



T9-युग से चैटबॉट्स का विकास और GPT-1 सेवा मेरे ChatGPT






हाल ही में, हम पर बड़े पैमाने पर तंत्रिका नेटवर्क द्वारा तोड़े गए नवीनतम रिकॉर्ड के बारे में समाचार पोस्टों की लगभग प्रतिदिन बमबारी की गई है और क्यों किसी की भी नौकरी सुरक्षित नहीं है। फिर भी, बहुत कम लोग जानते हैं कि तंत्रिका नेटवर्क कैसा होता है ChatGPT वास्तव में संचालित.
तो शांत रहो। अभी अपनी नौकरी की संभावनाओं के बारे में चिंता न करें। इस पोस्ट में, हम तंत्रिका नेटवर्क के बारे में जानने के लिए हर उस चीज़ की व्याख्या करेंगे, जिसे हर कोई समझ सकता है।

शुरू करने से पहले एक चेतावनी: यह टुकड़ा एक सहयोग है। संपूर्ण तकनीकी भाग एक AI विशेषज्ञ द्वारा लिखा गया था जो AI भीड़ के बीच प्रसिद्ध है।
चूँकि अभी तक किसी ने भी इस बारे में गहराई से नहीं लिखा है कि कैसे ChatGPT ऐसे कार्य जो आम आदमी के शब्दों में, तंत्रिका नेटवर्क के अंदर और बाहर समझाएंगे, हमने आपके लिए यह करने का निर्णय लिया है। हमने इस पोस्ट को यथासंभव सरल रखने का प्रयास किया है ताकि पाठक इस पोस्ट को पढ़कर भाषा तंत्रिका नेटवर्क के सिद्धांतों की सामान्य समझ प्राप्त कर सकें। हम पता लगाएंगे कि कैसे भाषा मॉडल वहां काम करें, तंत्रिका नेटवर्क अपनी वर्तमान क्षमताओं को प्राप्त करने के लिए कैसे विकसित हुए, और क्यों ChatGPTकी विस्फोटक लोकप्रियता ने इसके रचनाकारों को भी आश्चर्यचकित कर दिया।
आइए बुनियादी बातों से शुरू करें। समझ में ChatGPT तकनीकी दृष्टिकोण से, हमें पहले यह समझना होगा कि यह क्या नहीं है। यह मार्वल कॉमिक्स का जार्विस नहीं है; यह कोई तर्कसंगत प्राणी नहीं है; यह कोई जिन्न नहीं है. चौंकने के लिए तैयार रहें: ChatGPT वास्तव में आपके सेलफोन का T9 स्टेरॉयड पर है! हाँ, यह है: वैज्ञानिक इन दोनों प्रौद्योगिकियों को कहते हैं "भाषा मॉडल।" सभी तंत्रिका नेटवर्क अनुमान लगाते हैं कि आगे कौन सा शब्द आना चाहिए।
मूल T9 तकनीक ने केवल अगले शब्द के बजाय वर्तमान इनपुट का अनुमान लगाकर पुश-बटन फोन डायलिंग को गति दी। हालांकि, प्रौद्योगिकी उन्नत हुई, और 2010 की शुरुआत में स्मार्टफोन के युग तक, यह संदर्भ और पहले शब्द पर विचार करने, विराम चिह्न जोड़ने और आगे जाने वाले शब्दों के चयन की पेशकश करने में सक्षम था। ठीक यही सादृश्य हम T9 या स्वतः सुधार के ऐसे "उन्नत" संस्करण के साथ बना रहे हैं।
नतीजतन, स्मार्टफोन कीबोर्ड पर दोनों T9 और ChatGPT एक अत्यंत सरल कार्य को हल करने के लिए प्रशिक्षित किया गया है: अगले शब्द की भविष्यवाणी करना। इसे "भाषा मॉडलिंग" के रूप में जाना जाता है, और यह तब होता है जब कोई निर्णय लिया जाता है कि मौजूदा पाठ के आधार पर आगे क्या लिखा जाना चाहिए। ऐसी भविष्यवाणियां करने के लिए भाषा मॉडल को विशिष्ट शब्दों की घटना की संभावनाओं पर काम करना चाहिए। आखिरकार, यदि आपके फोन के ऑटोफिल ने आपको पूरी तरह से यादृच्छिक शब्दों को समान संभावना के साथ फेंक दिया तो आप नाराज होंगे।
स्पष्टता के लिए, आइए कल्पना करें कि आपको किसी मित्र से संदेश प्राप्त होता है। यह कहता है: "शाम के लिए आपकी क्या योजना है?" जवाब में, आप टाइप करना शुरू करते हैं: "मैं जा रहा हूँ ...", और यहीं पर T9 आता है। यह "मैं चाँद पर जा रहा हूँ" जैसी पूरी तरह से निरर्थक चीजों के साथ आ सकता है, किसी जटिल भाषा मॉडल की आवश्यकता नहीं है। अच्छे स्मार्टफोन ऑटो-पूर्ण मॉडल कहीं अधिक प्रासंगिक शब्द सुझाते हैं।
तो, T9 को कैसे पता चलता है कि कौन से शब्द पहले से टाइप किए गए पाठ का अनुसरण करने की अधिक संभावना रखते हैं और कौन सा शब्द स्पष्ट रूप से समझ में नहीं आता है? इस प्रश्न का उत्तर देने के लिए, हमें सबसे पहले सरलतम के मूलभूत संचालन सिद्धांतों की जांच करनी चाहिए तंत्रिका जाल.
- एआई मॉडल अगले शब्द की भविष्यवाणी कैसे करते हैं
- हम किसी दिए गए पाठ के लिए 'सही' शब्द खोजने का प्रयास क्यों करते रहते हैं?
