволуција четбота из Т9-ере и GPT-1 до ChatGPT






Недавно смо скоро свакодневно бомбардовани објавама вести о најновијим рекордима које су обориле велике неуронске мреже и зашто скоро ничији посао није сигуран. Ипак, врло мало људи зна како се неуронске мреже воле ChatGPT заправо делују.
Дакле, опусти се. Немојте још жалити за изгледима за посао. У овом посту ћемо објаснити све што треба да се зна о неуронским мрежама на начин који свако може да схвати.

Упозорење пре него што почнемо: Овај комад је сарадња. Цео технички део је написао стручњак за вештачку интелигенцију који је добро познат међу АИ гомилом.
Пошто још нико није опширније написао како ChatGPT радове који би објаснили, лаички речено, детаље неуронских мрежа, одлучили смо да ово урадимо за вас. Потрудили смо се да овај пост буде што једноставнији како би читаоци могли да изађу из читања овог поста са општим разумевањем принципа језичких неуронских мрежа. Истражићемо како језички модели раде тамо, како су неуронске мреже еволуирале да би поседовале своје тренутне могућности и зашто ChatGPTЕксплозивна популарност је изненадила чак и њене креаторе.
Почнимо са основама. Разумети ChatGPT са техничког становишта, прво морамо разумети шта није. Ово није Јарвис из Марвел Цомицс-а; није разумно биће; није дух. Припремите се да будете шокирани: ChatGPT је заправо Т9 вашег мобилног телефона на стероидима! Да, јесте: научници обе ове технологије називају „језички модели“. Све што неуронске мреже раде је да погоде која реч треба да дође следећа.
Оригинална Т9 технологија само је убрзала бирање помоћу дугмета тако што је погодила тренутни унос, а не следећу реч. Међутим, технологија је напредовала и до ере паметних телефона почетком 2010-их, могла је да узме у обзир контекст и реч пре, дода интерпункцију и понуди избор речи које би могле да иду следеће. Управо то је аналогија коју правимо са тако „напредном“ верзијом Т9 или аутоисправком.
Као резултат тога, и Т9 на тастатури паметног телефона и ChatGPT били су обучени да реше смешно једноставан задатак: предвиђање следеће речи. Ово је познато као „моделирање језика“ и дешава се када се донесе одлука о томе шта би требало следеће написати на основу постојећег текста. Језички модели морају да оперишу на вероватноћама појављивања одређених речи да би направили таква предвиђања. На крају крајева, били бисте изнервирани да вам је аутоматско попуњавање телефона само бацило потпуно насумичне речи са истом вероватноћом.
Ради јасноће, замислимо да сте примили поруку од пријатеља. Пише: „Какви су ти планови за вече?“ Као одговор, почнете да куцате: „Идем на…“, и ту долази Т9. Може доћи до потпуно бесмислених ствари попут „Идем на Месец“, није потребан сложени језички модел. Добри модели за аутоматско довршавање паметних телефона сугеришу далеко релевантније речи.
Дакле, како Т9 зна које речи ће вероватније пратити већ откуцани текст, а шта очигледно нема смисла? Да бисмо одговорили на ово питање, прво морамо испитати основне принципе рада најједноставнијих неуронске мреже.
Како АИ модели предвиђају следећу реч
Почнимо са једноставнијим питањем: Како предвиђате међузависност неких ствари од других? Претпоставимо да желимо да научимо рачунар да предвиђа нечију тежину на основу њене висине - како да то урадимо? Прво би требало да идентификујемо области интересовања, а затим да прикупимо податке на основу којих бисмо потражили зависности од интереса, а затим покушали да „обучите” неки математички модел да траже обрасце унутар ових података.
Поједностављено речено, Т9 или ChatGPT су само паметно одабране једначине које покушавају да предвидети реч (И) заснована на скупу претходних речи (Кс) унетих у улаз модела. Приликом обуке а језички модел на скупу података, главни задатак је одабрати коефицијенте за ове к који заиста одражавају неку врсту зависности (као у нашем примеру са висином и тежином). А помоћу великих модела, боље ћемо разумети оне са великим бројем параметара. У области вештачка интелигенција, они се називају великим језичким моделима, или скраћено ЛЛМ. Као што ћемо касније видети, велики модел са много параметара је неопходан за генерисање доброг текста.
