



बड़े भाषा मॉडल के बारे में आपको 8 बातें पता होनी चाहिए






संक्षेप में
बड़े भाषा मॉडल (एलएलएम) का उपयोग प्राकृतिक भाषा की बारीकियों का पता लगाने, पाठ को समझने और उत्पन्न करने के लिए मशीनों की क्षमता में सुधार करने और आवाज पहचान और मशीन अनुवाद जैसे कार्यों को स्वचालित करने के लिए किया जाता है।
एलएलएम के प्रबंधन का कोई आसान समाधान नहीं है, लेकिन वे इंसानों की तरह ही सक्षम हैं।
प्राकृतिक भाषा प्रसंस्करण के विकास और व्यवसाय में इसके उपयोग में वृद्धि के साथ, बड़े भाषा मॉडल में रुचि बढ़ रही है। इन मॉडलों का उपयोग प्राकृतिक भाषा की बारीकियों का पता लगाने, मशीनों को समझने और पाठ उत्पन्न करने की क्षमता में सुधार करने और ध्वनि पहचान और मशीन अनुवाद जैसे कार्यों को स्वचालित करने के लिए किया जाता है। यहां आठ आवश्यक चीजें हैं जो आपको बड़े भाषा मॉडल (एलएलएम) के बारे में जाननी चाहिए।

- एलएलएम अधिक "सक्षम" हैं क्योंकि लागत बढ़ती रहती है
- कैसे पर एक त्वरित नजर GPT प्रशिक्षण लागत बढ़ने पर मॉडल अनुकूलित हो जाते हैं
- एलएलएम बाहरी दुनिया के अभ्यावेदन का उपयोग करके बोर्ड गेम खेलना सीखते हैं
- एलएलएम के प्रबंधन का कोई आसान समाधान नहीं है
- विशेषज्ञों को यह समझाने में परेशानी होती है कि एलएलएम कैसे काम करता है
- एलएलएम इंसानों की तरह ही सक्षम हैं
- एलएलएम केवल "जैक-ऑफ-ऑल-ट्रेड्स" से अधिक होना चाहिए
- मॉडल पहले छापों के आधार पर लोगों की सोच से 'स्मार्ट' होते हैं
एलएलएम अधिक "सक्षम" हैं क्योंकि लागत बढ़ती रहती है
एलएलएम अनुमानित रूप से बढ़ती लागत के साथ अधिक "सक्षम" हो जाते हैं, यहां तक कि अच्छे नवाचारों के बिना भी। यहां मुख्य बात भविष्यवाणी है, जिसे लेख में दिखाया गया था GPT-4: पाँच से सात छोटे मॉडलों को अंतिम एक के 0.1% के बजट के साथ पढ़ाया गया, और फिर इसके आधार पर एक विशाल मॉडल के लिए एक भविष्यवाणी की गई। एक विशिष्ट कार्य के उप-नमूने पर गड़बड़ी और मेट्रिक्स के सामान्य मूल्यांकन के लिए, ऐसी भविष्यवाणी बहुत सटीक थी। यह भविष्यवाणी उन व्यवसायों और संगठनों के लिए महत्वपूर्ण है जो अपने संचालन के लिए एलएलएम पर भरोसा करते हैं, क्योंकि वे तदनुसार बजट बना सकते हैं और भविष्य के खर्चों की योजना बना सकते हैं। हालांकि, यह ध्यान रखना महत्वपूर्ण है कि बढ़ती लागत से क्षमताओं में सुधार हो सकता है, सुधार की दर अंततः स्थिर हो सकती है, जिससे आगे बढ़ने के लिए नए नवाचारों में निवेश करना आवश्यक हो जाता है।
कैसे पर एक त्वरित नजर GPT प्रशिक्षण लागत बढ़ने पर मॉडल अनुकूलित हो जाते हैं
