



The Evolution of Chatbots no T9-Era un GPT-1 uz ChatGPT






Pēdējā laikā gandrīz katru dienu tiekam bombardēti ar ziņām par jaunākajiem rekordiem, ko pārspējuši liela mēroga neironu tīkli, un to, kāpēc gandrīz neviens darbs nav drošs. Tomēr ļoti maz cilvēku zina, kā neironu tīkli patīk ChatGPT faktiski darbojas.
Tātad, atpūtieties. Pagaidām neraudiet par savām darba izredzēm. Šajā ziņojumā mēs izskaidrosim visu, kas jāzina par neironu tīkliem, lai ikviens to varētu saprast.

Brīdinājums pirms sākam: šis gabals ir sadarbība. Visu tehnisko daļu uzrakstīja AI speciālists, kurš ir labi pazīstams AI pūļa vidū.
Tā kā neviens vēl nav uzrakstījis padziļinātu rakstu par to, kā ChatGPT darbiem, kas, runājot nespeciālisti, izskaidro neironu tīklu smalkumus un smalkumus, mēs nolēmām to izdarīt jūsu vietā. Mēs esam centušies saglabāt šo ziņu pēc iespējas vienkāršāku, lai lasītāji, lasot šo ziņu, varētu gūt vispārēju izpratni par valodu neironu tīklu principiem. Mēs izpētīsim, kā valodu modeļi strādāt tur, kā neironu tīkli attīstījās, lai iegūtu pašreizējās iespējas, un kāpēc ChatGPTEksplozīvā popularitāte pārsteidza pat tā veidotājus.
Sāksim ar pamatiem. Saprast ChatGPT no tehniskā viedokļa mums vispirms ir jāsaprot, kas tas nav. Tas nav Marvel Comics Jarvis; tā nav racionāla būtne; tas nav džins. Sagatavojieties šokētam: ChatGPT patiesībā ir jūsu mobilā tālruņa T9 ar steroīdiem! Jā, tā ir: Zinātnieki abas šīs tehnoloģijas dēvē par "Valodu modeļi." Viss, ko dara neironu tīkli, ir uzminēt, kuram vārdam vajadzētu nākt.
Sākotnējā T9 tehnoloģija tikai paātrināja tālruņa numuru sastādīšanu ar spiedpogu, uzminot pašreizējo ievadi, nevis nākamo vārdu. Tomēr tehnoloģija attīstījās, un līdz viedtālruņu laikmetam 2010. gadu sākumā tas spēja ņemt vērā kontekstu un vārdu pirms tam, pievienot pieturzīmes un piedāvāt vārdu izlasi, ko varētu izmantot tālāk. Tieši tādu analoģiju mēs veidojam ar šādu “uzlabotu” T9 versiju jeb automātisko labošanu.
Rezultātā gan T9 viedtālruņa tastatūrā, gan ChatGPT ir apmācīti atrisināt smieklīgi vienkāršu uzdevumu: paredzot nākamo vārdu. To sauc par “valodas modelēšanu”, un tas notiek, kad tiek pieņemts lēmums par to, kas jāraksta tālāk, pamatojoties uz esošo tekstu. Lai veiktu šādas prognozes, valodu modeļiem jādarbojas, pamatojoties uz konkrētu vārdu rašanās varbūtību. Galu galā jūs būtu kaitinoši, ja tālruņa automātiskā aizpilde vienkārši izmestu jums pilnīgi nejaušus vārdus ar tādu pašu varbūtību.
Skaidrības labad iedomāsimies, ka saņemat ziņu no drauga. Tas saka: "Kādi ir jūsu plāni vakaram?" Atbildot uz to, jūs sākat rakstīt: "Es došos uz...", un šeit parādās T9. Tas var radīt pilnīgi absurdas lietas, piemēram, "Es došos uz Mēnesi", nav nepieciešams sarežģīts valodas modelis. Labi viedtālruņu automātiskās pabeigšanas modeļi piedāvā daudz atbilstošākus vārdus.
Tātad, kā T9 zina, kuri vārdi, visticamāk, sekos jau rakstītajam tekstam un kuriem acīmredzami nav jēgas? Lai atbildētu uz šo jautājumu, vispirms ir jāizpēta visvienkāršākā darbības pamatprincipi neironu tīkli.
Kā AI modeļi prognozē nākamo vārdu
Sāksim ar vienkāršāku jautājumu: kā jūs prognozējat dažu lietu savstarpējo atkarību no citām? Pieņemsim, ka mēs vēlamies iemācīt datoram paredzēt cilvēka svaru, pamatojoties uz viņa augstumu — kā mums vajadzētu rīkoties? Vispirms mums vajadzētu identificēt interesējošās jomas un pēc tam apkopot datus, pēc kuriem meklēt interešu atkarības, un pēc tam mēģināt “apmācīt” kādu matemātisko modeli lai meklētu modeļus šajos datos.
Vienkārši sakot, T9 vai ChatGPT ir tikai gudri izvēlēti vienādojumi, kas mēģina to darīt pareģot vārds (Y), kura pamatā ir iepriekšējo vārdu kopa (X), kas ievadīta modeļa ievadē. Trenējoties a valodas modelis datu kopā galvenais uzdevums ir izvēlēties koeficientus šiem x, kas patiesi atspoguļo kaut kādu atkarību (kā mūsu piemērā ar augumu un svaru). Un ar lieliem modeļiem mēs iegūsim labāku izpratni par tiem, kuriem ir liels parametru skaits. Jomā mākslīgais intelekts, tos dēvē par lielajiem valodu modeļiem vai saīsināti LLM. Kā mēs redzēsim vēlāk, liels modelis ar daudziem parametriem ir būtisks laba teksta ģenerēšanai.