- GPT-1: उद्योग को नष्ट करना
- GPT-2: बड़े भाषा मॉडलों का युग
- GPT-3: बिल्कुल स्मार्ट
- GPT-3.5 (निर्देशGPT): मॉडल को सुरक्षित और गैर विषैले होने के लिए प्रशिक्षित किया गया
- ChatGPT: प्रचार में भारी उछाल
एआई मॉडल अगले शब्द की भविष्यवाणी कैसे करते हैं
आइए एक सरल प्रश्न से शुरू करें: आप कुछ चीजों की दूसरों पर अन्योन्याश्रयता की भविष्यवाणी कैसे करते हैं? मान लें कि हम एक कंप्यूटर को किसी व्यक्ति के कद के आधार पर उसके वजन का अनुमान लगाना सिखाना चाहते हैं - हमें इसके बारे में कैसे जाना चाहिए? हमें पहले रुचि के क्षेत्रों की पहचान करनी चाहिए और फिर डेटा एकत्र करना चाहिए, जिस पर रुचि की निर्भरताओं की खोज की जाए और फिर प्रयास किया जाए "प्रशिक्षण" कुछ गणितीय मॉडल इस डेटा के भीतर पैटर्न देखने के लिए।
सीधे शब्दों में कहें तो T9 या ChatGPT ये केवल चतुराई से चुने गए समीकरण हैं जो ऐसा करने का प्रयास करते हैं भविष्यवाणी करना मॉडल इनपुट में फीड किए गए पिछले शब्दों (X) के सेट पर आधारित एक शब्द (Y)। प्रशिक्षण के दौरान ए भाषा मॉडल डेटा सेट पर, मुख्य कार्य इन एक्स के लिए गुणांक का चयन करना है जो वास्तव में किसी प्रकार की निर्भरता को दर्शाता है (जैसा कि ऊंचाई और वजन के साथ हमारे उदाहरण में)। और बड़े मॉडलों के द्वारा, हम उन लोगों की बेहतर समझ प्राप्त करेंगे जिनके पास बड़ी संख्या में पैरामीटर हैं। के क्षेत्र में कृत्रिम बुद्धिमत्ता, उन्हें बड़े भाषा मॉडल या संक्षेप में एलएलएम कहा जाता है। जैसा कि हम बाद में देखेंगे, अच्छा पाठ उत्पन्न करने के लिए कई मापदंडों वाला एक बड़ा मॉडल आवश्यक है।
वैसे, यदि आप सोच रहे हैं कि हम लगातार "अगले शब्द की भविष्यवाणी" के बारे में क्यों बात कर रहे हैं ChatGPT पाठ के पूरे अनुच्छेदों के साथ त्वरित प्रतिक्रिया देता है, उत्तर सरल है। निश्चित रूप से, भाषा मॉडल बिना किसी कठिनाई के लंबे पाठ तैयार कर सकते हैं, लेकिन पूरी प्रक्रिया शब्द दर शब्द होती है। प्रत्येक नए शब्द के उत्पन्न होने के बाद, मॉडल अगले शब्द को उत्पन्न करने के लिए नए शब्द के साथ सभी पाठ को फिर से चलाता है। यह प्रक्रिया तब तक बार-बार दोहराई जाती है जब तक आपको पूरी प्रतिक्रिया नहीं मिल जाती।
| अधिक जानकारी: ChatGPT अपरिवर्तनीय मानव पतन का कारण बन सकता है |
हम किसी दिए गए पाठ के लिए 'सही' शब्द खोजने का प्रयास क्यों करते रहते हैं?
भाषा मॉडल किसी दिए गए पाठ में हो सकने वाले विभिन्न शब्दों की संभावनाओं की भविष्यवाणी करने का प्रयास करते हैं। यह क्यों जरूरी है, और आप सिर्फ "सबसे सही" शब्द की तलाश क्यों नहीं कर सकते? यह प्रक्रिया कैसे काम करती है, यह समझाने के लिए आइए एक सरल खेल का प्रयास करें।
नियम इस प्रकार हैं: मैं प्रस्ताव करता हूं कि आप वाक्य जारी रखें: "संयुक्त राज्य अमेरिका के 44 वें राष्ट्रपति (और इस पद पर पहले अफ्रीकी अमेरिकी) बराक हैं ..."। आगे कौन सा शब्द जाना चाहिए? इसके घटित होने की क्या संभावना है?
यदि आपने 100% निश्चितता के साथ भविष्यवाणी की थी कि अगला शब्द "ओबामा" होगा, तो आप गलत थे! और यहाँ बात यह नहीं है कि एक और पौराणिक बराक है; यह बहुत अधिक तुच्छ है। आधिकारिक दस्तावेजों में आमतौर पर राष्ट्रपति के पूरे नाम का इस्तेमाल होता है। इसका मतलब यह है कि ओबामा के पहले नाम के बाद उनका मध्य नाम हुसैन होगा। तो, हमारे वाक्य में, एक ठीक से प्रशिक्षित भाषा मॉडल को भविष्यवाणी करनी चाहिए कि "ओबामा" केवल 90% की सशर्त संभावना के साथ अगला शब्द होगा और शेष 10% आवंटित करें यदि पाठ "हुसैन" द्वारा जारी रखा गया है (जिसके बाद ओबामा करेंगे 100% के करीब संभावना के साथ पालन करें)।
और अब हम भाषा मॉडल के एक पेचीदा पहलू पर आते हैं: वे रचनात्मक धारियों से प्रतिरक्षित नहीं हैं! वास्तव में, प्रत्येक अगला शब्द उत्पन्न करते समय, ऐसे मॉडल इसे "यादृच्छिक" तरीके से चुनते हैं, जैसे कि पासा फेंकना। अलग-अलग शब्दों "गिरने" की संभावना मॉडल के अंदर डाले गए समीकरणों द्वारा सुझाई गई संभावनाओं से कम या ज्यादा मेल खाती है। ये मॉडल को खिलाए गए विभिन्न ग्रंथों की विशाल सरणी से प्राप्त हुए हैं।
यह पता चला है कि एक मॉडल एक जीवित व्यक्ति की तरह ही समान अनुरोधों का अलग-अलग जवाब दे सकता है। शोधकर्ताओं ने आम तौर पर न्यूरॉन्स को हमेशा "सबसे अधिक संभावना" अगले शब्द का चयन करने के लिए मजबूर करने का प्रयास किया है, लेकिन जब यह सतह पर तर्कसंगत लगता है, ऐसे मॉडल वास्तविकता में खराब प्रदर्शन करते हैं। ऐसा लगता है कि यादृच्छिकता की एक उचित खुराक लाभप्रद है क्योंकि यह परिवर्तनशीलता और उत्तरों की गुणवत्ता को बढ़ाती है।
| अधिक जानकारी: ChatGPT ड्रोन और रोबोट को नियंत्रित करना सीखें क्योंकि यह अगली पीढ़ी के एआई पर विचार करता है |
हमारी भाषा में नियमों और अपवादों के अलग-अलग सेट के साथ एक अनूठी संरचना है। एक वाक्य में जो शब्द दिखाई देते हैं, उनमें तुकबंदी और कारण होता है, वे सिर्फ यादृच्छिक रूप से नहीं होते हैं। हर कोई अनजाने में उस भाषा के नियमों को सीख लेता है जिसका उपयोग वे अपने प्रारंभिक प्रारंभिक वर्षों के दौरान करते हैं।
एक सभ्य मॉडल को भाषा की विस्तृत वर्णनात्मकता को ध्यान में रखना चाहिए। मॉडल का वांछित परिणाम उत्पन्न करने की क्षमता यह इस बात पर निर्भर करता है कि यह संदर्भ की सूक्ष्मता (परिस्थिति की व्याख्या करने वाले पाठ का पिछला भाग) के आधार पर शब्दों की संभावनाओं की कितनी सटीक गणना करता है।
सारांश: सरल भाषा मॉडल, जो इनपुट स्रोत पाठ के आधार पर अगले शब्द की भविष्यवाणी करने के लिए बड़ी मात्रा में डेटा पर प्रशिक्षित समीकरणों का एक सेट है, को 9 की शुरुआत से स्मार्टफोन की "T2010/ऑटोफिल" कार्यक्षमता में लागू किया गया है।
GPT-1: उद्योग को नष्ट करना
आइए T9 मॉडल से दूर चलते हैं। जबकि आप शायद इस टुकड़े को पढ़ रहे हैं के बारे में जानना ChatGPT, सबसे पहले, हमें इसकी शुरुआत पर चर्चा करने की आवश्यकता है GPT आदर्श परिवार.
