



T9-ajastu vestlusrobotite areng ja GPT-1 et ChatGPT






Viimasel ajal on meid peaaegu iga päev pommitatud uudistepostitustega, mis räägivad viimastest rekorditest, mille on purustanud suuremahulised närvivõrgud ja miks pole peaaegu kellegi töökoht ohutu. Sellegipoolest on väga vähesed inimesed teadlikud sellest, kuidas närvivõrgud meeldivad ChatGPT tegelikult tegutsevad.
Niisiis, lõdvestu. Ärge veel kurvastage oma tööväljavaadete pärast. Selles postituses selgitame kõike, mida on vaja närvivõrkude kohta teada, nii, et igaüks sellest aru saaks.

Hoiatus enne alustamist: see tükk on koostöö. Kogu tehnilise osa kirjutas AI-spetsialist, kes on tehisintellekti rahva seas hästi tuntud.
Kuna keegi pole veel põhjalikku kirjatükki kirjutanud, kuidas ChatGPT teoseid, mis selgitavad võhiku terminites närvivõrkude läbi ja lõhki, otsustasime seda teie heaks teha. Oleme püüdnud hoida selle postituse võimalikult lihtsana, et lugejad saaksid seda postitust lugedes üldiselt aru keele närvivõrkude põhimõtetest. Uurime, kuidas keelemudelid seal töötades, kuidas närvivõrgud arenesid oma praeguste võimaluste saavutamiseks ja miks ChatGPTplahvatuslik populaarsus üllatas isegi selle loojaid.
Alustame põhitõdedest. Aru saama ChatGPT tehnilisest seisukohast peame esmalt aru saama, mis see ei ole. See pole Marvel Comicsi Jarvis; see ei ole ratsionaalne olend; see ei ole džinn. Valmistuge šokiks: ChatGPT on tegelikult teie mobiiltelefoni T9 steroididel! Jah, see on nii: teadlased nimetavad mõlemat tehnoloogiat kui "keelemudelid." Kõik närvivõrgud arvavad ära, milline sõna peaks järgmisena tulema.
Algne T9-tehnoloogia kiirendas ainult telefoni nuppnumbrite valimist, arvates ära praeguse sisendi, mitte järgmise sõna. Tehnoloogia arenes aga edasi ja nutitelefonide ajastuks 2010. aastate alguses suutis see arvestada konteksti ja sõna eelnevaga, lisada kirjavahemärke ja pakkuda valikut sõnu, mida võiks järgmisena kasutada. Täpselt sellist analoogiat teeme T9 "täiustatud" versiooniga ehk automaatkorrektsiooniga.
Selle tulemusena on nii T9 nutitelefoni klaviatuuril kui ka ChatGPT on koolitatud lahendama naeruväärselt lihtsat ülesannet: järgmise sõna ennustamine. Seda nimetatakse "keele modelleerimiseks" ja see toimub siis, kui olemasoleva teksti põhjal tehakse otsus selle kohta, mida järgmiseks kirjutada. Keelemudelid peavad selliste ennustuste tegemiseks lähtuma konkreetsete sõnade esinemise tõenäosustest. Lõppude lõpuks oleksite nördinud, kui teie telefoni automaatne täitmine paiskaks teile sama tõenäosusega täiesti juhuslikke sõnu.
Selguse huvides kujutame ette, et saate sõbralt sõnumi. Seal on kirjas: "Mis plaanid teil õhtuks on?" Vastuseks hakkate tippima: "Ma lähen..." ja siin tuleb sisse T9. See võib tulla täiesti mõttetute asjadega, nagu "ma lähen Kuule", keerulist keelemudelit pole vaja. Head nutitelefonide automaatse täitmise mudelid pakuvad palju asjakohasemaid sõnu.
Niisiis, kuidas T9 teab, millised sõnad järgivad tõenäolisemalt juba trükitud teksti ja millel pole selgelt mõtet? Sellele küsimusele vastamiseks peame esmalt uurima kõige lihtsamate tööpõhimõtteid närvivõrgud.
Kuidas AI mudelid ennustavad järgmist sõna
Alustame lihtsama küsimusega: kuidas ennustate teatud asjade vastastikust sõltuvust teistest? Oletame, et tahame õpetada arvutit ennustama inimese kaalu tema pikkuse põhjal – kuidas me peaksime seda tegema? Peaksime esmalt tuvastama huvipakkuvad valdkonnad ja seejärel koguma andmeid, mille põhjal saaksime otsida huvipakkuvaid sõltuvusi, ning seejärel püüdma "koolitada" mõnda matemaatilist mudelit et otsida nendest andmetest mustreid.