Starp citu, ja jūs domājat, kāpēc mēs pastāvīgi runājam par "nākamā vārda prognozēšanu". ChatGPT ātri atbild ar veselām teksta rindkopām, atbilde ir vienkārša. Protams, valodu modeļi var bez grūtībām ģenerēt garus tekstus, taču viss process notiek vārds pa vārdam. Pēc katra jauna vārda ģenerēšanas modelis vienkārši atkārtoti izpilda visu tekstu ar jauno vārdu, lai ģenerētu nākamo vārdu. Process atkārtojas atkal un atkal, līdz saņemat visu atbildi.
Kāpēc mēs turpinām mēģināt atrast “pareizos” vārdus konkrētajam tekstam?
Valodas modeļi mēģina paredzēt dažādu vārdu varbūtību, kas var rasties noteiktā tekstā. Kāpēc tas ir nepieciešams, un kāpēc jūs nevarat turpināt meklēt “vispareizāko” vārdu? Izmēģināsim vienkāršu spēli, lai ilustrētu, kā šis process darbojas.
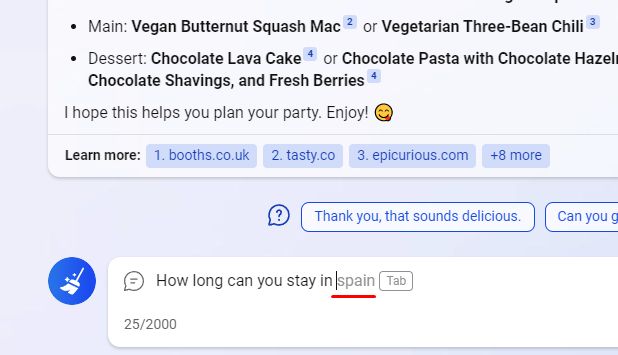
Noteikumi ir šādi: iesaku jums turpināt teikumu: “ASV 44. prezidents (un pirmais afroamerikānis šajā amatā) ir Baraks…”. Kādam vārdam vajadzētu būt tālāk? Kāda ir iespējamība, ka tas notiks?
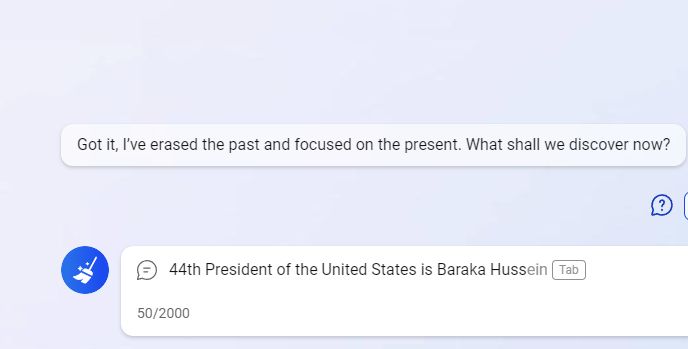
Ja jūs ar 100% pārliecību paredzējāt, ka nākamais vārds būs “Obama”, jūs kļūdījāties! Un runa šeit nav par to, ka ir vēl viens mītisks Baraks; tas ir daudz triviālāk. Oficiālajos dokumentos parasti tiek izmantots prezidenta pilns vārds. Tas nozīmē, ka pēc Obamas vārda būtu viņa otrais vārds Huseins. Tātad mūsu teikumā pareizi apmācītam valodas modelim vajadzētu paredzēt, ka nākamais vārds būs “Obama” tikai ar nosacīto varbūtību 90% un atlikušos 10%, ja tekstu turpinās “Huseins” (pēc tam Obama sekot ar varbūtību tuvu 100%).
Un tagad mēs nonākam pie intriģējoša valodu modeļu aspekta: tie nav imūni pret radošām svītrām! Faktiski, ģenerējot katru nākamo vārdu, šādi modeļi to izvēlas “izlases” veidā, it kā metot kauli. Dažādu vārdu “izkrišanas” varbūtība vairāk vai mazāk atbilst varbūtībām, ko piedāvā modelī ievietotie vienādojumi. Tie ir iegūti no milzīgā dažādu tekstu klāsta, kas tika ievadīts modelī.
Izrādās, ka modele uz vieniem un tiem pašiem lūgumiem var reaģēt dažādi, gluži kā dzīvs cilvēks. Pētnieki parasti ir mēģinājuši piespiest neironus vienmēr izvēlēties "visticamāko" nākamo vārdu, taču, lai gan tas šķiet racionāli no virsmas, šādi modeļi patiesībā darbojas sliktāk. Šķiet, ka laba nejaušības deva ir izdevīga, jo tā palielina atbilžu mainīgumu un kvalitāti.
Mūsu valodai ir unikāla struktūra ar atšķirīgiem noteikumu un izņēmumu kopumiem. Vārdiem, kas parādās teikumā, ir atskaņa un iemesls, tie nerodas nejauši. Ikviens neapzināti apgūst lietotās valodas noteikumus savos agrīnajos veidošanās gados.