Успут, ако се питате зашто стално причамо о „предвиђању једне следеће речи“ док ChatGPT брзо одговара целим пасусима текста, одговор је једноставан. Наравно, језички модели могу генерисати дугачке текстове без потешкоћа, али цео процес је реч по реч. Након што је генерисана свака нова реч, модел једноставно поново покреће цео текст са новом речју да генерише следећу реч. Процес се понавља изнова и изнова док не добијете цео одговор.
Зашто стално покушавамо да пронађемо 'тачне' речи за дати текст?
Језички модели покушавају да предвиде вероватноће различитих речи које се могу појавити у датом тексту. Зашто је ово неопходно и зашто не можете само да наставите да тражите „најтачнију“ реч? Хајде да пробамо једноставну игру да илуструјемо како овај процес функционише.
Правила су следећа: Предлажем да наставите реченицу: „44. председник Сједињених Држава (и први Афроамериканац на овој позицији) је Барак…“. Која реч треба да иде следећа? Која је вероватноћа да ће се то догодити?
Ако сте са 100% сигурношћу предвидели да ће следећа реч бити „Обама“, погрешили сте! А поента овде није у томе да постоји још један митски Барак; много је тривијалније. Званични документи обично користе пуно име председника. То значи да би оно што следи после Обаминог имена било његово средње име, Хусеин. Дакле, у нашој реченици, правилно обучен језички модел треба да предвиди да ће „Обама“ бити следећа реч само са условном вероватноћом од 90% и доделити преосталих 10% ако текст настави „Хусеин“ (након чега ће Обама следе са вероватноћом близу 100%).
А сада долазимо до интригантног аспекта језичких модела: они нису имуни на креативне линије! У ствари, када генеришу сваку следећу реч, такви модели је бирају на „насумичан“ начин, као да бацају коцку. Вероватноћа да различите речи „испадну“ мање-више одговарају вероватноћама које сугеришу једначине уметнуте унутар модела. Они су изведени из огромног низа различитих текстова којима је модел храњен.
Испоставило се да модел може другачије да одговори на исте захтеве, баш као и жив човек. Истраживачи су генерално покушавали да приморају неуроне да увек бирају „највероватније“ следећу реч, али иако се то на површини чини рационалним, такви модели у стварности имају лошије резултате. Чини се да је добра доза случајности корисна јер повећава варијабилност и квалитет одговора.
| Још: ChatGPT Учи да контролише дронове и роботе док размишља о вештачкој интелигенцији следеће генерације |
Наш језик има јединствену структуру са различитим скуповима правила и изузетака. Постоје рима и разлог за оно што се речи појављују у реченици, оне се не појављују само насумично. Свако несвесно учи правила језика који користи током својих раних година формирања.
Пристојан модел треба да узме у обзир широк спектар описности језика. Модел је способност да се произведу жељени резултати зависи од тога колико прецизно израчунава вероватноће речи на основу суптилности контекста (претходни део текста који објашњава околност).
Резиме: Једноставни језички модели, који су скуп једначина обучених на огромној количини података за предвиђање следеће речи на основу текста извора уноса, имплементирани су у „Т9/Аутофилл“ функционалност паметних телефона од раних 2010-их.
GPT-1: Дизање индустрије у ваздух
Одмакнимо се од модела Т9. Док вероватно читате овај део учи о ChatGPT, прво, треба да разговарамо о почецима GPT модел породице.
GPT означава „генеративни унапред обучени трансформатор“, док је архитектура неуронске мреже коју су развили Гоогле инжењери 2017. је познат као Трансформер. Трансформатор је универзални рачунарски механизам који прихвата скуп секвенци (података) као улаз и производи исти скуп секвенци али у другачијем облику који је измењен неким алгоритмом.
Значај стварања Трансформера види се у томе колико је агресивно усвојен и примењен у свим областима вештачке интелигенције (АИ): превођење, слика, звук и видео обрада. Сектор вештачке интелигенције (АИ) доживео је снажан потрес, крећући се од такозване „стагнације вештачке интелигенције“ ка брзом развоју и превазилажењу стагнације.
Кључна снага Трансформера састоји се од модула који се лако прилагођавају. Када би се од њих тражило да обрађују велику количину текста одједном, стари, пре-трансформаторски језички модели би успоравали. Трансформаторске неуронске мреже, с друге стране, много боље решавају овај задатак.
У прошлости су улазни подаци морали да се обрађују узастопно или један по један. Модел не би задржао податке: ако би радио са наративом од једне странице, заборавио би текст након што га прочита. У међувремену, Трансформер омогућава да се види све одједном, производњу знатно запањујућих резултата.