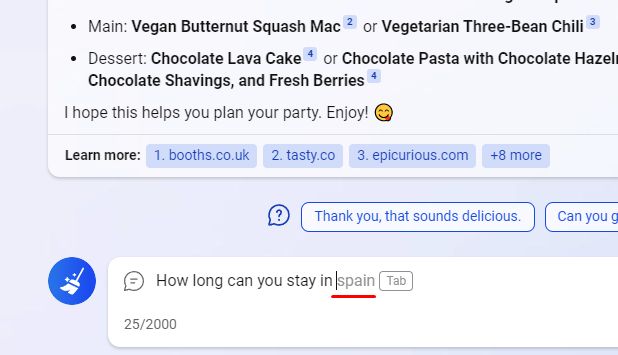
Lihtsamalt öeldes T9 või ChatGPT on lihtsalt nutikalt valitud võrrandid, mis seda üritavad ennustada sõna (Y), mis põhineb mudeli sisendisse sisestatud eelmiste sõnade (X) hulgal. Treenides a keelemudel andmekogumi puhul on põhiülesanne valida nende x-ide jaoks koefitsiendid, mis peegeldavad tõeliselt mingit sõltuvust (nagu meie näites pikkuse ja kaalu puhul). Ja suurte mudelite abil saame paremini aru neist, millel on palju parameetreid. Valdkonnas tehisintellekti, nimetatakse neid suurteks keelemudeliteks või lühendatult LLM-ideks. Nagu hiljem näeme, on hea teksti genereerimiseks hädavajalik suur paljude parameetritega mudel.
Muide, kui te ei tea, miks me samal ajal pidevalt räägime "ühe järgmise sõna ennustamisest". ChatGPT vastab kiiresti tervete tekstilõikudega, vastus on lihtne. Muidugi suudavad keelemudelid luua pikki tekste ilma raskusteta, kuid kogu protsess toimub sõna-sõnalt. Pärast iga uue sõna loomist käivitab mudel lihtsalt kogu teksti koos uue sõnaga, et luua järgmine sõna. Protsessi kordub ikka ja jälle, kuni saate kogu vastuse.
Miks me püüame leida antud teksti jaoks "õigeid" sõnu?
Keelemudelid püüavad ennustada erinevate sõnade tõenäosust, mis antud tekstis võivad esineda. Miks see vajalik on ja miks ei võiks otsida “kõige õigemat” sõna? Proovime selle protsessi toimimise illustreerimiseks lihtsat mängu.
Reeglid on järgmised: Teen ettepaneku jätkata lauset: "USA 44. president (ja esimene afroameeriklane sellel ametikohal) on Barak...". Mis sõna peaks järgmiseks minema? Kui suur on selle esinemise tõenäosus?
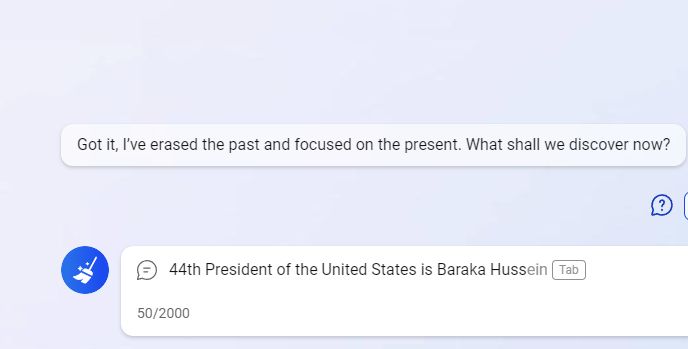
Kui ennustasite 100% kindlusega, et järgmine sõna on "Obama", siis eksite! Ja mõte pole siin selles, et on veel üks müütiline Barak; see on palju triviaalsem. Ametlikes dokumentides kasutatakse tavaliselt presidendi täisnime. See tähendab, et Obama eesnimele järgneb tema keskmine nimi Hussein. Seega peaks meie lauses õigesti koolitatud keelemudel ennustama, et "Obama" on järgmine sõna ainult tingimusliku tõenäosusega 90%, ja eraldama ülejäänud 10%, kui teksti jätkab "Hussein" (pärast seda teeb Obama järgida 100% lähedase tõenäosusega.
Ja nüüd jõuame keelemudelite intrigeeriva aspektini: nad ei ole immuunsed loominguliste löökide eest! Tegelikult valivad sellised mudelid iga järgmise sõna genereerimisel selle "juhuslikult", justkui viskaksid täringuid. Erinevate sõnade “väljakukkumise” tõenäosus vastab enam-vähem tõenäosustele, mida pakuvad mudelisse sisestatud võrrandid. Need on tuletatud tohutust hulgast erinevatest tekstidest, mille mudel oli ette söönud.
Selgub, et modell võib samadele taotlustele erinevalt vastata, nagu ka elav inimene. Teadlased on üldiselt püüdnud sundida neuroneid valima alati "kõige tõenäolisema" järgmise sõna, kuid kuigi see tundub pealtnäha ratsionaalne, toimivad sellised mudelid tegelikkuses halvemini. Tundub, et paras annus juhuslikkust on kasulik, kuna see suurendab vastuste varieeruvust ja kvaliteeti.