Pienācīgam modelim ir jāņem vērā valodas plašā apraksta diapazons. Modeļa spēja radīt vēlamos rezultātus ir atkarīgs no tā, cik precīzi tā aprēķina vārdu varbūtības, pamatojoties uz konteksta smalkumiem (iepriekšējā teksta sadaļa, kurā izskaidrots apstāklis).
Kopsavilkums: kopš 9. gadu sākuma viedtālruņu funkcionalitātē “T2010/Autofill” ir ieviesti vienkārši valodu modeļi, kas ir vienādojumu kopums, kas apmācīts, izmantojot milzīgu datu daudzumu, lai paredzētu nākamo vārdu, pamatojoties uz ievades avota tekstu.
GPT-1: Nozares uzspridzināšana
Atteiksimies no T9 modeļiem. Kamēr jūs, iespējams, lasāt šo rakstu mācies par ChatGPT, pirmkārt, mums ir jāapspriež pirmsākumiem GPT modeļu ģimene.
GPT apzīmē "ģeneratīvu iepriekš apmācītu transformatoru", savukārt neironu tīklu arhitektūra, ko izstrādājuši Google inženieri 2017. gadā ir pazīstams kā Transformators. Transformators ir universāls skaitļošanas mehānisms, kas pieņem secību (datu) kopu kā ievadi un rada to pašu secību kopu, bet citā formā, ko mainījis kāds algoritms.
Transformatora radīšanas nozīmīgumu var redzēt tajā, cik agresīvi tas tika pieņemts un pielietots visās mākslīgā intelekta (AI) jomās: tulkošanā, attēla, skaņas un video apstrādē. Mākslīgā intelekta (AI) nozare piedzīvoja spēcīgu satricinājumu, pārejot no tā sauktās “AI stagnācijas” uz strauju attīstību un stagnācijas pārvarēšanu.
Transformatora galveno spēku veido viegli mērogojami moduļi. Ja tiek lūgts apstrādāt lielu teksta daudzumu vienlaikus, vecie, pirmstransformācijas valodas modeļi palēninās. No otras puses, transformatoru neironu tīkli ar šo uzdevumu tiek galā daudz labāk.
Agrāk ievades dati bija jāapstrādā secīgi vai pa vienam. Modelis nesaglabātu datus: ja tas darbotos ar vienas lappuses stāstījumu, tas aizmirstu tekstu pēc tā izlasīšanas. Tikmēr Transformators ļauj skatīt visu uzreiz, ražojot ievērojami satriecošāki rezultāti.
Tas ļāva panākt izrāvienu tekstu apstrādē, izmantojot neironu tīklus. Rezultātā modelis vairs neaizmirst: tas atkārtoti izmanto iepriekš uzrakstīto materiālu, labāk izprot kontekstu un, pats galvenais, spēj izveidot savienojumus starp ārkārtīgi lieliem datu apjomiem, savienojot vārdus pārī.
Kopsavilkums: GPT-1, kas debitēja 2018. gadā, parādīja, ka neironu tīkls var radīt tekstus, izmantojot transformatora dizainu, kas ir ievērojami uzlabojis mērogojamību un efektivitāti. Ja būtu iespējams palielināt valodu modeļu daudzumu un sarežģītību, tas radītu ievērojamu rezervi.
GPT-2: Lielo valodu modeļu laikmets
Valodu modeļi nav iepriekš īpaši jāmarķē, un tos var “pabarot” ar jebkādiem teksta datiem, padarot tos ārkārtīgi elastīgus. Ja padomājat, šķiet saprātīgi, ka mēs vēlamies izmantot tā spējas. Jebkurš teksts, kas jebkad ir ticis rakstīts, kalpo kā gatavi apmācības dati. Tā kā jau ir tik daudz secību, kas atbilst tipam “daudz dažu vārdu un frāžu => nākamais vārds pēc tiem”, tas nav pārsteidzoši.
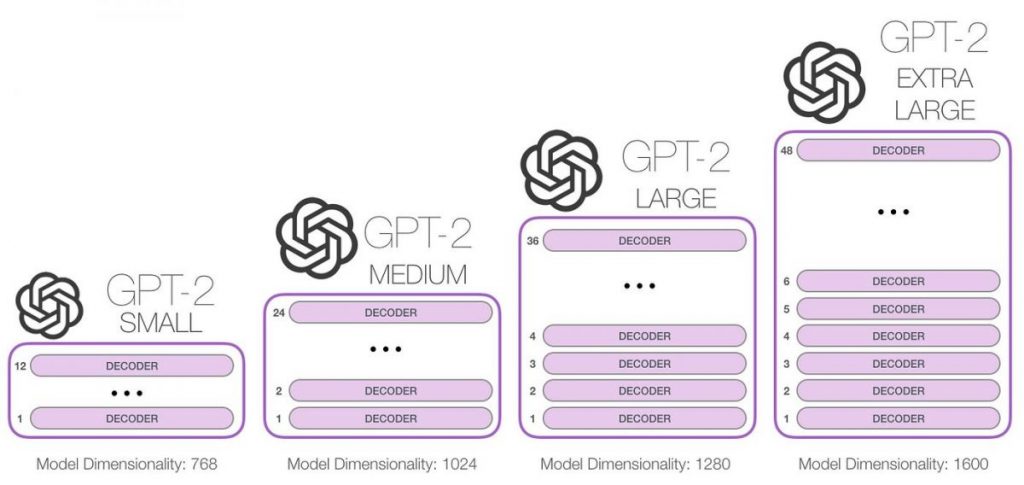
Tagad paturēsim prātā arī to, ka Transformeru tehnoloģija tika pārbaudīta GPT-1 izrādījās diezgan veiksmīgs mērogošanas ziņā: tas ir ievērojami efektīvāks nekā tā priekšgājēji, apstrādājot lielus datu apjomus. Izrādās, ka pētnieki no OpenAI 2019. gadā nonāca pie tāda paša secinājuma: “Ir pienācis laiks samazināt dārgus valodu modeļus!”