То је омогућило искорак у обради текстова неуронским мрежама. Као резултат тога, модел више не заборавља: поново користи претходно писани материјал, боље разуме контекст и, што је најважније, у стању је да створи везе између изузетно великих количина података упарујући речи.
Резиме: GPT-1, који је дебитовао 2018. године, показао је да неуронска мрежа може да производи текстове користећи Трансформер дизајн, који је значајно побољшао скалабилност и ефикасност. Ако би било могуће повећати квантитет и сложеност језичких модела, то би произвело знатну резерву.
GPT-2: Доба великих језичких модела
Језички модели не морају бити посебно означени унапред и могу се „нахранити“ било којим текстуалним подацима, што их чини изузетно флексибилним. Ако мало размислите, чини се разумним да бисмо желели да искористимо његове способности. Сваки текст који је икада написан служи као готови подаци за обуку. Пошто већ постоји толико низова типа „много неких речи и фраза => следећа реч после њих“, ово није изненађујуће.
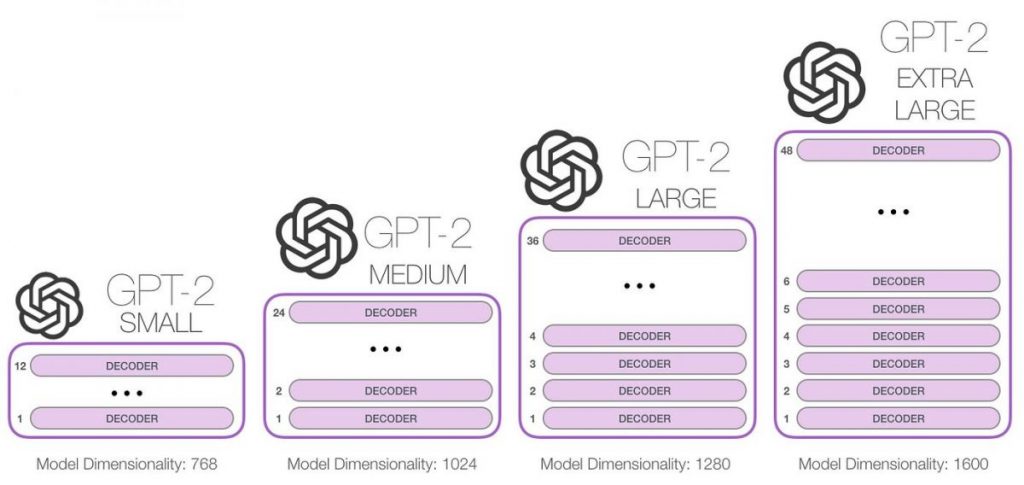
Сада имајмо на уму да је технологија Трансформерс тестирана на GPT-1 показао се прилично успешним у смислу скалирања: знатно је ефикаснији од својих претходника у руковању великим количинама података. Испоставља се да истраживачи из OpenAI дошао до истог закључка 2019: „Време је да смањимо скупе језичке моделе!“
скуп података за обуку и модел величина, посебно, изабране су као две кључне области где GPT-2 требало драстично побољшати.
Пошто у то време није било огромних, висококвалитетних јавних текстуалних скупова података посебно дизајнираних за обуку језичких модела, сваки тим стручњака за вештачку интелигенцију морао је сам да манипулише подацима. Тхе OpenAI људи су тада донели одлуку да оду на Реддит, најпопуларнији форум на енглеском језику, и извуку све хипервезе из сваке објаве која је имала више од три лајкова. Било је скоро 8 милиона ових линкова, а преузети текстови су укупно тежили 40 терабајта.
Који број параметара је имала једначина која описује највећи GPT-2 модел у 2019. имају? Можда сто хиљада или неколико милиона? Па, идемо још даље: формула је садржала до 1.5 милијарди таквих параметара. Биће потребно 6 терабајта да само упишете толико бројева у датотеку и сачувате је на рачунару. Модел не мора да памти овај текст у целини, тако да је с једне стране ово далеко мање од укупне количине текстуалног низа података на којој је модел обучен; довољно је да једноставно пронађе неке зависности (обрасци, правила) које се могу издвојити из текстова које су написали људи.
Што модел боље предвиђа вероватноћу и што више параметара садржи, то је једначина сложенија у моделу. Ово чини кредибилан текст. Поред тога, тхе GPT-2 модел је почео да ради тако добро да је OpenAI istraživači чак нису били вољни да открију модел на отвореном из безбедносних разлога.
