



GLIGEN: nou model de generació de text a imatge congelat amb quadre delimitador







En breu
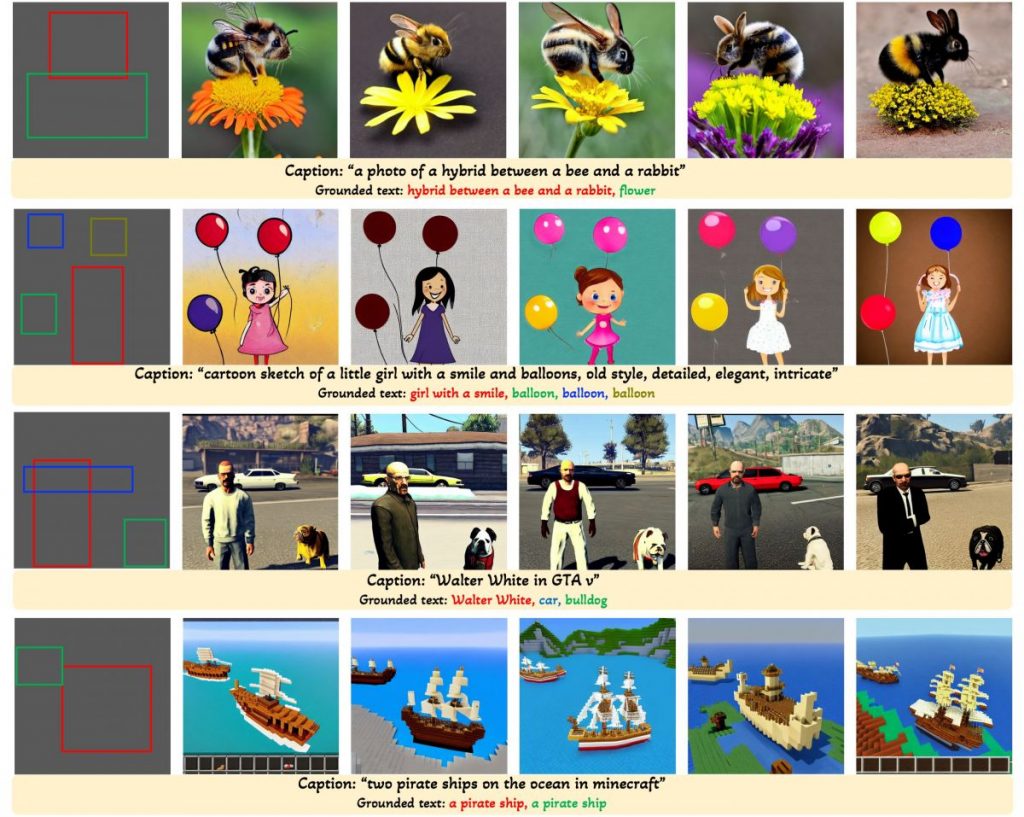
GLIGEN, o Grounded-Language-to-Image Generation, és una tècnica nova que es basa i amplia la capacitat dels models de difusió actuals prèviament entrenats.
Amb les entrades de condició de subtítols i quadres delimitadors, el model GLIGEN genera text2img de món obert.
GLIGEN pot generar una varietat d'objectes en llocs i estils específics aprofitant el coneixement d'un model text2img preentrenat.
GLIGEN també pot fonamentar punts clau humans mentre genera text a imatges.
Els models de difusió de text a imatge a gran escala han recorregut un llarg camí. Tanmateix, la pràctica actual és confiar únicament en l'entrada de text, cosa que pot limitar la controlabilitat. GLIGEN, o Grounded-Language-to-Image Generation, és una tècnica novedosa que es basa i amplia la capacitat dels models de difusió de text a imatge pre-entrenats actuals, permetent que estiguin condicionats a les entrades de connexió a terra.