हालांकि, विशिष्ट महत्वपूर्ण कौशल बढ़ने के उप-उत्पाद के रूप में अप्रत्याशित रूप से उभरने लगते हैं प्रशिक्षण लागत (लंबा प्रशिक्षण, अधिक डेटा, बड़ा मॉडल) - यह भविष्यवाणी करना लगभग असंभव है कि मॉडल कब कुछ कार्य करना शुरू करेंगे। हमने अपने में विषय को और अधिक गहराई से खोजा लेख के विकास के इतिहास के बारे में GPT मॉडल। चित्र विभिन्न कार्यों में मॉडलों की गुणवत्ता में वृद्धि के वितरण को दर्शाता है। केवल बड़े मॉडल ही विभिन्न कार्य करना सीख सकते हैं। यह ग्राफ आकार बढ़ाने के महत्वपूर्ण प्रभाव पर प्रकाश डालता है GPT मॉडल विभिन्न कार्यों में उनके प्रदर्शन पर। हालांकि, यह ध्यान रखना महत्वपूर्ण है कि यह बढ़े हुए कम्प्यूटेशनल संसाधनों और पर्यावरणीय प्रभाव की कीमत पर आता है।
एलएलएम बाहरी दुनिया के अभ्यावेदन का उपयोग करके बोर्ड गेम खेलना सीखते हैं
एलएलएम अक्सर सीखते हैं और बाहरी दुनिया के प्रतिनिधित्व का उपयोग करते हैं। यहाँ कई उदाहरण हैं, और यहाँ उनमें से एक है: मॉडलों को प्रशिक्षित किया व्यक्तिगत चालों के विवरण के आधार पर बोर्ड गेम खेलना, खेल के मैदान की तस्वीर देखे बिना, प्रत्येक चाल पर बोर्ड की स्थिति का आंतरिक प्रतिनिधित्व सीखना। फिर इन आंतरिक अभ्यावेदनों का उपयोग किया जा सकता है भविष्य की भविष्यवाणी करें चालें और परिणाम, मॉडल को उच्च स्तर पर गेम खेलने की अनुमति देते हैं। अभ्यावेदन सीखने और उपयोग करने की यह क्षमता एक कुंजी है मशीन सीखने का पहलू और कृत्रिम बुद्धि।
एलएलएम के प्रबंधन का कोई आसान समाधान नहीं है
एलएलएम व्यवहार को नियंत्रित करने के लिए कोई विश्वसनीय तरीका नहीं है। हालांकि विभिन्न समस्याओं को समझने और कम करने में कुछ प्रगति हुई है ChatGPT और GPT-4 फीडबैक की मदद से), इस बात पर कोई सहमति नहीं है कि क्या हम उन्हें हल कर सकते हैं। इस बात की चिंता बढ़ रही है कि भविष्य में जब और भी बड़ी प्रणालियाँ बनाई जाएंगी तो यह एक बड़ी, संभावित विनाशकारी समस्या बन जाएगी। इसलिए, शोधकर्ता यह सुनिश्चित करने के लिए नए तरीकों की खोज कर रहे हैं कि एआई सिस्टम मानवीय मूल्यों और लक्ष्यों, जैसे मूल्य संरेखण और इनाम इंजीनियरिंग के साथ संरेखित हों। हालाँकि, इसकी गारंटी देना एक चुनौतीपूर्ण कार्य बना हुआ है एलएलएम की सुरक्षा और विश्वसनीयता जटिल वास्तविक दुनिया के परिदृश्यों में।
विशेषज्ञों को यह समझाने में परेशानी होती है कि एलएलएम कैसे काम करता है
विशेषज्ञ अभी तक एलएलएम के आंतरिक कामकाज की व्याख्या नहीं कर सकते हैं। कोई भी तकनीक हमें किसी भी संतोषजनक तरीके से यह बताने की अनुमति नहीं देगी कि कोई परिणाम उत्पन्न करते समय मॉडल किस प्रकार के ज्ञान, तर्क या लक्ष्यों का उपयोग करता है। व्याख्यात्मकता की यह कमी एलएलएम के निर्णयों की विश्वसनीयता और निष्पक्षता के बारे में चिंता पैदा करती है, विशेष रूप से आपराधिक न्याय या क्रेडिट स्कोरिंग जैसे उच्च-दांव वाले अनुप्रयोगों में। यह अधिक पारदर्शी और जवाबदेह एआई मॉडल विकसित करने के लिए और अधिक शोध की आवश्यकता पर भी प्रकाश डालता है।
