



Els 30 millors models de transformadors en IA: què són i com funcionen







En els últims mesos, han sorgit nombrosos models de Transformer en IA, cadascun amb noms únics i de vegades divertits. Tanmateix, és possible que aquests noms no proporcionin gaire informació sobre el que realment fan aquests models. Aquest article pretén proporcionar una llista completa i senzilla dels models de Transformer més populars. Classificarà aquests models i també introduirà aspectes i innovacions importants dins de la família Transformer. La llista superior cobrirà models entrenats mitjançant aprenentatges autosupervisats, com BERT o GPT-3, així com models que se sotmeten a una formació addicional amb implicació humana, com l'InstructGPT model utilitzat per ChatGPT.

| Consells Pro |
|---|
| Aquesta guia està dissenyat per proporcionar coneixements complets i habilitats pràctiques en enginyeria ràpida per a aprenents principiants i avançats. |
| Hi ha molts cursos disponible per a persones que vulguin obtenir més informació sobre la IA i les seves tecnologies relacionades. |
| Doneu una ullada a la els 10 millors acceleradors d'IA que s'espera que liderin el mercat en termes de rendiment. |
- Què són els transformadors en IA?
- Què són els codificadors i descodificadors en IA?
- Què són les capes d'atenció a la IA?
- Què són els models afinats en IA?
- Per què els Transformers són el futur de la IA?
- 3 Tipus d'arquitectures de preformació
- 8 Tipus de tasques per a models preformats
- Els 30 millors transformadors en IA
- Preguntes freqüents
Què són els transformadors en IA?
Els transformadors són un tipus de models d'aprenentatge profund que es van introduir en un document de recerca anomenat "L'atenció és tot el que necessiteu” dels investigadors de Google el 2017. Aquest article ha obtingut un immens reconeixement, acumulant més de 38,000 citacions en només cinc anys.
L'arquitectura Transformer original és una forma específica de models codificador-descodificador que havia guanyat popularitat abans de la seva introducció. Aquests models es basaven principalment LSTM i altres variacions de les xarxes neuronals recurrents (RNN), sent l'atenció només un dels mecanismes utilitzats. Tanmateix, el document de Transformer va proposar una idea revolucionària que l'atenció podria servir com a únic mecanisme per establir dependències entre l'entrada i la sortida.
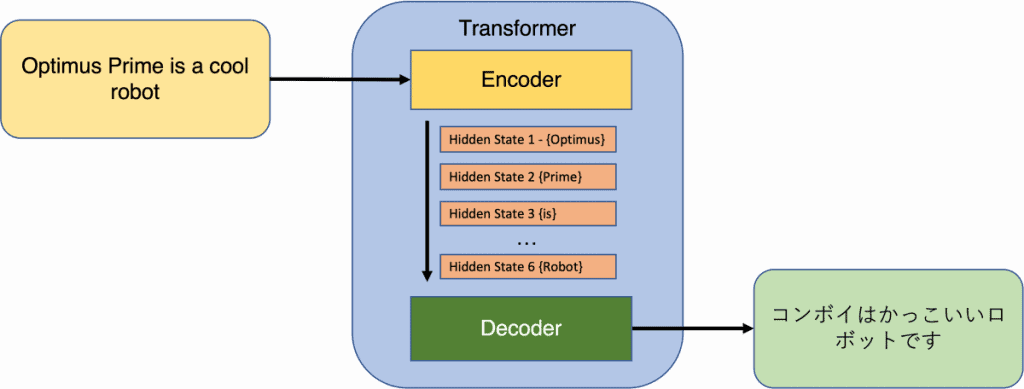
En el context de Transformers, l'entrada consisteix en una seqüència de fitxes, que poden ser paraules o subparaules en el processament del llenguatge natural (PNL). Les subparaules s'utilitzen habitualment en els models de PNL per abordar el problema de les paraules fora del vocabulari. La sortida del codificador produeix una representació de dimensions fixes per a cada testimoni, juntament amb una incrustació independent per a tota la seqüència. El descodificador pren la sortida del codificador i genera una seqüència de fitxes com a sortida.