GPT इसका मतलब "जनरेटिव पूर्व-प्रशिक्षित ट्रांसफार्मर" है, जबकि Google इंजीनियरों द्वारा विकसित तंत्रिका नेटवर्क वास्तुकला 2017 में ट्रांसफार्मर के रूप में जाना जाता है। ट्रांसफार्मर एक सार्वभौमिक कंप्यूटिंग तंत्र है जो अनुक्रमों (डेटा) के एक सेट को इनपुट के रूप में स्वीकार करता है और अनुक्रमों के समान सेट का उत्पादन करता है लेकिन एक अलग रूप में जिसे कुछ एल्गोरिथम द्वारा बदल दिया गया है।
ट्रांसफॉर्मर के निर्माण का महत्व इस बात से देखा जा सकता है कि कृत्रिम बुद्धिमत्ता (एआई) के सभी क्षेत्रों में इसे कितनी तेजी से अपनाया और लागू किया गया: अनुवाद, छवि, ध्वनि और वीडियो प्रसंस्करण। आर्टिफिशियल इंटेलिजेंस (एआई) क्षेत्र में एक शक्तिशाली शेक-अप था, जो तथाकथित "एआई ठहराव" से तेजी से विकास और ठहराव पर काबू पाने की ओर बढ़ रहा था।
| अधिक जानकारी: GPT-4आधारित ChatGPT Outperforms GPT-3 570 के कारक द्वारा |
ट्रांसफार्मर की प्रमुख ताकत आसान-से-पैमाने वाले मॉड्यूल से बनी है। जब बड़ी मात्रा में पाठ को एक साथ संसाधित करने के लिए कहा जाता है, तो पुराने, पूर्व-ट्रांसफ़ॉर्मर भाषा मॉडल धीमे हो जाते हैं। दूसरी ओर, ट्रांसफॉर्मर न्यूरल नेटवर्क इस कार्य को कहीं बेहतर तरीके से हैंडल करते हैं।
अतीत में, इनपुट डेटा को क्रमिक रूप से या एक बार में संसाधित किया जाना था। मॉडल डेटा को बनाए नहीं रखेगा: यदि यह एक पृष्ठ की कहानी के साथ काम करता है, तो यह पाठ को पढ़ने के बाद भूल जाएगा। इस बीच, ट्रांसफार्मर एक बार में सब कुछ देखने में सक्षम बनाता है, उत्पादन काफी अधिक आश्चर्यजनक परिणाम।
इसने तंत्रिका नेटवर्क द्वारा ग्रंथों के प्रसंस्करण में सफलता को सक्षम किया। नतीजतन, मॉडल अब नहीं भूलता है: यह पहले से लिखी गई सामग्री का पुन: उपयोग करता है, संदर्भ को बेहतर ढंग से समझता है, और, सबसे महत्वपूर्ण, शब्दों को एक साथ जोड़कर बहुत बड़ी मात्रा में डेटा के बीच संबंध बनाने में सक्षम है।
सारांश: GPT-1, जो 2018 में शुरू हुआ, ने प्रदर्शित किया कि एक तंत्रिका नेटवर्क ट्रांसफॉर्मर डिज़ाइन का उपयोग करके टेक्स्ट का उत्पादन कर सकता है, जिससे स्केलेबिलिटी और दक्षता में काफी सुधार हुआ है। यदि भाषा मॉडल की मात्रा और जटिलता को बढ़ाना संभव होता, तो इससे एक बड़ा भंडार तैयार होता।
| अधिक जानकारी: 6 एआई चैटबॉट मुद्दे और चुनौतियाँ: ChatGPT, बार्ड, क्लाउड |
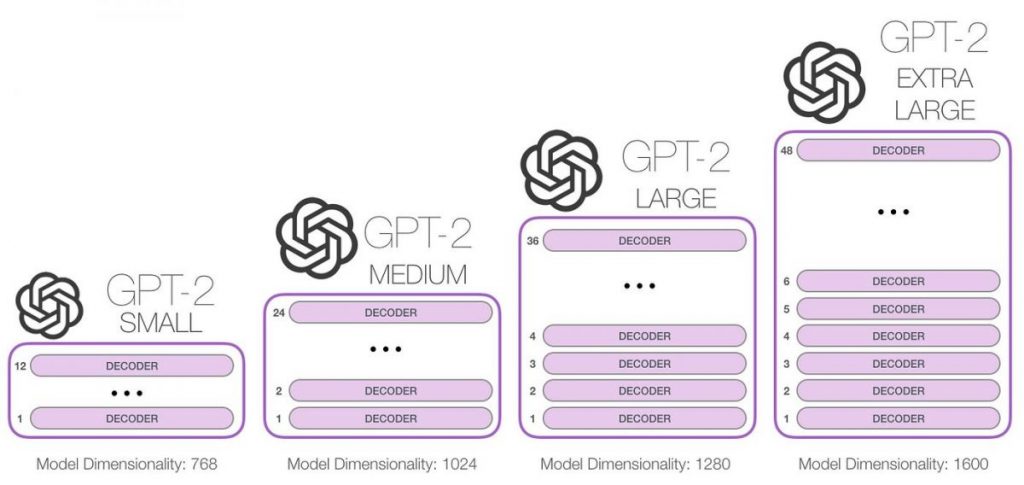
GPT-2: बड़े भाषा मॉडलों का युग
भाषा मॉडल को विशेष रूप से पहले से टैग करने की आवश्यकता नहीं होती है और उन्हें किसी भी पाठ्य डेटा के साथ "फ़ीड" किया जा सकता है, जिससे वे बेहद लचीले हो जाते हैं। यदि आप इस पर कुछ विचार करें, तो यह उचित प्रतीत होता है कि हम इसकी क्षमताओं का उपयोग करना चाहेंगे। कोई भी पाठ जो कभी लिखा गया है, तैयार प्रशिक्षण डेटा के रूप में कार्य करता है। चूंकि पहले से ही बहुत सारे अनुक्रम हैं जैसे "बहुत सारे शब्द और वाक्यांश => उनके बाद अगला शब्द," यह आश्चर्य की बात नहीं है।
| अधिक जानकारी: ChatGPTReddit पर दुष्ट एल्टर अहंकार जागृत हुआ |
अब यह भी ध्यान रखें कि ट्रांसफॉर्मर्स तकनीक का परीक्षण किया गया GPT-1 स्केलिंग के मामले में यह काफी सफल साबित हुआ: बड़ी मात्रा में डेटा को संभालने में यह अपने पूर्ववर्तियों की तुलना में काफी अधिक प्रभावी है। यह पता चला है कि शोधकर्ताओं से OpenAI 2019 में इसी निष्कर्ष पर पहुंचे: "महंगे भाषा मॉडल में कटौती करने का समय आ गया है!"