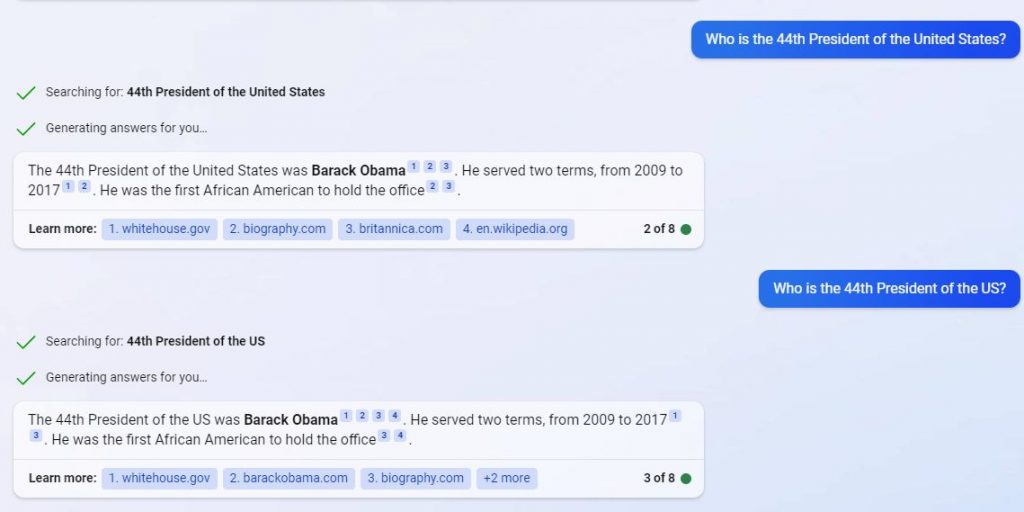
Meie keelel on ainulaadne struktuur erinevate reeglite ja eranditega. Lauses esinevatel sõnadel on riim ja põhjus, need ei esine lihtsalt juhuslikult. Igaüks õpib alateadlikult selgeks kasutatava keele reeglid oma varases kujunemisaastas.
Korralik mudel peaks arvestama keele laia kirjelduse ulatust. Modelli oma võime saavutada soovitud tulemusi oleneb sellest, kui täpselt ta konteksti peensustest lähtuvalt sõnade tõenäosusi arvutab (eelmine asjaolu selgitav tekstiosa).
Kokkuvõte: Lihtsaid keelemudeleid, mis on suurel hulgal andmetel treenitud võrrandite kogum, et ennustada sisendallika teksti põhjal järgmist sõna, on nutitelefonide funktsioonis T9/Autofill rakendatud alates 2010. aastate algusest.
GPT-1: Tööstuse õhkulaskmine
Läheneme T9 mudelitest eemale. Sel ajal, kui te tõenäoliselt seda kirjatükki loed Õppima millegi kohta ChatGPT, esiteks peame arutama selle algust GPT mudelperekond.
GPT tähistab "generatiivset eelkoolitatud trafot", samas kui Google'i inseneride poolt välja töötatud närvivõrgu arhitektuur aastal 2017 on tuntud kui Transformer. Transformer on universaalne arvutusmehhanism, mis aktsepteerib jadade (andmete) kogumit sisendina ja loob sama jadakomplekti, kuid erineval kujul, mida on mõne algoritmi abil muudetud.
Transformeri loomingu olulisust võib näha selles, kui agressiivselt see kasutusele võeti ja rakendati tehisintellekti (AI) kõigis valdkondades: tõlkimises, pildi-, heli- ja videotöötluses. Tehisintellekti (AI) sektoris toimus võimas raputus, liikudes nn “AI stagnatsioonist” kiirele arengule ja stagnatsioonist ülesaamisele.
Transformeri põhitugevuse moodustavad lihtsalt skaleeritavad moodulid. Kui paluda töödelda korraga suur hulk teksti, aeglustusid vanad, transformerieelsed keelemudelid. Teisest küljest saavad transformaatori närvivõrgud selle ülesandega palju paremini hakkama.
Varem tuli sisendandmeid töödelda järjestikku või ükshaaval. Mudel ei säilitaks andmeid: kui see töötaks üheleheküljelise narratiiviga, unustaks see pärast lugemist teksti. Vahepeal võimaldab Transformer vaadata kõike korraga, tootmine oluliselt hämmastavamad tulemused.
Just see võimaldas läbimurret tekstide töötlemisel närvivõrkude abil. Selle tulemusena ei unusta mudel enam: see kasutab uuesti varem kirjutatud materjali, mõistab paremini konteksti ja mis kõige olulisem, suudab sõnu omavahel sidudes luua seoseid ülisuurte andmemahtude vahel.
Kokkuvõte: GPT-1, mis debüteeris 2018. aastal, näitas, et närvivõrk suudab toota tekste kasutades Transformeri disaini, mis on oluliselt parandanud skaleeritavust ja tõhusust. Kui oleks võimalik suurendada keelemudelite hulka ja keerukust, tekitaks see märkimisväärse reservi.
GPT-2: Suurte keelemudelite ajastu
Keelemudeleid ei pea eelnevalt spetsiaalselt märgistama ja neid saab "sööda" mis tahes tekstiandmetega, muutes need äärmiselt paindlikuks. Kui sellele veidi järele mõelda, tundub mõistlik, et tahame selle võimeid kasutada. Igasugune tekst, mis on kunagi kirjutatud, on valmis treeningandmeteks. Kuna seal on juba nii palju jadasid, mis on tüüpilised "palju mõnda sõna ja fraasi => järgmine sõna nende järel", pole see üllatav.