Des de la publicació del paper Transformer, models populars com BERT i GPT han adoptat aspectes de l'arquitectura original, ja sigui utilitzant el codificador o els components del descodificador. La similitud clau entre aquests models rau en l'arquitectura de capes, que incorpora mecanismes d'autoatenció i capes de feed-forward. A Transformers, cada testimoni d'entrada recorre el seu propi camí a través de les capes mantenint dependències directes amb tots els altres testimonis de la seqüència d'entrada. Aquesta característica única permet un càlcul paral·lel i eficient de representacions de fitxes contextuals, una capacitat no factible amb models seqüencials com els RNN.
Tot i que aquest article només ratlla la superfície de l'arquitectura de Transformer, ofereix una visió dels seus aspectes fonamentals. Per a una comprensió més completa, us recomanem que feu referència al document de recerca original o a la publicació de The Illustrated Transformer.
Què són els codificadors i descodificadors en IA?
Imagineu que teniu dos models, un codificador i un descodificador, treballant junts com un equip. El codificador pren una entrada i la converteix en un vector de longitud fixa. Aleshores, el descodificador agafa aquest vector i el transforma en una seqüència de sortida. Aquests models s'entrenen junts per assegurar-se que la sortida coincideix amb l'entrada el més a prop possible.
Tant el codificador com el descodificador tenien diverses capes. Cada capa del codificador tenia dues subcapes: una capa d'autoatenció multicaps i una xarxa simple d'alimentació. La capa d'autoatenció ajuda a cada testimoni de l'entrada a comprendre les relacions amb tots els altres fitxes. Aquestes subcapes també tenen una connexió residual i una normalització de capes per facilitar el procés d'aprenentatge.
El multicapçal del descodificador capa d'autoatenció funciona una mica diferent de la del codificador. Oculta les fitxes a la dreta del testimoni en el qual s'està centrant. Això assegura que el descodificador només mira les fitxes que hi ha abans del que està intentant predir. Aquesta atenció multicapçal emmascarada ajuda el descodificador a generar prediccions precises. A més, el descodificador inclou una altra subcapa, que és una capa d'atenció multicapçal sobre totes les sortides del codificador.
És important tenir en compte que aquests detalls específics s'han modificat en diferents variacions del model Transformer. Models com BERT i GPT, per exemple, es basen en l'aspecte codificador o descodificador de l'arquitectura original.
Què són les capes d'atenció a la IA?
A l'arquitectura del model que hem comentat anteriorment, les capes d'atenció multicapçal són els elements especials que el fan potent. Però què és exactament l'atenció? Penseu en això com una funció que assigna una pregunta a un conjunt d'informació i dóna una sortida. Cada testimoni de l'entrada té una consulta, una clau i un valor associats. La representació de sortida de cada testimoni es calcula prenent una suma ponderada dels valors, on el pes de cada valor es determina pel grau de concordança amb la consulta.
Els transformadors utilitzen una funció de compatibilitat anomenada producte de punts a escala per calcular aquests pesos. L'interessant de l'atenció a Transformers és que cada testimoni passa pel seu propi camí de càlcul, permetent el càlcul paral·lel de tots els fitxes de la seqüència d'entrada. Simplement són diversos blocs d'atenció que calculen de manera independent representacions per a cada testimoni. A continuació, aquestes representacions es combinen per crear la representació final del testimoni.
En comparació amb altres tipus de xarxes com les recurrents i xarxes convolucionals, les capes d'atenció tenen alguns avantatges. Són computacionalment eficients, és a dir, poden processar informació ràpidament. També tenen una connectivitat més alta, cosa que és útil per capturar relacions a llarg termini en seqüències.
Què són els models afinats en IA?