Веома је интересантно да када модел постане већи, он одједном почиње да има нове квалитете (као што је способност писања кохезивних, смислених есеја уместо да само диктира следећу реч на телефону).
У овом тренутку долази до промене од квантитета до квалитета. Штавише, то се дешава потпуно нелинеарно. На пример, троструко повећање броја параметара са 115 на 350 милиона нема приметан утицај на способност модела да тачно решава проблеме. Међутим, двоструко повећање на 700 милиона производи квалитативни скок, где неуронска мрежа „види светлост“ и почиње да задивљује све својом способношћу да обавља задатке.
Резиме: 2019. године је уведен GPT-2, који је 10 пута надмашио свог претходника по величини модела (број параметара) и обиму текстуалних података за обуку. Услед овог квантитативног напретка, модел је непредвидиво стекао квалитативно нове таленте, као што је способност да писати дугачке есеје са јасним значењем и решавају изазовне проблеме који захтевају темеље погледа на свет.
GPT-3: Паметан као пакао
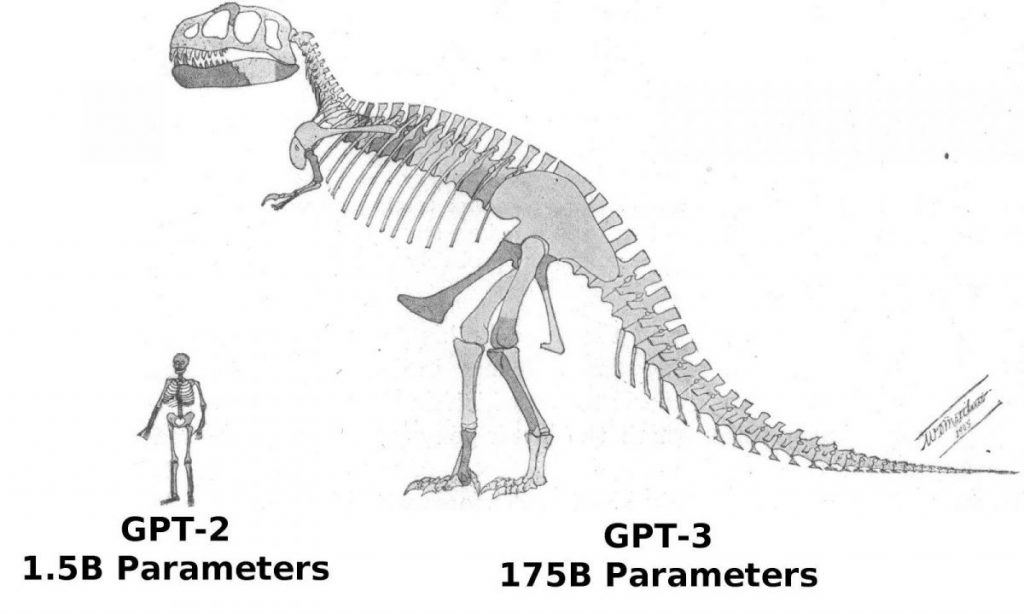
Генерално, издање 2020 GPT-3, следећа генерација у серији, већ има 116 пута више параметара — до 175 милијарди и запањујућих 700 терабајта.
GPT-3 сет података за обуку је такође проширен, мада не тако драстично. Порастао је скоро 10 пута на 420 гигабајта и сада садржи велики број књига, Wikiчланци из педијата и други текстови са других веб локација. Човеку би требало отприлике 50 година непрекидног читања, што би га чинило немогућим подвигом.
Одмах приметите интригантну разлику: за разлику од GPT-2, сам модел је сада 700 ГБ већи од читавог низа текста за његову обуку (420 ГБ). Испоставило се да је то, на неки начин, парадокс: у овом случају, док „неуробраин“ проучава сирове податке, он генерише информације о различитим међузависностима унутар њих које су волуметријски богатије од оригиналних података.
Као резултат генерализације модела, сада је у стању да екстраполира још успешније него раније и успешан је чак и у задацима генерисања текста који су се ретко или уопште нису дешавали током обуке. Сада, не морате да подучавате модел како да се позабави одређеним проблемом; довољно их је описати и дати неколико примера, и GPT-3 одмах ће научити.