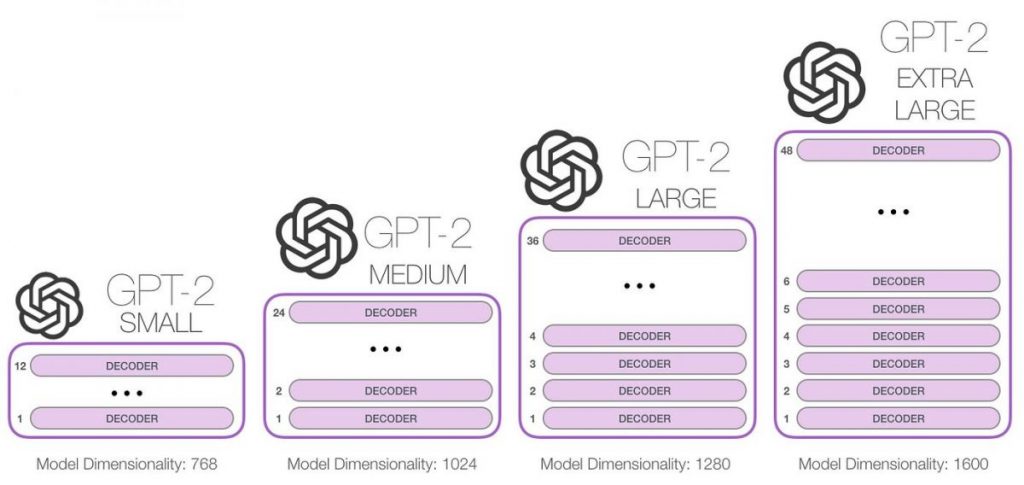
Nüüd pidagem meeles ka seda, et Transformersi tehnoloogiat testiti GPT-1 osutus skaleerimise osas üsna edukaks: see on suurte andmemahtude käsitlemisel tunduvalt tõhusam kui tema eelkäijad. Selgub, et teadlased alates OpenAI jõudis 2019. aastal samale järeldusele: "On aeg kärpida kalleid keelemudeleid!"
. koolituse andmekogum ja mudel eelkõige suurus valiti kaheks oluliseks valdkonnaks, kus GPT-2 vajas drastilist parandamist.
Kuna sel ajal ei olnud spetsiaalselt keelemudelite koolitamiseks mõeldud suuri ja kvaliteetseid avaliku teksti andmekogumeid, pidi iga AI ekspertide meeskond andmetega ise manipuleerima. The OpenAI Seejärel otsustasid inimesed minna Redditi, kõige populaarsemasse ingliskeelsesse foorumisse ja ekstraheerida kõik hüperlingid igast postitusest, millel oli rohkem kui kolm meeldimist. Neid linke oli ligi 8 miljonit ja allalaaditud tekstid kaalusid kokku 40 terabaiti.
Kui palju parameetreid oli suurimat kirjeldav võrrand GPT-2 mudeli 2019 on? Võib-olla sada tuhat või paar miljonit? Noh, läheme veelgi kaugemale: valem sisaldas kuni 1.5 miljardit sellist parameetrit. Nii paljude numbrite faili kirjutamiseks ja arvutisse salvestamiseks kulub 6 terabaiti. Mudel ei pea seda teksti kui tervikut meelde jätma, nii et ühest küljest on see palju väiksem kui selle teksti andmemassiivi kogumaht, millel mudel treeniti; piisab, kui ta leiab lihtsalt mingid sõltuvused (mustrid, reeglid), mida saab inimeste kirjutatud tekstidest eraldada.
Mida paremini mudel tõenäosust prognoosib ja mida rohkem parameetreid see sisaldab, seda keerulisem on võrrand mudelisse ühendatud. See muudab usaldusväärse teksti. Lisaks on GPT-2 mudel hakkas nii hästi toimima, et OpenAI Teadlased turvakaalutlustel ei soovinud isegi mudelit avalikult avaldada.
On väga huvitav, et kui modell saab suuremaks, hakkavad tal äkki uued omadused (nagu võime kirjutada sidusaid, sisukaid esseesid, selle asemel et lihtsalt telefonis järgmist sõna dikteerida).
Sel hetkel toimub muutus kvantiteedilt kvaliteedile. Lisaks toimub see täiesti mittelineaarselt. Näiteks parameetrite arvu kolmekordne suurendamine 115 miljonilt 350 miljonile ei avalda märgatavat mõju mudeli võimele probleeme täpselt lahendada. Kahekordne kasv 700 miljonini toob aga kaasa kvalitatiivse hüppe, kus närvivõrk “näeb valgust” ja hakkab kõiki hämmastama oma võimega ülesandeid täita.
Kokkuvõte: 2019. aastal võeti kasutusele GPT-2, mis mudeli suuruse (parameetrite arvu) ja koolitusteksti andmete mahu poolest ületas oma eelkäijat 10 korda. Tänu sellele kvantitatiivsele edusammule omandas mudel ettearvamatult kvalitatiivselt uusi andeid, nagu näiteks võime kirjutage pikki esseesid selge tähendusega ja lahendama väljakutseid pakkuvaid probleeme, mis nõuavad maailmavaatelisi aluseid.