RSI प्रशिक्षण डेटा सेट और मॉडल आकार, विशेष रूप से, दो महत्वपूर्ण क्षेत्रों के रूप में चुना गया था GPT-2 अत्यधिक सुधार की आवश्यकता है।
चूँकि उस समय विशेष रूप से प्रशिक्षण भाषा मॉडल के लिए डिज़ाइन किए गए कोई विशाल, उच्च-गुणवत्ता वाले सार्वजनिक पाठ डेटा सेट नहीं थे, एआई विशेषज्ञों की प्रत्येक टीम को अपने दम पर डेटा में हेरफेर करना पड़ता था। OpenAI इसके बाद लोगों ने सबसे लोकप्रिय अंग्रेजी-भाषा मंच Reddit पर जाने और तीन से अधिक लाइक वाले प्रत्येक पोस्ट से सभी हाइपरलिंक निकालने का निर्णय लिया। इनमें से लगभग 8 मिलियन लिंक थे, और डाउनलोड किए गए टेक्स्ट का वजन कुल मिलाकर 40 टेराबाइट्स था।
समीकरण ने किस संख्या में पैरामीटर का वर्णन सबसे बड़ा किया GPT-2 2019 में मॉडल है? शायद एक लाख या कुछ मिलियन? खैर, चलिए और भी आगे बढ़ते हैं: सूत्र में 1.5 बिलियन तक ऐसे पैरामीटर शामिल हैं। इतने सारे नंबरों को एक फ़ाइल में लिखने और इसे अपने कंप्यूटर पर सहेजने में 6 टेराबाइट लगेंगे। मॉडल को इस पाठ को समग्र रूप से याद रखने की आवश्यकता नहीं है, इसलिए एक ओर, यह उस पाठ डेटा सरणी की कुल मात्रा से बहुत कम है जिस पर मॉडल को प्रशिक्षित किया गया है; इसके लिए बस कुछ निर्भरताएं (पैटर्न, नियम) ढूंढना पर्याप्त है जिन्हें लोगों द्वारा लिखे गए ग्रंथों से अलग किया जा सकता है।
मॉडल जितना बेहतर संभाव्यता का पूर्वानुमान लगाता है और इसमें जितने अधिक पैरामीटर होते हैं, मॉडल में समीकरण उतना ही अधिक जटिल होता है। यह एक विश्वसनीय पाठ बनाता है. इसके अतिरिक्त, GPT-2 मॉडल ने इतना अच्छा प्रदर्शन करना शुरू कर दिया कि OpenAI शोधकर्ताओं सुरक्षा कारणों से मॉडल को खुले में प्रकट करने में भी अनिच्छुक थे।
यह बहुत दिलचस्प है कि जब कोई मॉडल बड़ा हो जाता है, तो उसमें अचानक नए गुण होने लगते हैं (जैसे फोन पर केवल अगले शब्द को निर्धारित करने के बजाय सुसंगत, अर्थपूर्ण निबंध लिखने की क्षमता)।
मात्रा से गुणवत्ता में परिवर्तन इसी बिंदु पर होता है। इसके अलावा, यह पूरी तरह से गैर-रैखिक रूप से होता है। उदाहरण के लिए, 115 से 350 मिलियन तक मापदंडों की संख्या में तीन गुना वृद्धि का मॉडल की समस्याओं को सटीक रूप से हल करने की क्षमता पर कोई प्रभाव नहीं पड़ता है। हालाँकि, 700 मिलियन तक दो गुना वृद्धि एक गुणात्मक छलांग पैदा करती है, जहाँ तंत्रिका नेटवर्क "प्रकाश देखता है" और कार्यों को पूरा करने की अपनी क्षमता से सभी को चकित करना शुरू कर देता है।
सारांश: 2019 में इसका परिचय देखा गया GPT-2, जो मॉडल के आकार (मापदंडों की संख्या) और प्रशिक्षण पाठ डेटा की मात्रा के मामले में अपने पूर्ववर्ती से 10 गुना आगे निकल गया। इस मात्रात्मक प्रगति के कारण, मॉडल ने अप्रत्याशित रूप से गुणात्मक रूप से नई प्रतिभाएँ हासिल कर लीं, जैसे कि करने की क्षमता लम्बे निबंध लिखें एक स्पष्ट अर्थ के साथ और उन चुनौतीपूर्ण समस्याओं को हल करें जो एक विश्वदृष्टि की नींव की मांग करती हैं।
GPT-3: बिल्कुल स्मार्ट
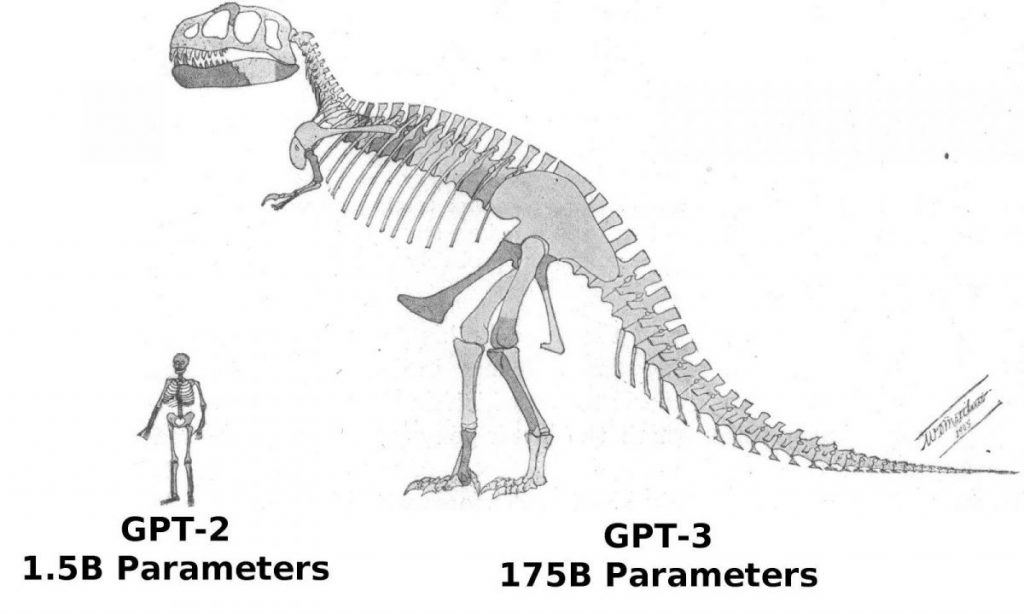
सामान्य तौर पर, 2020 की रिलीज़ GPT-3, श्रृंखला की अगली पीढ़ी, पहले से ही 116 गुना अधिक मापदंडों का दावा करती है - 175 बिलियन तक और आश्चर्यजनक 700 टेराबाइट्स।