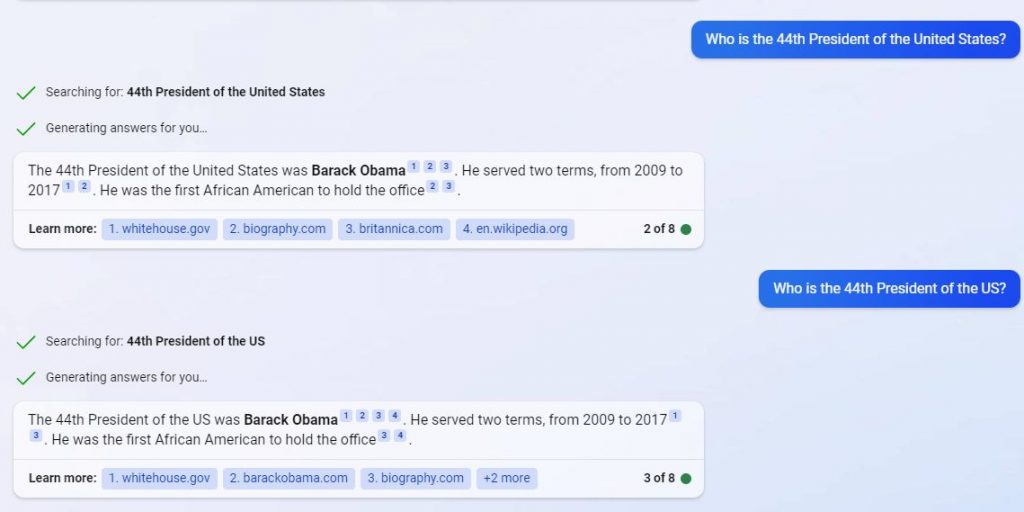
"универзални мозак" у облику GPT-3 на крају победио многе раније специјализоване моделе. На пример, GPT-3 почео да преводи текстове са француског или немачког брже и тачније од свих претходних неуронских мрежа креираних специјално за ову сврху. Како? Дозволите ми да вас подсетим да говоримо о лингвистичком моделу чији је једини циљ био да покуша да предвиди следећу реч у датом тексту.
Још запањујуће, GPT-3 могао сам да учи... математику! Графикон испод илуструје колико добро неуронске мреже раде на задацима укључујући сабирање и одузимање, као и множење целих бројева до пет цифара са различитим бројем параметара. Као што видите, неуронске мреже одједном почињу да „могу“ у математици док прелазе са модела са 10 милијарди параметара на оне са 100 милијарди.
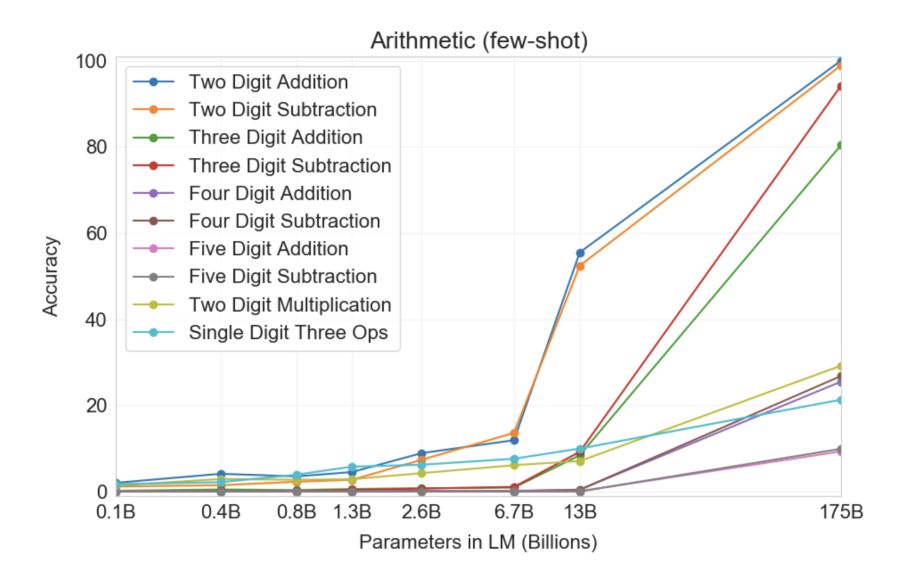
Најинтригантнија карактеристика горе поменутог графикона је како се у почетку ништа не мења како се величина модела повећава (с лева на десно), али одједном, п пута! Долази до квалитативне промене и GPT-3 почиње да „разуме“ како да реши одређени проблем. Нико није сигуран како, шта или зашто функционише. Ипак, чини се да функционише у низу других потешкоћа, као и у математици.