Jūsu darbs IR Klientu apkalpošana apmācības datu kopa un modelis lielums, jo īpaši tika izvēlēti kā divas būtiskas jomas, kurās GPT-2 bija radikāli jāuzlabo.
Tā kā tajā laikā nebija milzīgu, kvalitatīvu publisko teksta datu kopu, kas īpaši izstrādāta valodu modeļu apmācībai, katrai AI ekspertu komandai bija pašai jāmanipulē ar datiem. The OpenAI Pēc tam cilvēki nolēma apmeklēt Reddit, vispopulārāko forumu angļu valodā, un izvilkt visas hipersaites no katras ziņas, kurām bija vairāk nekā trīs atzīmju Patīk. Šo saišu bija gandrīz 8 miljoni, un lejupielādētie teksti kopā svēra 40 terabaitus.
Cik parametru vienādojums apraksta lielāko GPT-2 modelis 2019 ir? Varbūt simts tūkstoši vai daži miljoni? Nu, iesim vēl tālāk: formula saturēja līdz 1.5 miljardiem šādu parametru. Tik daudz skaitļu ierakstīšanai failā un saglabāšanai datorā būs nepieciešami 6 terabaiti. Modelim nav jāiegaumē šis teksts kopumā, tāpēc, no vienas puses, tas ir daudz mazāks nekā kopējais teksta datu masīva apjoms, uz kura tika apmācīts modelis; tai pietiek vienkārši atrast kādas atkarības (rakstus, noteikumus), ko var izolēt no cilvēku rakstītiem tekstiem.
Jo labāk modelis prognozē varbūtību un jo vairāk parametru tas satur, jo sarežģītāks vienādojums ir iekļauts modelī. Tas nodrošina ticamu tekstu. Turklāt, GPT-2 modelis sāka darboties tik labi, ka OpenAI pētnieki drošības apsvērumu dēļ pat nevēlējās modeli atklātībā atklāt.
Ļoti interesanti, ka modelei kļūstot lielākai, tai pēkšņi sāk parādīties jaunas īpašības (piemēram, spēja rakstīt sakarīgas, jēgpilnas esejas, nevis vienkārši pa telefonu diktēt nākamo vārdu).
Šajā brīdī notiek pārmaiņas no kvantitātes uz kvalitāti. Turklāt tas notiek pilnīgi nelineāri. Piemēram, trīskārtīgam parametru skaita palielinājumam no 115 līdz 350 miljoniem nav manāmas ietekmes uz modeļa spēju precīzi atrisināt problēmas. Taču divkāršs palielinājums līdz 700 miljoniem rada kvalitatīvu lēcienu, kur neironu tīkls “ierauga gaismu” un sāk pārsteigt ikvienu ar savu spēju izpildīt uzdevumus.
Kopsavilkums: 2019. gadā tika ieviests GPT-2, kas 10 reizes pārspēja savu priekšgājēju modeļa izmēra (parametru skaita) un apmācības teksta datu apjoma ziņā. Pateicoties šim kvantitatīvajam progresam, modelis neprognozējami ieguva kvalitatīvi jaunus talantus, piemēram, spēju rakstīt garas esejas ar skaidru nozīmi un risināt izaicinošas problēmas, kas prasa pasaules uzskatu pamatus.
GPT-3: Gudrs kā ellē
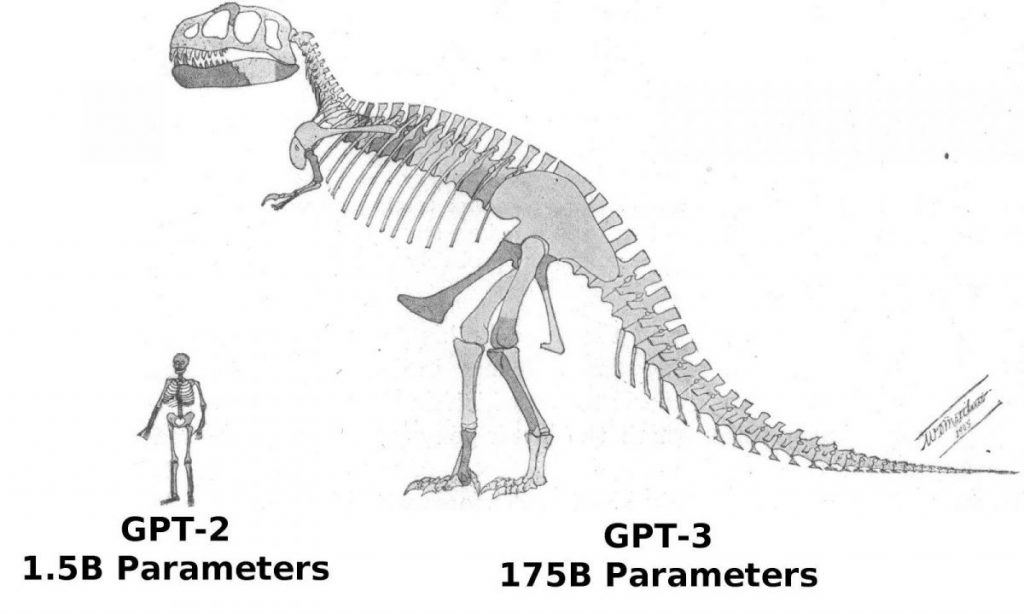
Kopumā 2020. gada izlaidums GPT-3, sērijas nākamā paaudze, jau var lepoties ar 116 reižu vairāk parametru — līdz 175 miljardiem un pārsteidzošiem 700 terabaitiem.