Models de fundació són models potents que s'entrenen amb una gran quantitat de dades generals. A continuació, es poden adaptar o ajustar per a tasques específiques entrenant-los en un conjunt més petit dades específiques de l'objectiu. Aquest enfocament, popularitzat per la Paper BERT, ha donat lloc al domini dels models basats en Transformer en tasques d'aprenentatge automàtic relacionades amb el llenguatge.
En el cas de models com BERT, produeixen representacions de fitxes d'entrada però no realitzen tasques específiques per si soles. Per fer-los útils, addicionals capes neuronals s'afegeixen a la part superior i el model s'entrena d'extrem a extrem, un procés conegut com a afinació. Tanmateix, amb models generatius M'agrada GPT, l'enfocament és lleugerament diferent. GPT és un model de llenguatge descodificador entrenat per predir la paraula següent d'una frase. Mitjançant la formació en grans quantitats de dades web, GPT pot generar resultats raonables basats en consultes d'entrada o sol·licituds.
Per fer GPT més útil, OpenAI investigadors desenvolupats InstruirGPT, que està entrenat per seguir instruccions humanes. Això s'aconsegueix ajustant GPT utilitzant dades etiquetades amb humans de diferents tasques. InstruirGPT és capaç de realitzar una àmplia gamma de tasques i és utilitzat per motors populars com ChatGPT.
L'ajustament també es pot utilitzar per crear variants de models de fonament optimitzats finalitats específiques més enllà del modelatge lingüístic. Per exemple, hi ha models ajustats per a tasques relacionades amb la semàntica com la classificació de text i la recuperació de cerques. A més, els codificadors de transformadors s'han ajustat amb èxit a la multitasca marcs d'aprenentatge per realitzar múltiples tasques semàntiques utilitzant un únic model compartit.
Avui en dia, l'ajustament s'utilitza per crear versions de models de fonamentació que poden ser utilitzades per un gran nombre d'usuaris. El procés implica generar respostes a l'entrada indicacions i que els humans classifiquen els resultats. Aquest rànquing s'utilitza per entrenar a model de recompensa, que assigna puntuacions a cada sortida. Aprenentatge de reforç amb feedback humà llavors s'utilitza per entrenar encara més el model.
Per què els Transformers són el futur de la IA?
Els transformadors, un tipus de model potent, es van demostrar per primera vegada en el camp de la traducció d'idiomes. Tanmateix, els investigadors es van adonar ràpidament que els Transformers es podrien utilitzar per a diverses tasques relacionades amb l'idioma entrenant-los en una gran quantitat de text sense etiquetar i després ajustant-los en un conjunt més petit de dades etiquetades. Aquest enfocament va permetre a Transformers capturar coneixements significatius sobre el llenguatge.
L'arquitectura Transformer, dissenyada originalment per a tasques de llenguatge, també s'ha aplicat a altres aplicacions com generant imatges, àudio, música i fins i tot accions. Això ha convertit a Transformers en un component clau en l'àmbit de l'IA generativa, que és canviar diversos aspectes de la societat.
La disponibilitat d'eines i marcs com ara PyTorch i TensorFlow ha tingut un paper crucial en l'adopció generalitzada dels models Transformer. Empreses com Huggingface han construït el seu negoci al voltant de la idea de comercialització de biblioteques Transformer de codi obert i maquinari especialitzat com Hopper Tensor Cores de NVIDIA ha accelerat encara més la velocitat d'entrenament i inferència d'aquests models.
Una aplicació notable de Transformers és ChatGPT, un chatbot publicat per OpenAI. Es va fer increïblement popular, arribant a milions d'usuaris en un curt període. OpenAI també ha anunciat el llançament de GPT-4, una versió més potent capaç d'aconseguir un rendiment humà en tasques com ara exàmens mèdics i legals.
L'impacte dels transformadors en el camp de la IA i la seva àmplia gamma d'aplicacions és innegable. Ells tenen va transformar el camí ens apropem a tasques relacionades amb l'idioma i estem obrint el camí per a nous avenços en IA generativa.