Најинтригантнија карактеристика горе поменутог графикона је да када се величина модела повећа, прво изгледа да се ништа не мења, а затим, GPT-3 прави квалитативни скок и почиње да „разуме“ како да реши одређени проблем.
Гиф испод једноставно показује како нове способности које нико није намерно планирао „никну“ у моделу како се број параметара повећава:
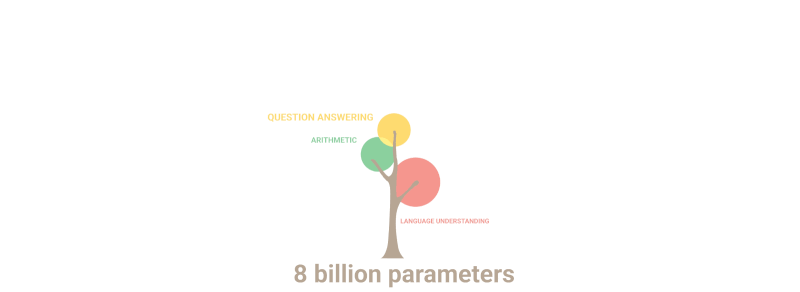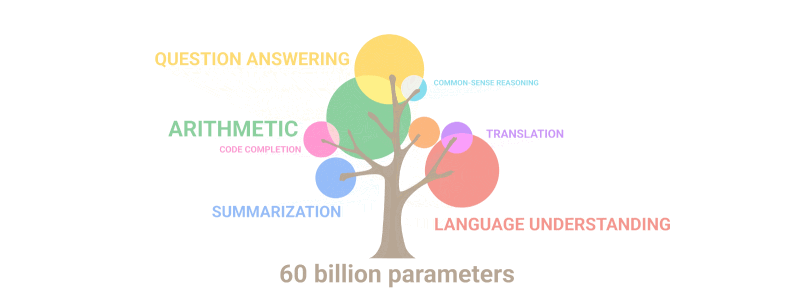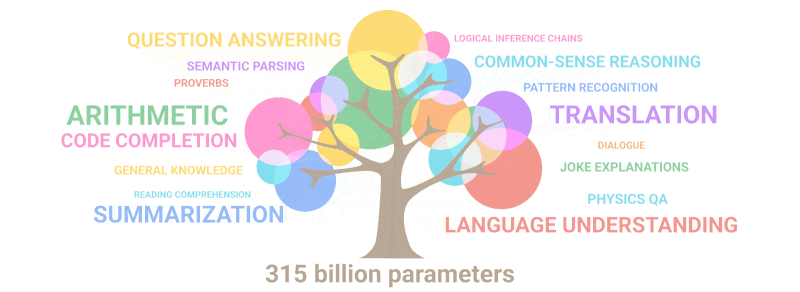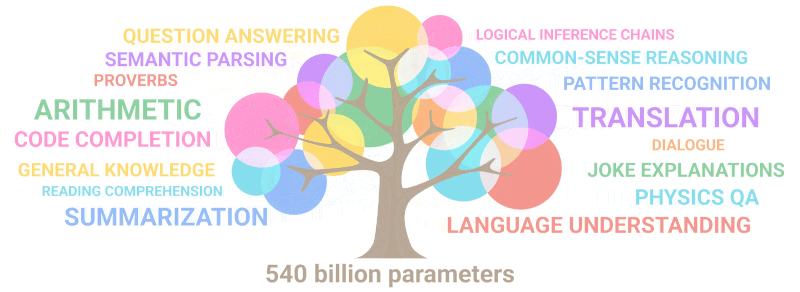
Резиме: Што се тиче параметара, 2020 GPT-3 био 100 пута већи од свог претходника, док су подаци о тексту за обуку били 10 пута већи. Још једном, модел је научио да преводи са других језика, изводи аритметику, изводи једноставно програмирање, размишља секвенцијално и још много тога као резултат проширења количине која је нагло повећала квалитет.
GPT-3.5 (УпутиGPT): Модел обучен да буде безбедан и нетоксичан
У ствари, проширење језичких модела не гарантује да ће реаговати на упите онако како то корисници желе. У ствари, када постављамо захтев, често намеравамо да изразимо низ неизговорених израза за које се у људској комуникацији претпоставља да су истинити.
Ипак, да будемо искрени, језички модели нису баш блиски онима код људи. Стога често морају да размишљају о концептима који људима изгледају једноставни. Један такав предлог је фраза „размишљајмо корак по корак. Било би фантастично када би модели разумели или генерисали конкретнија и релевантнија упутства из захтева и следили их прецизније као да предвиђају како би се особа понашала.