Jūsu darbs IR Klientu apkalpošana GPT-3 apmācību datu kopa arī tika paplašināta, lai gan ne tik krasi. Tas ir palielinājies gandrīz 10 reizes līdz 420 gigabaitiem, un tagad tajā ir daudz grāmatu, Wikipedia raksti un citi teksti no citām vietnēm. Cilvēkam būtu nepieciešami aptuveni 50 gadi nepārtrauktas lasīšanas, padarot to par neiespējamu varoņdarbu.
Jūs uzreiz pamanāt intriģējošu atšķirību: atšķirībā no GPT-2, pats modelis tagad ir par 700 GB lielāks nekā viss apmācības teksta masīvs (420 GB). Savā ziņā tas izrādās paradokss: šajā gadījumā, kad “neirobrain” pēta neapstrādātus datus, tas ģenerē informāciju par dažādām savstarpējām atkarībām, kas ir apjomīgākas nekā sākotnējie dati.
Modeļa vispārināšanas rezultātā tas tagad spēj ekstrapolēt vēl veiksmīgāk nekā iepriekš un ir sekmīgs pat teksta ģenerēšanas uzdevumos, kas apmācības laikā radās reti vai nemaz. Tagad jums nav jāmāca modelim, kā risināt noteiktu problēmu; pietiek tos aprakstīt un sniegt dažus piemērus, un GPT-3 uzreiz iemācīsies.
Jūsu darbs IR Klientu apkalpošana "Universālās smadzenes" formā GPT-3 galu galā uzvarēja daudzus agrākos specializētos modeļus. Piemēram, GPT-3 sāka tulkot tekstus no franču vai vācu valodas ātrāk un precīzāk nekā jebkuri iepriekš speciāli šim nolūkam izveidotie neironu tīkli. Kā? Ļaujiet man atgādināt, ka mēs apspriežam lingvistisko modeli, kura vienīgais mērķis bija mēģināt paredzēt sekojošo vārdu dotajā tekstā.
Vēl pārsteidzošāk, GPT-3 spēja iemācīties pats... matemātiku! Tālāk redzamā diagramma parāda, cik labi neironu tīkli veic uzdevumus, tostarp saskaitīšanu un atņemšanu, kā arī veselu skaitļu reizināšanu līdz pieciem cipariem ar dažādu parametru skaitu. Kā redzat, neironu tīkli pēkšņi sāk "varēt" matemātikā, pārejot no modeļiem ar 10 miljardiem parametriem uz modeļiem ar 100 miljardiem.
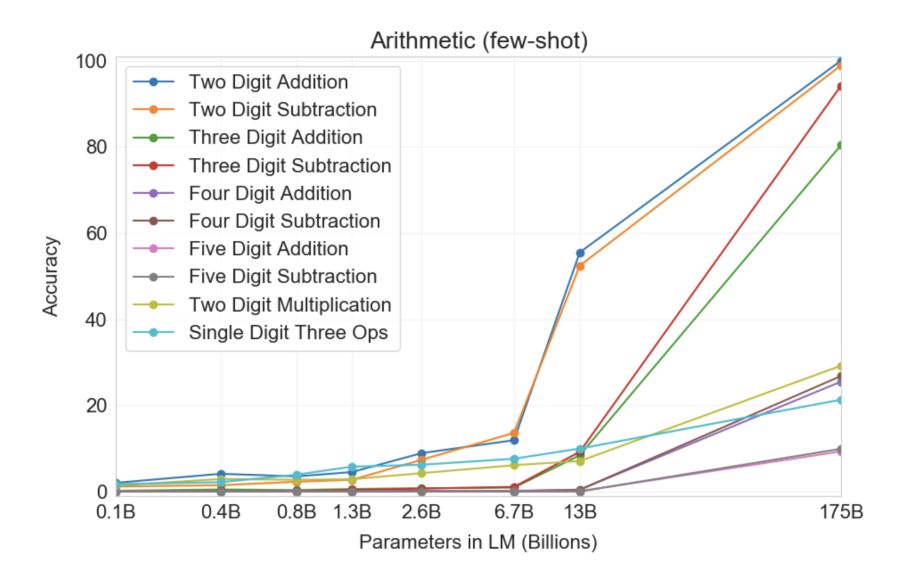
Iepriekš minētās diagrammas intriģējošākā iezīme ir tāda, ka sākotnēji nekas nemainās, palielinoties modeļa izmēram (no kreisās uz labo), bet pēkšņi p reizes! Notiek kvalitatīva maiņa, un GPT-3 sāk “saprast”, kā atrisināt noteiktu problēmu. Neviens nav pārliecināts par to, kā, kas un kāpēc tas darbojas. Tomēr šķiet, ka tas darbojas daudzās citās grūtībās, kā arī matemātikā.