3 Tipus d'arquitectures de preformació
L'arquitectura del transformador, que originalment constava d'un codificador i un descodificador, ha evolucionat per incloure diferents variacions en funció de les necessitats específiques. Desglossem aquestes variacions en termes senzills.
- Preentrenament de codificadors: Aquests models se centren en la comprensió de frases o passatges complets. Durant el preentrenament, el codificador s'utilitza per reconstruir fitxes emmascarades a la frase d'entrada. Això ajuda el model a aprendre a entendre el context general. Aquests models són útils per a tasques com la classificació de textos, la implicació i la resposta de preguntes extractives.
- Preentrenament del descodificador: Els models de descodificador s'entrenen per generar el següent testimoni basat en la seqüència anterior de fitxes. Es coneixen com a models de llenguatge autorregressius. Les capes d'autoatenció del descodificador només poden accedir als testimonis abans d'un determinat testimoni de la frase. Aquests models són ideals per a tasques que impliquen la generació de text.
- Transformador (Codificador-Decodificador) Preentrenament: Aquesta variació combina els components del codificador i el descodificador. Les capes d'autoatenció del codificador poden accedir a tots els testimonis d'entrada, mentre que les capes d'autoatenció del descodificador només poden accedir als testimonis abans d'un determinat testimoni. Aquesta arquitectura permet al descodificador utilitzar les representacions apreses pel codificador. Els models de codificador-descodificador són adequats per a tasques com el resum, la traducció o la resposta generativa de preguntes.
Els objectius de la formació prèvia poden implicar un modelatge de llenguatge causal o de soroll. Aquests objectius són més complexos per als models codificador-descodificador en comparació amb els models només codificador o només descodificador. L'arquitectura del transformador té diferents variacions segons l'enfocament del model. Tant si es tracta d'entendre frases completes, generar text o combinar ambdues tasques per a diverses tasques, Transformers ofereix flexibilitat per abordar diferents reptes relacionats amb l'idioma.
8 Tipus de tasques per a models preformats
Quan es forma un model, hem de donar-li una tasca o objectiu per aprendre. Hi ha diverses tasques de processament del llenguatge natural (PNL) que es poden utilitzar per a models de preentrenament. Desglossem algunes d'aquestes tasques en termes senzills:
- Modelat del llenguatge (LM): el model prediu el següent testimoni d'una frase. Aprèn a entendre el context i a generar frases coherents.
- Modelatge del llenguatge causal: el model prediu el següent testimoni en una seqüència de text, seguint un ordre d'esquerra a dreta. És com un model de narració que genera frases una paraula a la vegada.
- Modelat de llenguatge de prefix: el model separa una secció de "prefix" de la seqüència principal. Pot atendre qualsevol testimoni dins del prefix, i després genera la resta de la seqüència de manera autoregressiva.
- Modelatge de llenguatge emmascarat (MLM): alguns testimonis de les frases d'entrada estan emmascarats i el model prediu els testimonis que falten en funció del context circumdant. Aprèn a omplir els buits.
- Modelatge de llenguatge permutat (PLM): el model prediu el següent testimoni basat en una permutació aleatòria de la seqüència d'entrada. Aprèn a manejar diferents ordres de fitxes.
- Autoencoder de reducció de soroll (DAE): el model pren una entrada parcialment corrupta i pretén recuperar l'entrada original sense distorsió. Aprèn a manejar el soroll o les parts que falten del text.
- Detecció de testimonis substituïts (RTD): el model detecta si un testimoni prové del text original o d'una versió generada. Aprèn a identificar fitxes substituïdes o manipulades.
- Predicció de la següent frase (NSP): el model aprèn a distingir si dues frases d'entrada són segments continus de les dades d'entrenament. Comprèn la relació entre frases.
Aquestes tasques ajuden el model a aprendre l'estructura i el significat del llenguatge. Mitjançant la formació prèvia en aquestes tasques, els models aconsegueixen una bona comprensió del llenguatge abans de ser ajustats per a aplicacions específiques.