एलएलएम इंसानों की तरह ही सक्षम हैं
हालाँकि एलएलएम को मुख्य रूप से प्रशिक्षित किया जाता है पाठ लिखते समय मानवीय व्यवहार का अनुकरण करेंवे कई कार्यों में हमसे आगे निकलने की क्षमता रखते हैं। इसे शतरंज या गो खेलते समय पहले से ही देखा जा सकता है। यह विशाल मात्रा में डेटा का विश्लेषण करने और उस विश्लेषण के आधार पर उस गति से निर्णय लेने की उनकी क्षमता के कारण है जिसकी तुलना मनुष्य नहीं कर सकते। हालाँकि, एलएलएम में अभी भी मनुष्यों की तरह रचनात्मकता और अंतर्ज्ञान का अभाव है, जो उन्हें कई कार्यों के लिए कम उपयुक्त बनाता है।
एलएलएम केवल "जैक-ऑफ-ऑल-ट्रेड्स" से अधिक होना चाहिए
एलएलएम को अपने रचनाकारों के मूल्यों या इंटरनेट से चयन में एन्कोड किए गए मूल्यों को व्यक्त नहीं करना चाहिए। उन्हें रूढ़िवादिता या षड्यंत्र के सिद्धांतों को नहीं दोहराना चाहिए या किसी को ठेस पहुँचाने का प्रयास नहीं करना चाहिए। इसके बजाय, एलएलएम को सांस्कृतिक और सामाजिक अंतरों का सम्मान करते हुए अपने उपयोगकर्ताओं को निष्पक्ष और तथ्यात्मक जानकारी प्रदान करने के लिए डिज़ाइन किया जाना चाहिए। इसके अतिरिक्त, उन्हें यह सुनिश्चित करने के लिए नियमित परीक्षण और निगरानी से गुजरना चाहिए कि वे इन मानकों को पूरा करते रहें।
मॉडल पहले छापों के आधार पर लोगों की सोच से 'स्मार्ट' होते हैं
प्रथम छापों के आधार पर किसी मॉडल की क्षमता का अनुमान अक्सर भ्रामक होता है। बहुत बार, आपको सही संकेत के साथ आने की जरूरत है, एक मॉडल का सुझाव दें, और शायद उदाहरण दिखाएं, और यह बहुत बेहतर तरीके से सामना करना शुरू कर देगा। यानी यह पहली नज़र में लगने की तुलना में "होशियार" है। इसलिए, यह महत्वपूर्ण है कि मॉडल को एक उचित अवसर दिया जाए और उसे सर्वोत्तम प्रदर्शन करने के लिए आवश्यक संसाधन प्रदान किए जाएं। सही दृष्टिकोण के साथ, अपर्याप्त प्रतीत होने वाले मॉडल भी हमें अपनी क्षमताओं से आश्चर्यचकित कर सकते हैं।
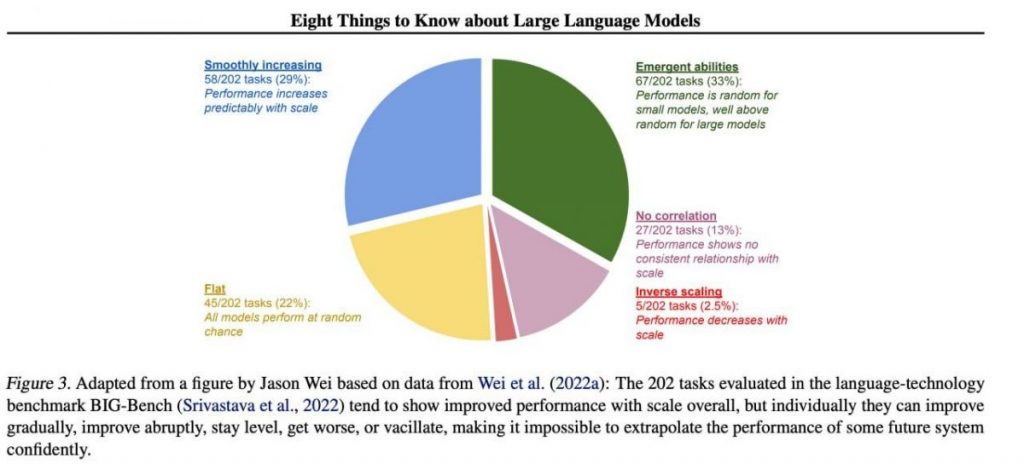
यदि हम बिग-बेंच डेटासेट से 202 कार्यों के नमूने पर ध्यान केंद्रित करते हैं (इसे विशेष रूप से परीक्षण करना कठिन बनाया गया था) भाषा मॉडल से और तक), तो एक नियम के रूप में (औसतन), मॉडल बढ़ते पैमाने के साथ गुणवत्ता में वृद्धि दिखाते हैं, लेकिन व्यक्तिगत रूप से, कार्यों में मेट्रिक्स हो सकते हैं:
- धीरे-धीरे सुधार,
- अत्यधिक सुधार करें,
- अपरिवर्तित ही रहेंगे,
- कमी,
- कोई संबंध न दिखाएं।