Iepriekš minētās diagrammas intriģējošākā iezīme ir tāda, ka, palielinoties modeļa izmēram, vispirms šķiet, ka nekas nemainās, un pēc tam, GPT-3 veic kvalitatīvu lēcienu un sāk “saprast”, kā atrisināt kādu konkrētu jautājumu.
Zemāk redzamais gifs vienkārši parāda, kā modelī, pieaugot parametru skaitam, “dīgst” jaunas spējas, kuras neviens apzināti nebija ieplānojis:
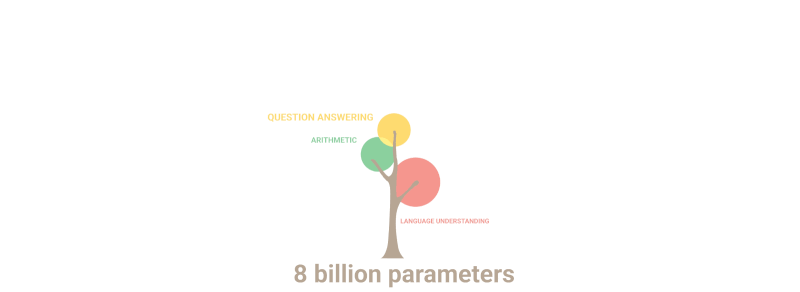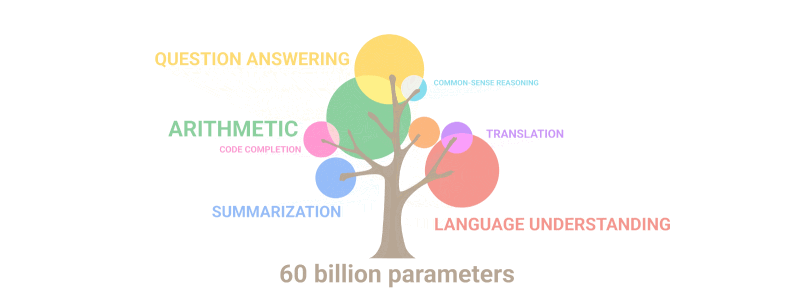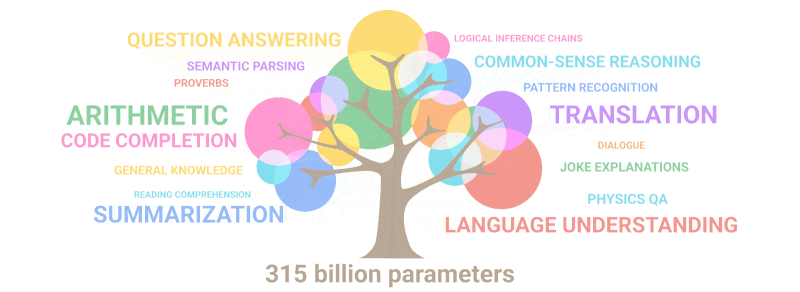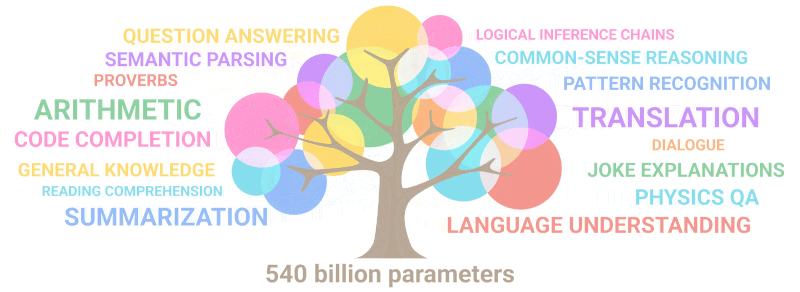
Kopsavilkums: Runājot par parametriem, 2020.g GPT-3 bija 100 reizes lielāks nekā tā priekšgājējs, savukārt apmācības teksta dati bija 10 reizes lielāki. Modelis atkal iemācījās tulkot no citām valodām, veikt aritmētiku, veikt vienkāršu programmēšanu, secīgi spriest un daudz ko citu, pateicoties kvantitātes pieaugumam, kas pēkšņi paaugstināja kvalitāti.
GPT-3.5 (NorādītGPT): Modelis ir apmācīts, lai būtu drošs un netoksisks
Patiesībā valodu modeļu paplašināšana negarantē, ka tā reaģēs uz jautājumiem tā, kā lietotāji to vēlas. Patiesībā, kad mēs iesniedzam pieprasījumu, mēs bieži domājam par vairākiem neizteiktiem terminiem, kas cilvēku saziņā tiek uzskatīti par patiesiem.
Tomēr, godīgi sakot, valodu modeļi nav ļoti tuvi cilvēku modeļiem. Tādējādi viņiem bieži ir jādomā par jēdzieniem, kas cilvēkiem šķiet vienkārši. Viens no šādiem ieteikumiem ir frāze "domāsim soli pa solim". Būtu lieliski, ja modeļi saprastu vai ģenerētu konkrētākus un atbilstošākus norādījumus no pieprasījuma un tos ievērotu precīzāk, it kā paredzot, kā cilvēks uzvedīsies.