Чињеница да GPT-3 је обучен да само антиципира следећу реч у огромној колекцији текстова са интернета, написано је много различитих ствари, доприноси недостатку таквих „подразумеваних“ способности. Људи желе да вештачка интелигенција пружи релевантне информације, а да притом одговори буду безбедни и нетоксични.
Када су истраживачи мало размислили о овом питању, постало је очигледно да су атрибути модела „тачност и корисност“ и „безопасност и нетоксичност“ понекад изгледали у супротности једни са другима. На крају крајева, модел подешен за максималну безопасност ће на сваки упит реаговати са „Извините, забринут сам да би мој одговор могао да увреди некога на Интернету“. Тачан модел би требао искрено да одговори на захтев: „У реду, Сири, како направити бомбу.
Истраживачи су, стога, били ограничени на једноставно пружање модела са пуно повратних информација. У извесном смислу, деца управо тако уче морал: експериментишу у детињству, а истовремено пажљиво проучавају реакције одраслих да би проценили да ли су се понашали исправно.
УпутитеGPT, такође познат као GPT-3.5, у суштини је GPT-3 који је добио много повратних информација како би побољшао своје одговоре. Буквално, одређени број појединаца је окупљен на једном месту, процењујући одговоре неуронске мреже како би утврдили колико добро одговарају њиховим очекивањима у светлу захтева који су упутили.
Испада да GPT-3 већ је већ имао сва суштинска знања: могао је да разуме многе језике, да се сети историјских догађаја, да препозна варијације у ауторским стиловима, и тако даље, али само може да научи да правилно користи ово знање (са наше тачке гледишта) уз допринос другим појединцима. GPT-3.5 може се сматрати моделом „образованог у друштву“.
Резиме: Примарна функција GPT-3.5, који је уведен почетком 2022. године, био је додатна преквалификација заснована на инпутима појединаца. Испоставило се да овај модел заправо није постао већи и мудрији, већ је овладао способношћу прилагођавања својих одговора тако да људима изазове најлуђи смех.
ChatGPT: Массиве Сурве оф Хипе
Отприлике 10 месеци након свог претходника ИнструцтGPT/GGPT-3.КСНУМКС, ChatGPT је уведен. То је одмах изазвало глобалну хајку.
Са технолошког становишта, не изгледа да постоје значајне разлике између ChatGPT и ИнструцтGPT. Модел је обучен са додатним дијалошким подацима јер „посао помоћника АИ“ захтева јединствени формат дијалога, на пример, могућност постављања питања за појашњење ако је захтев корисника нејасан.
Дакле, зашто није било хипе около GPT-3.5 почетком 2022. док ChatGPT захватио као пожар? Сам Алтман, Извршни директор OpenAI, отворено је признао да су истраживачи које смо изненадили ChatGPTтренутни успех. На крају крајева, модел са способностима сличним њему је у том тренутку лежао успаван на њиховој веб страници више од десет месеци и нико није био на висини задатка.
Невероватно је, али изгледа да је нови интерфејс прилагођен кориснику кључ његовог успеха. Исто УпутствоGPT могло се приступити само преко јединственог АПИ интерфејса, ограничавајући приступ људи моделу. ChatGPT, с друге стране, користи добро познати интерфејс „прозора дијалога“ за гласнике. Такође, пошто ChatGPT био доступан свима одједном, стампедо појединаца пожурио је да ступи у интеракцију са неуронском мрежом, прегледа их и постави на друштвени медији, подстичући друге.
| Још: Америчком образовном систему је преко потребно 300 хиљада наставника — али ChatGPT може бити одговор |
Осим одличне технологије, још једна ствар је урађена како треба OpenAI: Маркетинг. Чак и ако имате најбољи модел или најинтелигентнијег цхатбот-а, ако нема интерфејс који је једноставан за коришћење, нико неће бити заинтересован за њега. У вези са овим, ChatGPT остварио је искорак тако што је технологију представио широј јавности користећи уобичајени оквир за дијалог, у којем робот од помоћи „штампа“ решење право пред нашим очима, реч по реч.