यह सब भविष्य की किसी भी प्रणाली के प्रदर्शन को आत्मविश्वास से अलग करने की असंभवता की ओर ले जाता है। हरा हिस्सा विशेष रूप से दिलचस्प है - यह ठीक वही है जहां गुणवत्ता संकेतक बिना किसी कारण के तेजी से ऊपर जाते हैं।
एआई के बारे में और पढ़ें:
Disclaimer
साथ लाइन में ट्रस्ट परियोजना दिशानिर्देश, कृपया ध्यान दें कि इस पृष्ठ पर दी गई जानकारी का कानूनी, कर, निवेश, वित्तीय या किसी अन्य प्रकार की सलाह के रूप में व्याख्या करने का इरादा नहीं है और न ही इसकी व्याख्या की जानी चाहिए। यह महत्वपूर्ण है कि केवल उतना ही निवेश करें जितना आप खो सकते हैं और यदि आपको कोई संदेह हो तो स्वतंत्र वित्तीय सलाह लें। अधिक जानकारी के लिए, हम नियम और शर्तों के साथ-साथ जारीकर्ता या विज्ञापनदाता द्वारा प्रदान किए गए सहायता और समर्थन पृष्ठों का संदर्भ लेने का सुझाव देते हैं। MetaversePost सटीक, निष्पक्ष रिपोर्टिंग के लिए प्रतिबद्ध है, लेकिन बाज़ार की स्थितियाँ बिना सूचना के परिवर्तन के अधीन हैं।
के बारे में लेखक
दामिर टीम लीडर, उत्पाद प्रबंधक और संपादक हैं Metaverse Postएआई/एमएल, एजीआई, एलएलएम, मेटावर्स और जैसे विषयों को कवर करता है Web3-संबंधित क्षेत्रों। उनके लेख हर महीने दस लाख से अधिक उपयोगकर्ताओं को आकर्षित करते हैं। ऐसा प्रतीत होता है कि वह SEO और डिजिटल मार्केटिंग में 10 वर्षों के अनुभव वाला एक विशेषज्ञ है। दामिर का उल्लेख मैशबल, वायर्ड, में किया गया है Cointelegraph, द न्यू यॉर्कर, Inside.com, एंटरप्रेन्योर, BeInCrypto, और अन्य प्रकाशन। वह एक डिजिटल खानाबदोश के रूप में संयुक्त अरब अमीरात, तुर्की, रूस और सीआईएस के बीच यात्रा करता है। दामिर ने भौतिकी में स्नातक की डिग्री हासिल की, उनका मानना है कि इससे उन्हें इंटरनेट के लगातार बदलते परिदृश्य में सफल होने के लिए आवश्यक महत्वपूर्ण सोच कौशल प्राप्त हुआ है।
और अधिक लेख
दामिर टीम लीडर, उत्पाद प्रबंधक और संपादक हैं Metaverse Postएआई/एमएल, एजीआई, एलएलएम, मेटावर्स और जैसे विषयों को कवर करता है Web3-संबंधित क्षेत्रों। उनके लेख हर महीने दस लाख से अधिक उपयोगकर्ताओं को आकर्षित करते हैं। ऐसा प्रतीत होता है कि वह SEO और डिजिटल मार्केटिंग में 10 वर्षों के अनुभव वाला एक विशेषज्ञ है। दामिर का उल्लेख मैशबल, वायर्ड, में किया गया है Cointelegraph, द न्यू यॉर्कर, Inside.com, एंटरप्रेन्योर, BeInCrypto, और अन्य प्रकाशन। वह एक डिजिटल खानाबदोश के रूप में संयुक्त अरब अमीरात, तुर्की, रूस और सीआईएस के बीच यात्रा करता है। दामिर ने भौतिकी में स्नातक की डिग्री हासिल की, उनका मानना है कि इससे उन्हें इंटरनेट के लगातार बदलते परिदृश्य में सफल होने के लिए आवश्यक महत्वपूर्ण सोच कौशल प्राप्त हुआ है।