Fakts, ka GPT-3 ir apmācīts tikai paredzēt nākamo vārdu masveida tekstu krājumā no interneta, tiek rakstīts daudz dažādu lietu, veicina šādu “noklusējuma” spēju trūkumu. Cilvēki vēlas, lai mākslīgais intelekts sniegtu atbilstošu informāciju, vienlaikus saglabājot atbildes drošas un netoksiskas.
Kad pētnieki nedaudz pārdomāja šo jautājumu, kļuva skaidrs, ka modeļa atribūti “precizitāte un lietderība” un “nekaitīgums un netoksiskums” dažkārt bija pretrunā. Galu galā modelis, kas noregulēts uz maksimālu nekaitīgumu, reaģēs uz jebkuru uzvedni ar “Atvainojiet, es uztraucos, ka mana atbilde var aizskart kādu internetā”. Precīzam modelim vajadzētu atklāti atbildēt uz pieprasījumu: "Labi, Siri, kā izveidot bumbu."
Tāpēc pētnieki aprobežojās ar vienkāršu modeļa nodrošināšanu ar daudzām atsauksmēm. Savā ziņā bērni mācās morāli tieši šādi: viņi bērnībā eksperimentē un tajā pašā laikā rūpīgi pēta pieaugušo reakcijas, lai novērtētu, vai viņi uzvedās pareizi.
NorādietGPT, zināms arī kā GPT-3.5, būtībā ir GPT-3 kas saņēma daudz atsauksmju, lai uzlabotu atbildes. Burtiski vairākas personas tika apkopotas vienuviet, novērtējot neironu tīkla atbildes, lai noteiktu, cik labi viņi atbilda viņu cerībām, ņemot vērā viņu pieprasījumu.
Izrādās, ka GPT-3 jau ir apguvis visas nepieciešamās zināšanas: tas varētu saprast daudzas valodas, atsaukt atmiņā vēsturiskus notikumus, atpazīt autoru stilu variācijas utt., bet tas varētu iemācīties pareizi izmantot šīs zināšanas (no mūsu viedokļa) tikai ar ieguldījumu no citas personas. GPT-3.5 var uzskatīt par “sabiedrības izglītotu” modeli.
Kopsavilkums: galvenā funkcija GPT-3.5, kas tika ieviesta 2022. gada sākumā, bija papildu pārkvalifikācija, kas balstīta uz indivīdu sniegto informāciju. Izrādās, ka šis modelis patiesībā nav kļuvis lielāks un gudrāks, bet gan ir apguvis spēju pielāgot savas reakcijas tā, lai cilvēkiem radītu mežonīgākos smieklus.
ChatGPT: milzīgs ažiotāža uzplūds
Apmēram 10 mēnešus pēc tā priekšgājēja InstructGPT/GGPT-3.5, ChatGPT tika ieviests. Tas nekavējoties izraisīja globālu ažiotāžu.
No tehnoloģiskā viedokļa nešķiet, ka starp tām būtu būtiskas atšķirības ChatGPT un InstruētGPT. Modelis tika apmācīts ar papildu dialoga datiem, jo “AI palīga darbam” ir nepieciešams unikāls dialoga formāts, piemēram, iespēja uzdot precizējošu jautājumu, ja lietotāja pieprasījums ir neskaidrs.
Tātad, kāpēc apkārt nebija ažiotāža GPT-3.5 2022. gada sākumā, kamēr ChatGPT uztvēra kā meža ugunsgrēks? Sems Altmans, Izpilddirektors OpenAI, atklāti atzina, ka pētnieki mūs pārsteidza ChatGPTtūlītēji panākumi. Galu galā modele ar līdzīgām spējām tobrīd viņu tīmekļa vietnē bija snaudusi vairāk nekā desmit mēnešus, un neviens nebija uzdevumu augstumos.
Tas ir neticami, taču šķiet, ka jaunais lietotājam draudzīgais interfeiss ir tā panākumu atslēga. Tas pats norādījumsGPT var piekļūt, tikai izmantojot unikālu API saskarni, ierobežojot cilvēku piekļuvi modelim. ChatGPT, no otras puses, izmanto labi zināmo kurjeru “dialoga loga” saskarni. Arī kopš ChatGPT bija pieejams visiem uzreiz, liels skaits cilvēku steidzās mijiedarboties ar neironu tīklu, tos pārmeklēt un ievietot sociālo mediju, rosinot citus.
| vairāk: Amerikas izglītības sistēmai ir ļoti nepieciešami 300 tūkstoši skolotāju, bet ChatGPT varētu būt atbilde |
Bez lieliskajām tehnoloģijām pareizi tika paveikta cita lieta OpenAI: mārketings. Pat ja jums ir labākais modelis vai inteliģentākais tērzēšanas robots, ja tam nav ērti lietojama interfeisa, tas nevienu neinteresēs. Šajā sakarā, ChatGPT panāca izrāvienu, iepazīstinot ar tehnoloģiju plašāku sabiedrību, izmantojot ierasto dialoglodziņu, kurā izpalīdzīgs robots vārdu pa vārdam “izdrukā” risinājumu tieši mūsu acu priekšā.