RSI GPT-3 प्रशिक्षण डेटा सेट का भी विस्तार किया गया, यद्यपि उतना अधिक नहीं। यह लगभग 10 गुना बढ़कर 420 गीगाबाइट हो गया और अब इसमें बड़ी संख्या में पुस्तकें हैं, Wikiपीडिया लेख, और अन्य वेबसाइटों से अन्य पाठ। एक इंसान को बिना रुके पढ़ने में लगभग 50 साल लगेंगे, जिससे यह एक असंभव उपलब्धि बन जाएगी।
आप तुरंत एक दिलचस्प अंतर नोटिस करते हैं: विपरीत GPT-2, मॉडल अब अपने प्रशिक्षण के लिए पाठ की संपूर्ण श्रृंखला (700 जीबी) से 420 जीबी बड़ा है। यह, एक अर्थ में, एक विरोधाभास साबित होता है: इस उदाहरण में, जैसा कि "न्यूरोब्रेन" कच्चे डेटा का अध्ययन करता है, यह उनके भीतर विभिन्न अन्योन्याश्रितताओं के बारे में जानकारी उत्पन्न करता है जो मूल डेटा की तुलना में अधिक प्रचुर मात्रा में प्रचुर मात्रा में है।
मॉडल के सामान्यीकरण के परिणामस्वरूप, यह अब पहले की तुलना में और भी अधिक सफलतापूर्वक एक्सट्रपलेशन करने में सक्षम है और उन टेक्स्ट-जनरेशन कार्यों में भी सफल है जो प्रशिक्षण के दौरान कभी-कभार या बिल्कुल नहीं होते थे। अब, आपको मॉडल को यह सिखाने की ज़रूरत नहीं है कि किसी निश्चित समस्या से कैसे निपटा जाए; उनका वर्णन करना और कुछ उदाहरण प्रदान करना ही पर्याप्त है, और GPT-3 तुरंत सीख जाओगे.
RSI "सार्वभौमिक मस्तिष्क" की हालत में GPT-3 अंततः कई पुराने विशिष्ट मॉडलों को हरा दिया। उदाहरण के लिए, GPT-3 इस उद्देश्य के लिए विशेष रूप से बनाए गए किसी भी पिछले तंत्रिका नेटवर्क की तुलना में फ्रेंच या जर्मन से ग्रंथों का तेजी से और अधिक सटीक अनुवाद करना शुरू कर दिया। कैसे? मैं आपको याद दिला दूं कि हम एक भाषाई मॉडल पर चर्चा कर रहे हैं जिसका एकमात्र उद्देश्य किसी दिए गए पाठ में निम्नलिखित शब्द की भविष्यवाणी करने का प्रयास करना था।
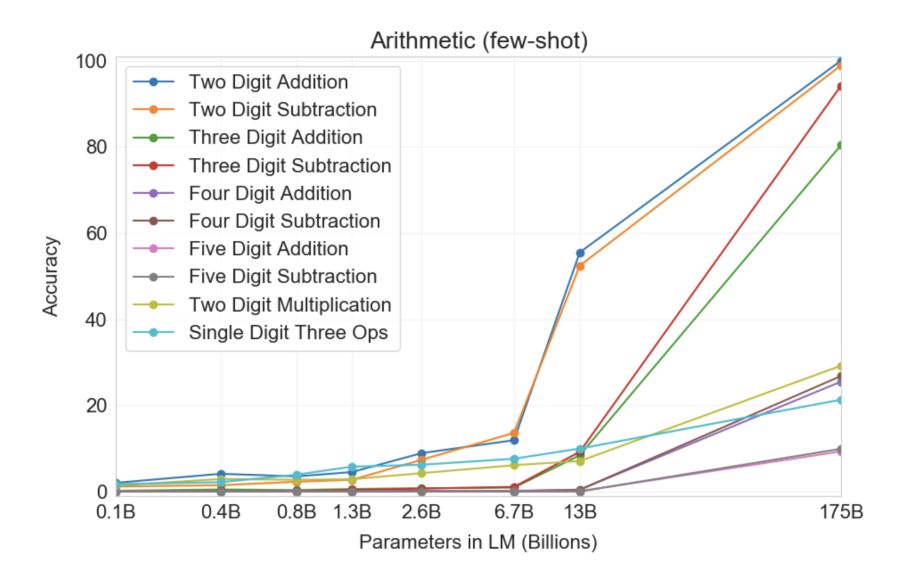
और भी आश्चर्यजनक रूप से, GPT-3 खुद को पढ़ाने में सक्षम था...गणित! नीचे दिया गया ग्राफ़ दिखाता है कि तंत्रिका नेटवर्क जोड़ और घटाव के साथ-साथ विभिन्न मापदंडों के साथ पांच अंकों तक पूर्णांकों के गुणन सहित कार्यों पर कितना अच्छा प्रदर्शन करते हैं। जैसा कि आप देख सकते हैं, 10 बिलियन पैरामीटर वाले मॉडल से 100 बिलियन वाले मॉडल की ओर बढ़ते हुए तंत्रिका नेटवर्क अचानक गणित में "सक्षम" होने लगते हैं।
| अधिक जानकारी: बिग टेक की एआई रेस: Google इसके जवाब में एआई-पावर्ड चैटबॉट का परीक्षण कर रहा है ChatGPT |
उपर्युक्त ग्राफ़ की सबसे दिलचस्प विशेषता यह है कि, शुरू में, मॉडल का आकार बढ़ने पर (बाएँ से दाएँ) कुछ भी नहीं बदलता है, लेकिन अचानक, पी बार! एक गुणात्मक बदलाव होता है, और GPT-3 किसी निश्चित मुद्दे को कैसे हल किया जाए यह "समझना" शुरू हो जाता है। कोई भी निश्चित नहीं है कि यह कैसे, क्या या क्यों कार्य करता है। फिर भी, यह गणित के साथ-साथ कई अन्य कठिनाइयों में भी काम करता प्रतीत होता है।
उपर्युक्त ग्राफ़ की सबसे दिलचस्प विशेषता यह है कि जब मॉडल का आकार बढ़ता है, तो पहले, कुछ भी नहीं बदलता है, और फिर, GPT-3 एक गुणात्मक छलांग लगाता है और एक निश्चित मुद्दे को हल करने के तरीके को "समझना" शुरू करता है।
नीचे दिया गया gif केवल यह दर्शाता है कि पैरामीटर की संख्या बढ़ने पर मॉडल में "अंकुरित" करने के लिए किसी ने जानबूझकर नई क्षमताओं की योजना कैसे बनाई:
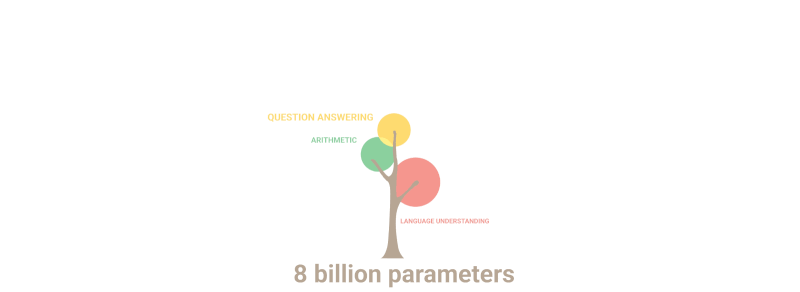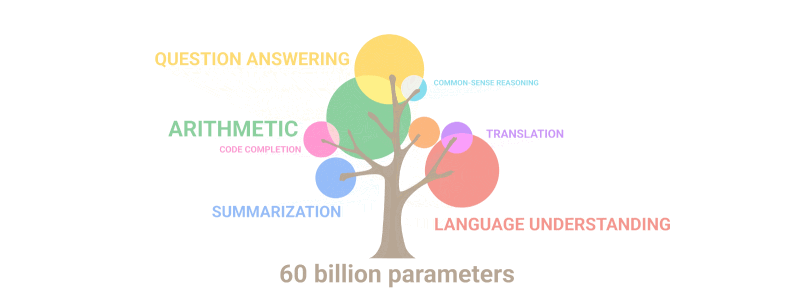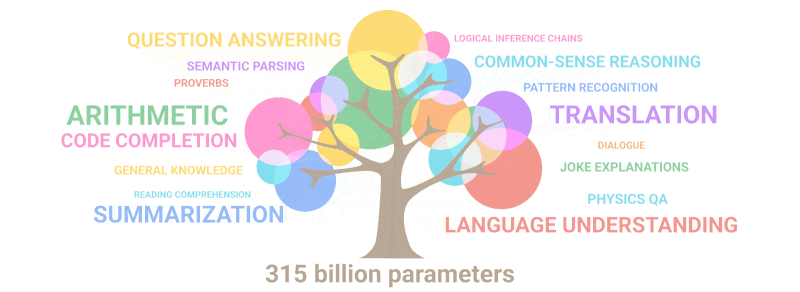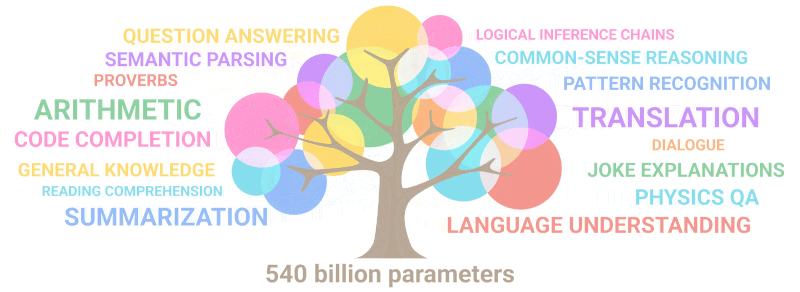