Els 30 millors transformadors en IA
| Nom | Arquitectura de preformació | Tasca | Sol·licitud | Desenvolupat per |
|---|---|---|---|---|
| ALBERT | codificador | MLM/NSP | Igual que BERT | |
| Paco | descodificador | LM | Tasques de generació i classificació de textos | Stanford |
| AlphaFold | codificador | Predicció de plegament de proteïnes | Plegament de proteïnes | ment profunda |
| Assistent antròpic (vegeu també) | descodificador | LM | Del diàleg general a l'assistent de codi. | Antròpic |
| BART | Codificador/descodificador | AED | Tasques de generació i comprensió de textos | |
| BERT | codificador | MLM/NSP | Comprensió del llenguatge i resposta a preguntes | |
| BlenderBot 3 | descodificador | LM | Tasques de generació i comprensió de textos | |
| BLOOM | descodificador | LM | Tasques de generació i comprensió de textos | Big Science/Huggingface |
| ChatGPT | descodificador | LM | Agents de diàleg | OpenAI |
| xinxilla | descodificador | LM | Tasques de generació i comprensió de textos | ment profunda |
| CLIP | codificador | Classificació imatge/objecte | OpenAI | |
| CTRL | descodificador | Generació de text controlable | Salesforce | |
| LLOSA | descodificador | Predicció de subtítols | Text a imatge | OpenAI |
| DALL-E-2 | Codificador/descodificador | Predicció de subtítols | Text a imatge | OpenAI |
| DeBERTa | descodificador | MLM | Igual que BERT | Microsoft |
| Transformadors de decisions | descodificador | Predicció de la propera acció | RL general (tasques d'aprenentatge de reforç) | Google/UC Berkeley/FAIR |
| DialoGPT | descodificador | LM | Generació de text a la configuració del diàleg | Microsoft |
| DistilBERT | codificador | MLM/NSP | Comprensió del llenguatge i resposta a preguntes | cara abraçada |
| DQ-BART | Codificador/descodificador | AED | Generació i comprensió de textos | Amazon |
| Dolly | descodificador | LM | Tasques de generació i classificació de textos | Databricks, Inc |
| ERNIE | codificador | MLM | Tasques relacionades amb un intensiu coneixement | Diverses institucions xineses |
| Flamenc | descodificador | Predicció de subtítols | Text a imatge | ment profunda |
| Galactica | descodificador | LM | QA científic, raonament matemàtic, resum, generació de documents, predicció de propietats moleculars i extracció d'entitats. | meta |
| PROGRAMA | codificador | Predicció de subtítols | Text a imatge | OpenAI |
| GPT-3.5 | descodificador | LM | Diàleg i llenguatge general | OpenAI |
| GPTInstruir | descodificador | LM | Tasques de diàleg o llenguatge intensius en coneixements | OpenAI |
| HTML | Codificador/descodificador | AED | Model de llenguatge que permet una indicació HTML estructurada | |
| Imatge | T5 | Predicció de subtítols | Text a imatge | |
| LAMDA | descodificador | LM | Modelatge general del llenguatge | |
| LLaMA | descodificador | LM | Raonament en sentit comú, resposta a preguntes, generació de codi i comprensió lectora. | meta |
| Minerva | descodificador | LM | Raonament matemàtic | |
| Palm | descodificador | LM | Comprensió i generació del llenguatge | |
| ROBERTa | codificador | MLM | Comprensió del llenguatge i resposta a preguntes | UW/Google |
| Pardal | descodificador | LM | Agents de diàleg i aplicacions generals de generació de llenguatge com Q&A | ment profunda |
| Difusió estable | Codificador/descodificador | Predicció de subtítols | Text a imatge | LMU Munich + Stability.ai + Eleuther.ai |
| Vicunya | descodificador | LM | Agents de diàleg | UC Berkeley, CMU, Stanford, UC San Diego i MBZUAI |
Preguntes freqüents
Els transformadors en IA són un tipus de arquitectura d'aprenentatge profund que ha canviat el processament del llenguatge natural i altres tasques. Utilitzen mecanismes d'autoatenció per capturar les relacions entre paraules en una frase, cosa que els permet entendre i generar text semblant a l'ésser humà.