Nepārsteidz, ChatGPT sasniedza visus iepriekšējos rekordus jaunu lietotāju piesaistē, pārspējot 1 miljona lietotāju pagrieziena punktu tikai piecās dienās pēc tā palaišanas un pārsniedzot 100 miljonus lietotāju tikai divu mēnešu laikā.
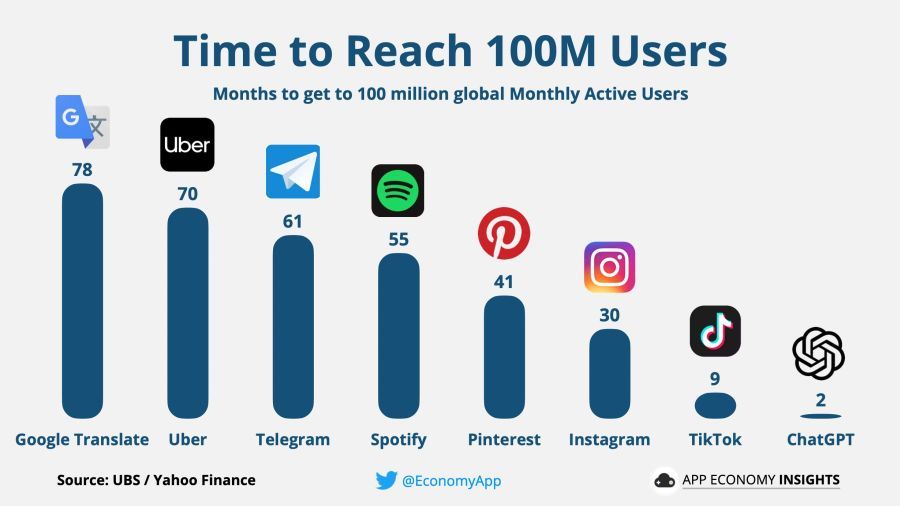
Protams, tur, kur ir rekordliels lietotāju skaita pieaugums, ir milzīga nauda. Ķīnieši steidzami paziņoja par savu gaidāmo izlaišanu chatbot, Microsoft ātri vienojās ar OpenAI lai tajos ieguldītu desmitiem miljardu dolāru, un Google inženieri izsauca trauksmi un sāka formulēt plānus, kā aizsargāt savu meklēšanas pakalpojumu no konkurences ar neironu tīklu.
Kopsavilkums: Kad ChatGPT modelis tika ieviests 2022. gada novembrī, nebija nekādu vērā ņemamu tehnoloģisku sasniegumu. Tomēr tam bija ērts interfeiss lietotāju iesaistīšanai un atvērtai piekļuvei, kas nekavējoties izraisīja milzīgu ažiotāžu. Tā kā šī ir visbūtiskākā problēma mūsdienu pasaulē, visi uzreiz sāka risināt valodu modeļus.
Lasiet vairāk par AI:
Atbildības noraidīšana
Atbilstīgi Uzticības projekta vadlīnijas, lūdzu, ņemiet vērā, ka šajā lapā sniegtā informācija nav paredzēta un to nedrīkst interpretēt kā juridisku, nodokļu, ieguldījumu, finanšu vai jebkāda cita veida padomu. Ir svarīgi ieguldīt tikai to, ko varat atļauties zaudēt, un meklēt neatkarīgu finanšu padomu, ja jums ir šaubas. Lai iegūtu papildinformāciju, iesakām skatīt pakalpojumu sniegšanas noteikumus, kā arī palīdzības un atbalsta lapas, ko nodrošina izdevējs vai reklāmdevējs. MetaversePost ir apņēmies sniegt precīzus, objektīvus pārskatus, taču tirgus apstākļi var tikt mainīti bez iepriekšēja brīdinājuma.
Par Autors
Damirs ir komandas vadītājs, produktu vadītājs un redaktors Metaverse Post, kas aptver tādas tēmas kā AI/ML, AGI, LLM, Metaverse un Web3- saistītie lauki. Viņa raksti katru mēnesi piesaista lielu auditoriju, kas pārsniedz miljonu lietotāju. Šķiet, ka viņš ir eksperts ar 10 gadu pieredzi SEO un digitālā mārketinga jomā. Damirs ir minēts Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto un citas publikācijas. Viņš ceļo starp AAE, Turciju, Krieviju un NVS kā digitālais nomads. Damirs ir ieguvis bakalaura grādu fizikā, kas, viņaprāt, ir devis viņam kritiskās domāšanas prasmes, kas nepieciešamas, lai gūtu panākumus nepārtraukti mainīgajā interneta vidē.
Vairāk rakstus
Damirs ir komandas vadītājs, produktu vadītājs un redaktors Metaverse Post, kas aptver tādas tēmas kā AI/ML, AGI, LLM, Metaverse un Web3- saistītie lauki. Viņa raksti katru mēnesi piesaista lielu auditoriju, kas pārsniedz miljonu lietotāju. Šķiet, ka viņš ir eksperts ar 10 gadu pieredzi SEO un digitālā mārketinga jomā. Damirs ir minēts Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto un citas publikācijas. Viņš ceļo starp AAE, Turciju, Krieviju un NVS kā digitālais nomads. Damirs ir ieguvis bakalaura grādu fizikā, kas, viņaprāt, ir devis viņam kritiskās domāšanas prasmes, kas nepieciešamas, lai gūtu panākumus nepārtraukti mainīgajā interneta vidē.