सारांश: मापदंडों के संदर्भ में, 2020 GPT-3 अपने पूर्ववर्ती से 100 गुना बड़ा था, जबकि प्रशिक्षण पाठ डेटा 10 गुना बड़ा था। एक बार फिर, मॉडल ने मात्रा में विस्तार के परिणामस्वरूप अन्य भाषाओं से अनुवाद करना, अंकगणित करना, सरल प्रोग्रामिंग करना, क्रमिक रूप से तर्क करना और बहुत कुछ करना सीखा, जिससे गुणवत्ता में अचानक वृद्धि हुई।
| अधिक जानकारी: ChatGPT डोनाल्ड ट्रंप से दिक्कत है |
GPT-3.5 (निर्देश देंGPT): मॉडल को सुरक्षित और गैर विषैले होने के लिए प्रशिक्षित किया गया
वास्तव में, भाषा मॉडल का विस्तार इस बात की गारंटी नहीं देता है कि यह पूछताछ पर उस तरह से प्रतिक्रिया करेगा जैसा उपयोगकर्ता चाहते हैं। वास्तव में, जब हम कोई अनुरोध करते हैं, तो हम अक्सर कई अनकही शर्तों का इरादा रखते हैं, जिन्हें मानव संचार में सच मान लिया जाता है।
फिर भी, ईमानदार होने के लिए, भाषा मॉडल लोगों के बहुत निकट नहीं हैं। इस प्रकार, उन्हें अक्सर उन अवधारणाओं पर विचार करने की आवश्यकता होती है जो लोगों को सरल दिखाई देती हैं। ऐसा ही एक सुझाव वाक्यांश है, "चलो कदम दर कदम सोचते हैं।" यह शानदार होगा यदि मॉडल अनुरोध से अधिक विशिष्ट और प्रासंगिक निर्देशों को समझते हैं या उत्पन्न करते हैं और उनका अधिक सटीक रूप से पालन करते हैं जैसे कि किसी व्यक्ति ने कैसे व्यवहार किया होगा।
तथ्य यह है कि GPT-3 इंटरनेट से ग्रंथों के विशाल संग्रह में केवल अगले शब्द का अनुमान लगाने के लिए प्रशिक्षित किया जाता है, बहुत सारी अलग-अलग चीजें लिखी जाती हैं, जो ऐसी "डिफ़ॉल्ट" क्षमताओं की कमी में योगदान देता है। लोग चाहते हैं कि कृत्रिम बुद्धिमत्ता प्रतिक्रियाओं को सुरक्षित और गैर विषैले रखते हुए प्रासंगिक जानकारी प्रदान करे।
जब शोधकर्ताओं ने इस मुद्दे पर कुछ विचार किया, तो यह स्पष्ट हो गया कि मॉडल की "सटीकता और उपयोगिता" और "हानिरहितता और गैर-विषाक्तता" के गुण कभी-कभी एक-दूसरे के विपरीत प्रतीत होते हैं। आखिरकार, अधिकतम हानिरहितता के लिए ट्यून किया गया एक मॉडल "क्षमा करें, मुझे चिंता है कि मेरा उत्तर इंटरनेट पर किसी को अपमानित कर सकता है" के साथ किसी भी संकेत पर प्रतिक्रिया करेगा। एक सटीक मॉडल को स्पष्ट रूप से अनुरोध का जवाब देना चाहिए, "ठीक है, सिरी, बम कैसे बनाएं।"
| अधिक जानकारी: एक व्यक्ति ने केवल एक दिन में अपनी थीसिस लिखी ChatGPT |
इसलिए, शोधकर्ता केवल बहुत अधिक प्रतिक्रिया के साथ मॉडल प्रदान करने तक ही सीमित थे। एक मायने में, यह ठीक इसी तरह है कि बच्चे नैतिकता सीखते हैं: वे बचपन में प्रयोग करते हैं, और साथ ही, वे वयस्कों की प्रतिक्रियाओं का सावधानीपूर्वक अध्ययन करते हैं ताकि यह आकलन किया जा सके कि क्या उन्होंने सही व्यवहार किया है।
हिदायतGPT , जिसे GPT-3.5, मूलतः है GPT-3 इसे अपने उत्तरों को बेहतर बनाने के लिए बहुत सारी प्रतिक्रियाएँ मिलीं। वस्तुतः, कई व्यक्ति एक स्थान पर एकत्र हुए थे, और तंत्रिका नेटवर्क के उत्तरों का आकलन करके यह निर्धारित कर रहे थे कि उनके द्वारा किए गए अनुरोध के आलोक में वे उनकी अपेक्षाओं से कितने मेल खाते हैं।
परिणाम यह निकला GPT-3 उसके पास पहले से ही सभी आवश्यक ज्ञान हैं: वह कई भाषाओं को समझ सकता है, ऐतिहासिक घटनाओं को याद कर सकता है, लेखकीय शैलियों में विविधताओं को पहचान सकता है, इत्यादि, लेकिन वह इस ज्ञान का सही ढंग से उपयोग करना (हमारे दृष्टिकोण से) इनपुट के साथ ही सीख सकता है। अन्य व्यक्ति. GPT-3.5 को "समाज-शिक्षित" मॉडल के रूप में सोचा जा सकता है।