GPT-3: Pagana tark
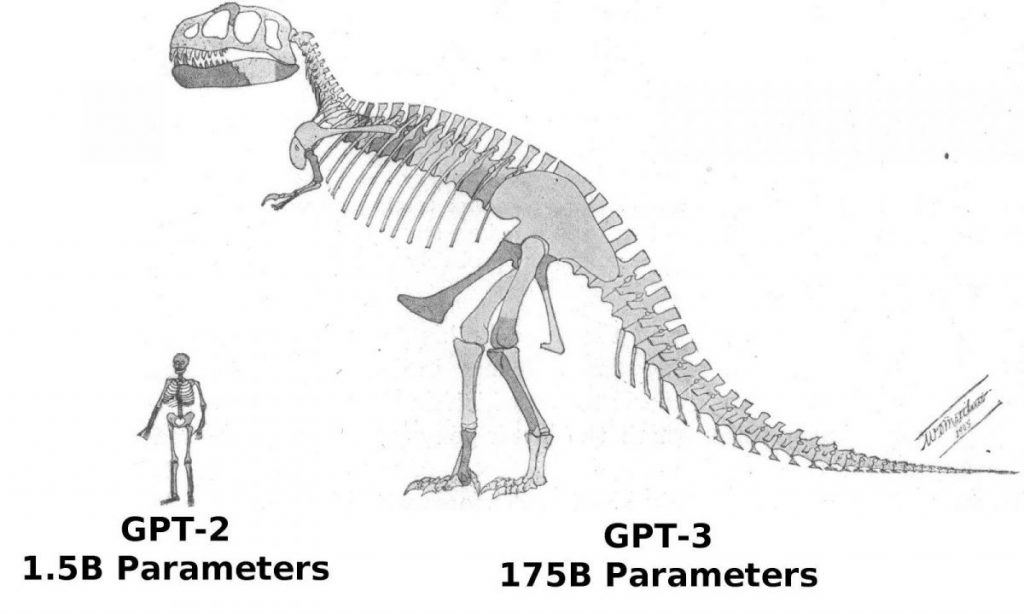
Üldiselt on 2020. aasta väljalase GPT-3, seeria järgmise põlvkonna parameetrid, on juba 116 korda rohkem – kuni 175 miljardit ja hämmastavad 700 terabaiti.
. GPT-3 Samuti laiendati treeningandmete kogumit, kuigi mitte nii drastiliselt. See kasvas peaaegu 10 korda 420 gigabaidini ja sisaldab nüüd suurt hulka raamatuid, Wikipediaartikleid ja muid tekste teistelt veebisaitidelt. Inimesel kuluks umbes 50 aastat pidevat lugemist, mis muudab selle võimatuks.
Märkad kohe intrigeerivat erinevust: erinevalt GPT-2, on mudel ise nüüd 700 GB suurem kui kogu koolituse jaoks mõeldud tekstimassiv (420 GB). See osutub teatud mõttes paradoksiks: sel juhul genereerib "neuroaju" algandmeid uurides teavet nende erinevate vastastikuste sõltuvuste kohta, mis on mahuliselt rikkalikum kui algsed andmed.
Mudeli üldistamise tulemusena suudab see nüüd veelgi edukamalt ekstrapoleerida kui varem ja on edukas ka tekstiloomeülesannetes, mida koolitusel esines harva või üldse mitte. Nüüd ei pea te mudelile õpetama, kuidas teatud probleemiga toime tulla; piisab nende kirjeldamisest ja mõne näite toomisest ning GPT-3 õpib koheselt.
. "Universaalne aju" kujul GPT-3 alistas lõpuks paljud varasemad spetsialiseeritud mudelid. Näiteks, GPT-3 hakkas prantsuse või saksa keelest tekste tõlkima kiiremini ja täpsemalt kui ükski varasem spetsiaalselt selleks loodud närvivõrk. Kuidas? Lubage mul teile meelde tuletada, et me räägime keelelisest mudelist, mille ainus eesmärk oli püüda ette näha järgmist sõna antud tekstis.
Veelgi hämmastavam, GPT-3 suutis ennast õpetada... matemaatikat! Allolev graafik illustreerib, kui hästi närvivõrgud täidavad ülesandeid, sealhulgas liitmist ja lahutamist ning kuni viiekohaliste täisarvude korrutamist erineva arvu parameetritega. Nagu näete, hakkavad närvivõrgud matemaatikas äkitselt "suutma", liikudes 10 miljardi parameetriga mudelitelt 100 miljardi parameetriga mudeliteni.
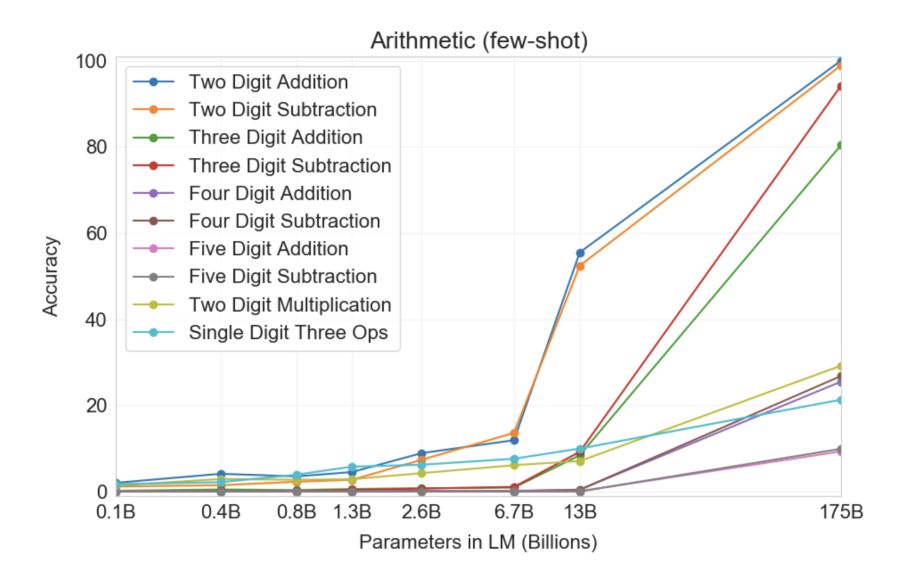
Eelnimetatud graafiku kõige intrigeerivam omadus on see, et esialgu ei näi mudeli suuruse kasvades (vasakult paremale) midagi muutuvat, kuid äkki p korda! Toimub kvalitatiivne nihe ja GPT-3 hakkab "mõistma", kuidas teatud probleemi lahendada. Keegi pole kindel, kuidas, mida või miks see toimib. Siiski tundub, et see töötab paljudes muudes raskustes ja ka matemaatikas.