Els codificadors i descodificadors són components que s'utilitzen habitualment en models de seqüència a seqüència. Els codificadors processen les dades d'entrada, com ara text o imatges, i les converteixen en una representació comprimida, mentre que els descodificadors generen dades de sortida basades en la representació codificada, permetent tasques com la traducció d'idiomes o els subtítols d'imatges.
Les capes d'atenció són components utilitzats xarxes neuronals, especialment en models de transformadors. Permeten al model centrar-se selectivament en diferents parts de la seqüència d'entrada, assignant pesos a cada element en funció de la seva rellevància, permetent capturar dependències i relacions entre elements de manera eficaç.
Els models afinats es refereixen a models prèviament entrenats que han estat entrenats més en una tasca o conjunt de dades específics per millorar-ne el rendiment i adaptar-los als requisits específics d'aquesta tasca. Aquest procés d'ajustament consisteix en ajustar els paràmetres del model per optimitzar les seves prediccions i fer-lo més especialitzat per a la tasca objectiu.
Els transformadors es consideren el futur de la IA perquè han demostrat un rendiment excepcional en una àmplia gamma de tasques, com ara el processament del llenguatge natural, la generació d'imatges i molt més. La seva capacitat per capturar dependències a llarg abast i processar dades seqüencials de manera eficient els fa altament adaptables i efectius per a diverses aplicacions, obrint el camí per als avenços en IA generativa i revolucionant molts aspectes de la societat.
Els models de transformadors més famosos de la IA inclouen BERT (Representacions de codificadors bidireccionals de transformadors), GPT (Transformador generatiu pre-entrenat) i T5 (Transformador de transferència de text a text). Aquests models han aconseguit resultats notables en diverses tasques de processament del llenguatge natural i han guanyat una popularitat important a la comunitat de recerca d'IA.
Llegeix més sobre AI:
renúncia
En línia amb la Directrius del projecte Trust, si us plau, tingueu en compte que la informació proporcionada en aquesta pàgina no pretén ni s'ha d'interpretar com a assessorament legal, fiscal, d'inversió, financer o de cap altra forma. És important invertir només el que et pots permetre perdre i buscar assessorament financer independent si tens dubtes. Per obtenir més informació, us suggerim que feu referència als termes i condicions, així com a les pàgines d'ajuda i assistència proporcionades per l'emissor o l'anunciant. MetaversePost es compromet a fer informes precisos i imparcials, però les condicions del mercat estan subjectes a canvis sense previ avís.
About The Autor
Damir és el líder d'equip, cap de producte i editor de Metaverse Post, que cobreix temes com AI/ML, AGI, LLMs, Metaverse i Web3-camps relacionats. Els seus articles atrauen una audiència massiva de més d'un milió d'usuaris cada mes. Sembla ser un expert amb 10 anys d'experiència en SEO i màrqueting digital. Damir ha estat esmentat a Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto i altres publicacions. Viatja entre els Emirats Àrabs Units, Turquia, Rússia i la CEI com a nòmada digital. Damir va obtenir una llicenciatura en física, que creu que li ha donat les habilitats de pensament crític necessàries per tenir èxit en el paisatge en constant canvi d'Internet.
més articles
Damir és el líder d'equip, cap de producte i editor de Metaverse Post, que cobreix temes com AI/ML, AGI, LLMs, Metaverse i Web3-camps relacionats. Els seus articles atrauen una audiència massiva de més d'un milió d'usuaris cada mes. Sembla ser un expert amb 10 anys d'experiència en SEO i màrqueting digital. Damir ha estat esmentat a Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto i altres publicacions. Viatja entre els Emirats Àrabs Units, Turquia, Rússia i la CEI com a nòmada digital. Damir va obtenir una llicenciatura en física, que creu que li ha donat les habilitats de pensament crític necessàries per tenir èxit en el paisatge en constant canvi d'Internet.