सारांश: का प्राथमिक कार्य GPT-3.5, जिसे 2022 की शुरुआत में पेश किया गया था, व्यक्तियों से इनपुट के आधार पर अतिरिक्त पुनर्प्रशिक्षण था। इससे पता चलता है कि यह मॉडल वास्तव में बड़ा और समझदार नहीं हुआ है, बल्कि इसने लोगों को बेतहाशा हंसी देने के लिए अपनी प्रतिक्रियाओं को अनुकूलित करने की क्षमता में महारत हासिल कर ली है।
| अधिक जानकारी: StackOverflow ट्रैफ़िक कम हो जाता है ChatGPT शुरूआत |
ChatGPT: प्रचार में भारी उछाल
अपने पूर्ववर्ती निर्देश के लगभग 10 महीने बादGPT/GGPT-3.5, ChatGPT पेश किया गया था। तुरंत, इसने वैश्विक प्रचार का कारण बना।
तकनीकी दृष्टिकोण से, ऐसा प्रतीत नहीं होता कि इनके बीच कोई महत्वपूर्ण अंतर है ChatGPT और निर्देश देंGPT. मॉडल को अतिरिक्त संवाद डेटा के साथ प्रशिक्षित किया गया था क्योंकि "एआई सहायक नौकरी" के लिए एक अद्वितीय संवाद प्रारूप की आवश्यकता होती है, उदाहरण के लिए, यदि उपयोगकर्ता का अनुरोध अस्पष्ट है तो स्पष्ट प्रश्न पूछने की क्षमता।
तो, आसपास कोई उत्साह क्यों नहीं था GPT-3.5 जबकि 2022 की शुरुआत में ChatGPT जंगल की आग की तरह पकड़ लिया गया? सैम ऑल्टमैन, कार्यकारी निदेशक OpenAI, खुले तौर पर स्वीकार किया कि जिन शोधकर्ताओं को हमने देखकर आश्चर्यचकित कर दिया ChatGPTकी त्वरित सफलता. आख़िरकार, इसके बराबर क्षमताओं वाला एक मॉडल उस समय दस महीने से अधिक समय से उनकी वेबसाइट पर निष्क्रिय पड़ा हुआ था, और कोई भी इस कार्य के लिए तैयार नहीं था।
| अधिक जानकारी: ChatGPT व्हार्टन एमबीए परीक्षा उत्तीर्ण की |
यह अविश्वसनीय है, लेकिन ऐसा प्रतीत होता है कि नया उपयोगकर्ता-अनुकूल इंटरफ़ेस इसकी सफलता की कुंजी है। वही निर्देशGPT इसे केवल एक अद्वितीय एपीआई इंटरफ़ेस के माध्यम से ही एक्सेस किया जा सकता है, जिससे मॉडल तक लोगों की पहुंच सीमित हो जाती है। ChatGPTदूसरी ओर, मैसेंजर के सुप्रसिद्ध "डायलॉग विंडो" इंटरफ़ेस का उपयोग करता है। इसके अलावा, तब से ChatGPT एक ही बार में सभी के लिए उपलब्ध था, तंत्रिका नेटवर्क के साथ बातचीत करने, उन्हें स्क्रीन करने और उन्हें पोस्ट करने के लिए व्यक्तियों की भगदड़ मच गई सोशल मीडिया, दूसरों को सम्मोहित करना।
| अधिक जानकारी: अमेरिका की शिक्षा प्रणाली को 300k शिक्षकों की सख्त जरूरत है - लेकिन ChatGPT उत्तर हो सकता है |
महान प्रौद्योगिकी के अलावा, एक और काम सही ढंग से किया गया OpenAI: विपणन। भले ही आपके पास सबसे अच्छा मॉडल या सबसे बुद्धिमान चैटबॉट हो, अगर इसमें उपयोग में आसान इंटरफ़ेस नहीं है, तो किसी को भी इसमें दिलचस्पी नहीं होगी। इस संबंध में, ChatGPT पारंपरिक संवाद बॉक्स का उपयोग करके आम जनता के लिए प्रौद्योगिकी को पेश करके एक सफलता हासिल की, जिसमें एक सहायक रोबोट हमारी आंखों के ठीक सामने, शब्द दर शब्द समाधान को "प्रिंट" करता है।
आश्चर्य, ChatGPT नए उपयोगकर्ताओं को आकर्षित करने के पिछले सभी रिकॉर्ड तोड़ दिए, लॉन्च के केवल पांच दिनों में 1 मिलियन उपयोगकर्ताओं के मील के पत्थर को पार कर लिया और केवल दो महीनों में 100 मिलियन उपयोगकर्ताओं को पार कर लिया।
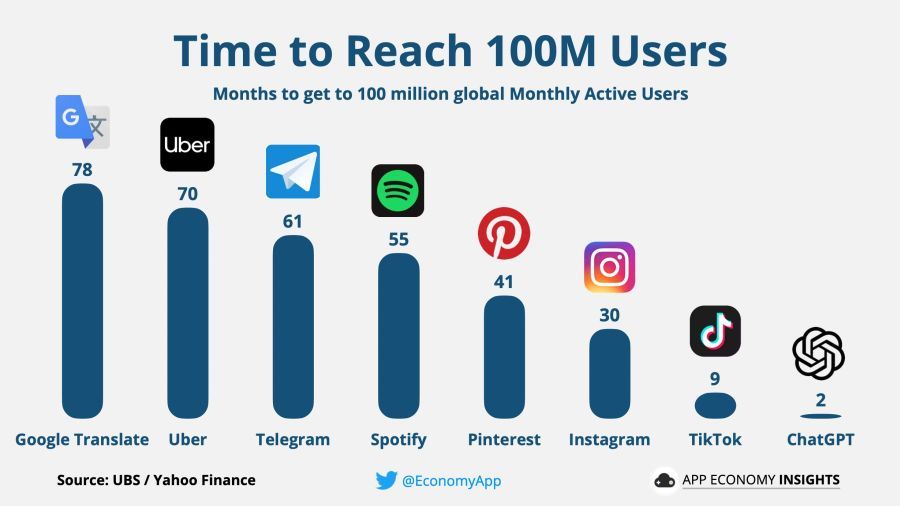