Eelnimetatud graafiku kõige intrigeerivam omadus on see, et kui mudeli suurus suureneb, siis esiteks ei näi midagi muutuvat ja seejärel, GPT-3 teeb kvalitatiivse hüppe ja hakkab "mõistma", kuidas teatud probleemi lahendada.
Allolev gif lihtsalt demonstreerib, kuidas parameetrite arvu kasvades mudelisse “võrravad” uued võimed, mida keegi teadlikult välja ei planeerinud:
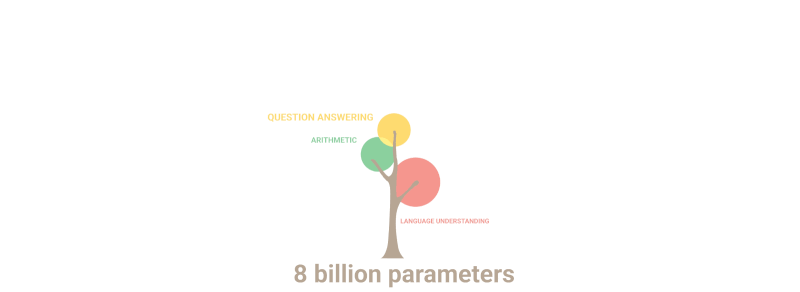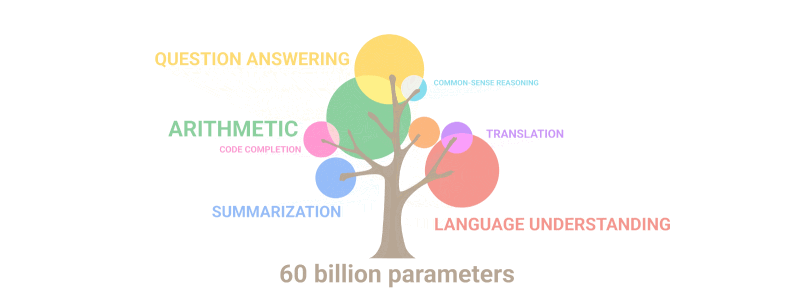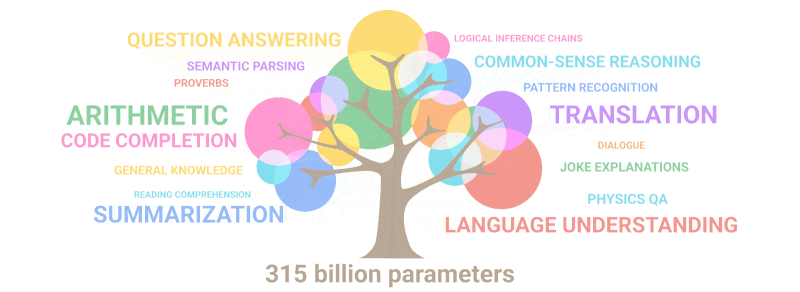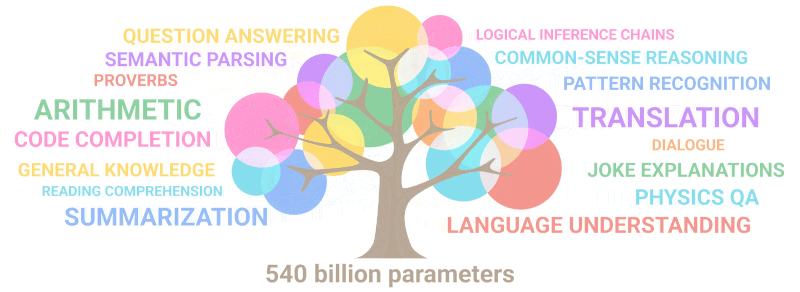
Kokkuvõte: Parameetrite osas on 2020.a GPT-3 oli 100 korda suurem kui tema eelkäija, samas kui koolitusteksti andmed olid 10 korda suuremad. Taas õppis mudel järsult kvaliteeti tõstnud kvantiteedi suurenemise tulemusel tõlkima teistest keeltest, sooritama aritmeetikat, teostama lihtsat programmeerimist, järjestikku arutlema ja palju muud.