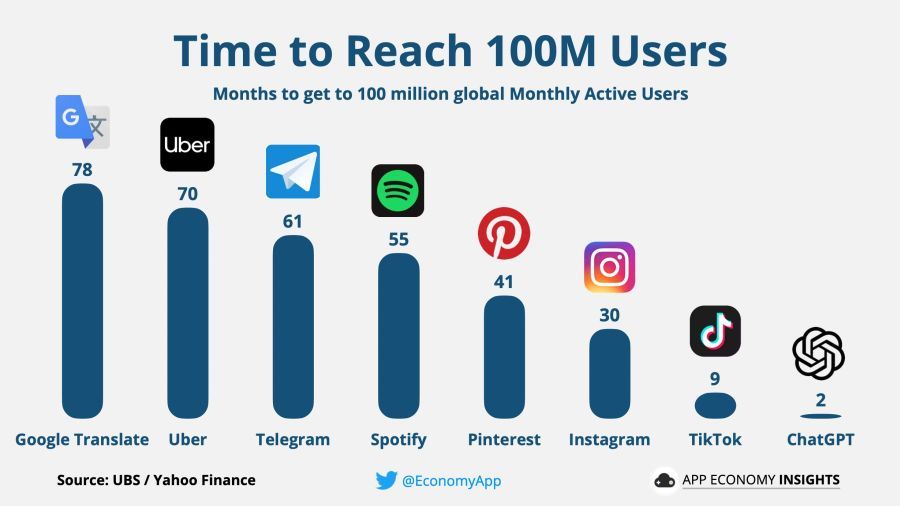
Не изненађује, ChatGPT погодио све досадашње рекорде у привлачењу нових корисника, премашивши прекретницу од милион корисника за само пет дана од лансирања и прешавши 1 милиона корисника за само два месеца.
Наравно, тамо где постоји рекордан пораст броја корисника, постоји огроман новац. Кинези су хитно најавили предстојеће ослобађање својих цхатбот, Мицрософт је брзо склопио договор са OpenAI да у њих уложи десетине милијарди долара, а Гуглови инжењери су огласили аларм и почели да формулишу планове за заштиту свог сервиса за претрагу од конкуренције са неуронском мрежом.
Резиме: Када ChatGPT модел је представљен у новембру 2022. године, није било значајнијих технолошких напретка. Међутим, имао је згодан интерфејс за ангажовање корисника и отворен приступ, што је одмах изазвало огромну буку. Пошто је ово најважније питање у савременом свету, сви су одмах почели да се баве језичким моделима.
Прочитајте више о АИ:
Одрицање од одговорности
У складу са Смернице пројекта Труст, имајте на уму да информације дате на овој страници нису намењене и не треба да се тумаче као правни, порески, инвестициони, финансијски или било који други облик савета. Важно је да инвестирате само оно што можете приуштити да изгубите и да тражите независан финансијски савет ако сумњате. За додатне информације, предлажемо да погледате одредбе и услове, као и странице помоћи и подршке које пружа издавач или оглашивач. MetaversePost је посвећен тачном, непристрасном извештавању, али тржишни услови су подложни променама без претходне најаве.
О аутору
Дамир је вођа тима, менаџер производа и уредник у Metaverse Post, покривајући теме као што су АИ/МЛ, АГИ, ЛЛМ, Метаверсе и Web3-сродна поља. Његови чланци привлаче огромну публику од преко милион корисника сваког месеца. Чини се да је стручњак са 10 година искуства у СЕО и дигиталном маркетингу. Дамир се помиње у Масхабле, Виред, Cointelegraph, Тхе Нев Иоркер, Инсиде.цом, Ентрепренеур, БеИнЦрипто и друге публикације. Путује између УАЕ, Турске, Русије и ЗНД као дигитални номад. Дамир је стекао диплому физике, за коју верује да му је дало вештине критичког размишљања које су му потребне да буде успешан у свету интернета који се стално мења.
više чланака
Дамир је вођа тима, менаџер производа и уредник у Metaverse Post, покривајући теме као што су АИ/МЛ, АГИ, ЛЛМ, Метаверсе и Web3-сродна поља. Његови чланци привлаче огромну публику од преко милион корисника сваког месеца. Чини се да је стручњак са 10 година искуства у СЕО и дигиталном маркетингу. Дамир се помиње у Масхабле, Виред, Cointelegraph, Тхе Нев Иоркер, Инсиде.цом, Ентрепренеур, БеИнЦрипто и друге публикације. Путује између УАЕ, Турске, Русије и ЗНД као дигитални номад. Дамир је стекао диплому физике, за коју верује да му је дало вештине критичког размишљања које су му потребне да буде успешан у свету интернета који се стално мења.