बेशक, जहां यूजर्स में रिकॉर्ड तोड़ उछाल है, वहां जबरदस्त पैसा है। चीनियों ने तत्काल अपनी खुद की आसन्न रिहाई की घोषणा की chatbot, माइक्रोसॉफ्ट ने तुरंत एक सौदा कर लिया OpenAI उनमें अरबों डॉलर का निवेश करने के लिए, और Google इंजीनियरों ने अलार्म बजाया और अपनी खोज सेवा को तंत्रिका नेटवर्क के साथ प्रतिस्पर्धा से बचाने के लिए योजनाएँ तैयार करना शुरू कर दिया।
| अधिक जानकारी: ChatGPT जनवरी में 100 मिलियन से अधिक के साथ दर्शकों की संख्या में वृद्धि का रिकॉर्ड तोड़ दिया |
सारांश: जब ChatGPT मॉडल नवंबर 2022 में पेश किया गया था, कोई उल्लेखनीय तकनीकी प्रगति नहीं हुई थी। हालाँकि, इसमें उपयोगकर्ता जुड़ाव और खुली पहुंच के लिए एक सुविधाजनक इंटरफ़ेस था, जिसने तुरंत प्रचार में भारी वृद्धि की। चूँकि आधुनिक दुनिया में यह सबसे महत्वपूर्ण मुद्दा है, इसलिए सभी ने तुरंत भाषा मॉडल से निपटना शुरू कर दिया।
एआई के बारे में और पढ़ें:
Disclaimer
साथ लाइन में ट्रस्ट परियोजना दिशानिर्देश, कृपया ध्यान दें कि इस पृष्ठ पर दी गई जानकारी का कानूनी, कर, निवेश, वित्तीय या किसी अन्य प्रकार की सलाह के रूप में व्याख्या करने का इरादा नहीं है और न ही इसकी व्याख्या की जानी चाहिए। यह महत्वपूर्ण है कि केवल उतना ही निवेश करें जितना आप खो सकते हैं और यदि आपको कोई संदेह हो तो स्वतंत्र वित्तीय सलाह लें। अधिक जानकारी के लिए, हम नियम और शर्तों के साथ-साथ जारीकर्ता या विज्ञापनदाता द्वारा प्रदान किए गए सहायता और समर्थन पृष्ठों का संदर्भ लेने का सुझाव देते हैं। MetaversePost सटीक, निष्पक्ष रिपोर्टिंग के लिए प्रतिबद्ध है, लेकिन बाज़ार की स्थितियाँ बिना सूचना के परिवर्तन के अधीन हैं।
के बारे में लेखक
दामिर टीम लीडर, उत्पाद प्रबंधक और संपादक हैं Metaverse Postएआई/एमएल, एजीआई, एलएलएम, मेटावर्स और जैसे विषयों को कवर करता है Web3-संबंधित क्षेत्रों। उनके लेख हर महीने दस लाख से अधिक उपयोगकर्ताओं को आकर्षित करते हैं। ऐसा प्रतीत होता है कि वह SEO और डिजिटल मार्केटिंग में 10 वर्षों के अनुभव वाला एक विशेषज्ञ है। दामिर का उल्लेख मैशबल, वायर्ड, में किया गया है Cointelegraph, द न्यू यॉर्कर, Inside.com, एंटरप्रेन्योर, BeInCrypto, और अन्य प्रकाशन। वह एक डिजिटल खानाबदोश के रूप में संयुक्त अरब अमीरात, तुर्की, रूस और सीआईएस के बीच यात्रा करता है। दामिर ने भौतिकी में स्नातक की डिग्री हासिल की, उनका मानना है कि इससे उन्हें इंटरनेट के लगातार बदलते परिदृश्य में सफल होने के लिए आवश्यक महत्वपूर्ण सोच कौशल प्राप्त हुआ है।
और अधिक लेख
दामिर टीम लीडर, उत्पाद प्रबंधक और संपादक हैं Metaverse Postएआई/एमएल, एजीआई, एलएलएम, मेटावर्स और जैसे विषयों को कवर करता है Web3-संबंधित क्षेत्रों। उनके लेख हर महीने दस लाख से अधिक उपयोगकर्ताओं को आकर्षित करते हैं। ऐसा प्रतीत होता है कि वह SEO और डिजिटल मार्केटिंग में 10 वर्षों के अनुभव वाला एक विशेषज्ञ है। दामिर का उल्लेख मैशबल, वायर्ड, में किया गया है Cointelegraph, द न्यू यॉर्कर, Inside.com, एंटरप्रेन्योर, BeInCrypto, और अन्य प्रकाशन। वह एक डिजिटल खानाबदोश के रूप में संयुक्त अरब अमीरात, तुर्की, रूस और सीआईएस के बीच यात्रा करता है। दामिर ने भौतिकी में स्नातक की डिग्री हासिल की, उनका मानना है कि इससे उन्हें इंटरनेट के लगातार बदलते परिदृश्य में सफल होने के लिए आवश्यक महत्वपूर्ण सोच कौशल प्राप्त हुआ है।