GPT-3.5 (JuhendageGPT): Mudel on koolitatud olema ohutu ja mittetoksiline
Tegelikkuses ei taga keelemudelite laiendamine, et see reageerib päringutele nii, nagu kasutajad seda soovivad. Tegelikult tahame taotluse esitamisel sageli kasutada mitmeid väljaütlemata termineid, mida inimsuhtluses peetakse tõeks.
Kuid ausalt öeldes pole keelemudelid inimeste omadele kuigi lähedased. Seetõttu peavad nad sageli mõtlema mõistetele, mis inimestele lihtsad tunduvad. Üks selline soovitus on fraas "mõtleme samm-sammult". Oleks fantastiline, kui modellid saaksid päringust aru või genereeriksid konkreetsemaid ja asjakohasemaid juhiseid ning järgiksid neid täpsemalt, justkui aimateks ette, kuidas inimene oleks käitunud.
Asjaolu, et GPT-3 on treenitud ainult järgmist sõna ette nägema massilises Interneti-tekstide kogus, kirjutatakse palju erinevaid asju, mis aitab kaasa selliste "vaikimisi" võimete puudumisele. Inimesed tahavad, et tehisintellekt annaks asjakohast teavet, säilitades samal ajal vastused ohutu ja mittetoksilisena.
Kui teadlased selle küsimuse üle veidi mõtlesid, sai selgeks, et mudeli atribuudid "täpsus ja kasulikkus" ning "kahjutus ja mittetoksilisus" näisid mõnikord olevat üksteisega vastuolus. Lõppude lõpuks reageerib maksimaalsele kahjutusele häälestatud mudel igale viipale "Vabandust, ma olen mures, et minu vastus võib kedagi Internetis solvata." Täpne mudel peaks ausalt vastama päringule: "Olgu, Siri, kuidas pommi luua."
Seetõttu piirdusid teadlased lihtsalt mudelile palju tagasiside andmisega. Teatud mõttes õpivad lapsed moraali just nii: nad katsetavad lapsepõlves ja samal ajal uurivad nad hoolikalt täiskasvanute reaktsioone, et hinnata, kas nad käitusid õigesti.
JuhendaGPT, tuntud ka kui GPT-3.5, on sisuliselt GPT-3 mis sai oma vastuste täiustamiseks palju tagasisidet. Sõna otseses mõttes koguti ühte kohta mitu inimest, kes hindasid närvivõrgu vastuseid, et teha kindlaks, kui hästi nad vastavad nende ootustele nende esitatud taotluse valguses.
Selgub, et GPT-3 on juba saanud kõik olulised teadmised: ta suudab mõista paljusid keeli, meenutada ajaloolisi sündmusi, tuvastada autoristiilide variatsioone jne, kuid ta saab õppida neid teadmisi õigesti (meie vaatenurgast) kasutama ainult siis, kui see on pärit teised isikud. GPT-3.5 võib pidada „ühiskonna haritud” mudeliks.
Kokkuvõte: Peamine funktsioon GPT-3.5, mis võeti kasutusele 2022. aasta alguses, oli täiendav ümberõpe, mis põhines üksikisikute sisendil. Selgub, et see mudel ei ole tegelikult muutunud suuremaks ja targemaks, vaid pigem on see omandanud võime kohandada oma vastuseid nii, et inimesed saaksid kõige pöörasemalt naerda.
ChatGPT: suur hüppeline hüpe
Umbes 10 kuud pärast selle eelkäijat InstructGPT/GGPT-3.5, ChatGPT tutvustati. Kohe tekitas see ülemaailmset kõmu.
Tehnoloogilisest vaatenurgast ei paista, et nende vahel oleks olulisi erinevusi ChatGPT ja juhendadaGPT. Mudelit koolitati täiendavate dialoogiandmetega, kuna AI assistendi töö nõuab ainulaadset dialoogivormingut, näiteks võimalust esitada täpsustav küsimus, kui kasutaja päring on ebaselge.
Niisiis, miks ümberringi ei olnud hype GPT-3.5 2022. aasta alguses samal ajal ChatGPT kulutulena tabatud? Sam Altman, Tegevdirektor OpenAI, tunnistas avalikult, et teadlased tabasid meid üllatusena ChatGPTkohene edu. Temaga võrreldavate võimetega modell oli ju selleks hetkeks nende veebisaidil uinunud üle kümne kuu ja keegi polnud oma ülesannete kõrgusel.
See on uskumatu, kuid tundub, et uus kasutajasõbralik liides on selle edu võti. Sama juhendamineGPT pääseb juurde ainult ainulaadse API liidese kaudu, piirates inimeste juurdepääsu mudelile. ChatGPT, ob teisest küljest kasutab sõnumitoojate tuntud dialoogiakna liidest. Samuti, kuna ChatGPT oli kõigile korraga kättesaadav, hulk inimesi kiirustas närvivõrguga suhtlema, neid sõeluma ja veebile postitama. Sotsiaalse meedia, erutades teisi.
Lisaks suurepärasele tehnoloogiale tehti veel üks asi õigesti OpenAI: turundus. Isegi kui teil on parim mudel või kõige intelligentsem vestlusbot, kui sellel pole lihtsalt kasutatavat liidest, ei huvita see kedagi. Sellega seoses ChatGPT saavutas läbimurde, tutvustades tehnoloogiat laiemale avalikkusele tavapärase dialoogiboksi abil, kus abivalmis robot “prindib” lahenduse sõna-sõnalt otse meie silme ette.
Pole üllatav, ChatGPT saavutas kõik varasemad rekordid uute kasutajate ligimeelitamises, ületades 1 miljoni kasutaja verstaposti vaid viie päevaga alates selle käivitamisest ja ületades 100 miljoni kasutaja piiri vaid kahe kuuga.
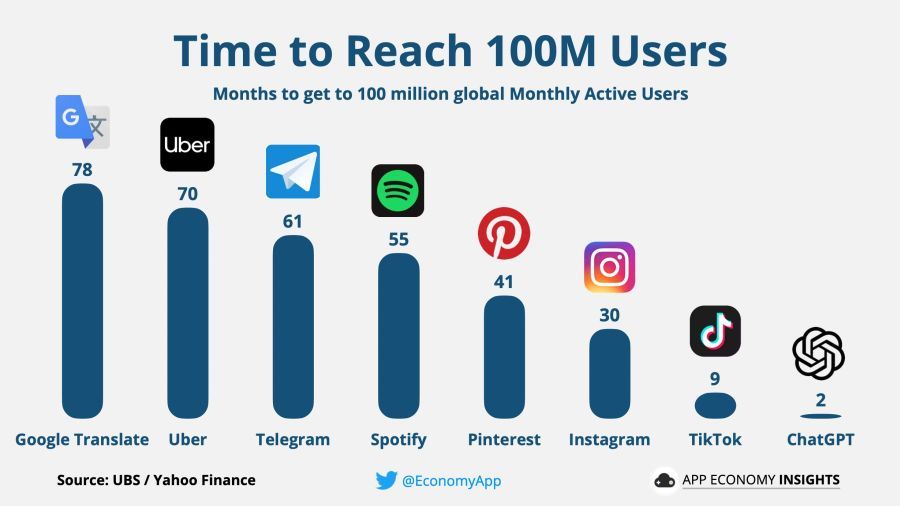
Muidugi, seal, kus kasutajate arv on rekordiline, on raha tohutult palju. Hiinlased teatasid kiiresti omaenda eelseisvast vabastamisest chatbot, Microsoft sõlmis kiiresti kokkuleppe OpenAI investeerida neisse kümneid miljardeid dollareid ning Google'i insenerid lõid häirekella ja asusid koostama plaane, kuidas kaitsta oma otsinguteenust närvivõrgu konkurentsi eest.
Kokkuvõte: Kui ChatGPT mudelit tutvustati 2022. aasta novembris, märkimisväärseid tehnoloogilisi edusamme ei toimunud. Sellel oli aga mugav liides kasutajate kaasamiseks ja avatud juurdepääs, mis kutsus kohe esile tohutu hüpe. Kuna see on kaasaegse maailma kõige olulisem probleem, hakkasid kõik kohe keelemudelitega tegelema.
Loe AI kohta lähemalt:
Kaebused
Vastavalt Usaldusprojekti juhised, pange tähele, et sellel lehel esitatud teave ei ole mõeldud ega tohiks tõlgendada kui juriidilist, maksu-, investeerimis-, finants- või muud nõuannet. Oluline on investeerida ainult seda, mida saate endale lubada kaotada, ja kahtluste korral küsida sõltumatut finantsnõu. Lisateabe saamiseks soovitame vaadata nõudeid ja tingimusi ning väljaandja või reklaamija pakutavaid abi- ja tugilehti. MetaversePost on pühendunud täpsele ja erapooletule aruandlusele, kuid turutingimusi võidakse ette teatamata muuta.
Umbes Autor
Damir on ettevõtte meeskonnajuht, tootejuht ja toimetaja Metaverse Post, mis hõlmab selliseid teemasid nagu AI/ML, AGI, LLM-id, Metaverse ja Web3-seotud väljad. Tema artiklid meelitavad igal kuul tohutut vaatajaskonda, üle miljoni kasutaja. Ta näib olevat ekspert, kellel on 10-aastane SEO ja digitaalse turunduse kogemus. Damirit on mainitud ajakirjades Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto ja muud väljaanded. Ta reisib digitaalse nomaadina AÜE, Türgi, Venemaa ja SRÜ vahel. Damir omandas bakalaureusekraadi füüsikas, mis on tema arvates andnud talle kriitilise mõtlemise oskused, mida on vaja pidevalt muutuval Interneti-maastikul edukaks saamiseks.
Veel artikleid
Damir on ettevõtte meeskonnajuht, tootejuht ja toimetaja Metaverse Post, mis hõlmab selliseid teemasid nagu AI/ML, AGI, LLM-id, Metaverse ja Web3-seotud väljad. Tema artiklid meelitavad igal kuul tohutut vaatajaskonda, üle miljoni kasutaja. Ta näib olevat ekspert, kellel on 10-aastane SEO ja digitaalse turunduse kogemus. Damirit on mainitud ajakirjades Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto ja muud väljaanded. Ta reisib digitaalse nomaadina AÜE, Türgi, Venemaa ja SRÜ vahel. Damir omandas bakalaureusekraadi füüsikas, mis on tema arvates andnud talle kriitilise mõtlemise oskused, mida on vaja pidevalt muutuval Interneti-maastikul edukaks saamiseks.