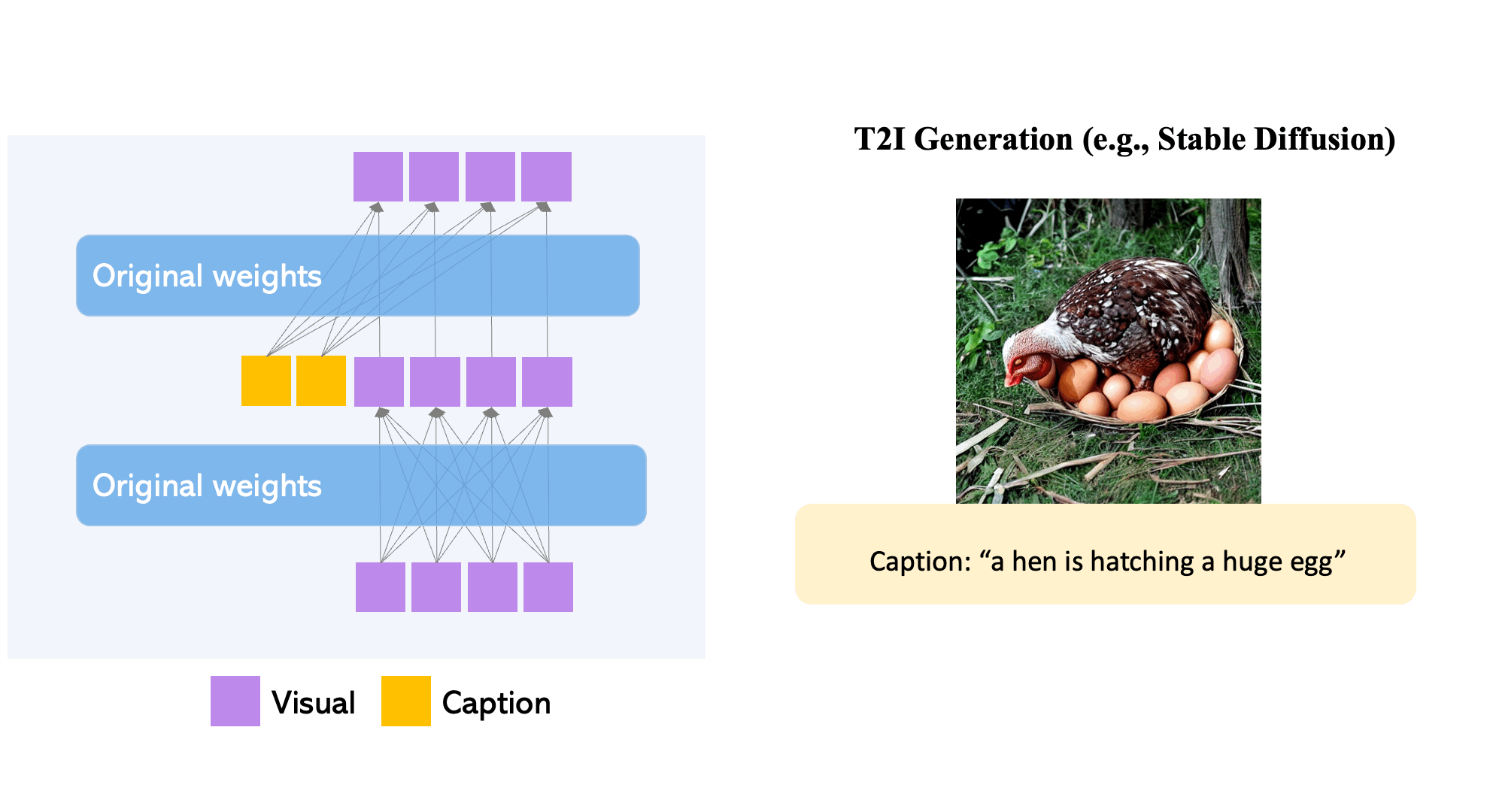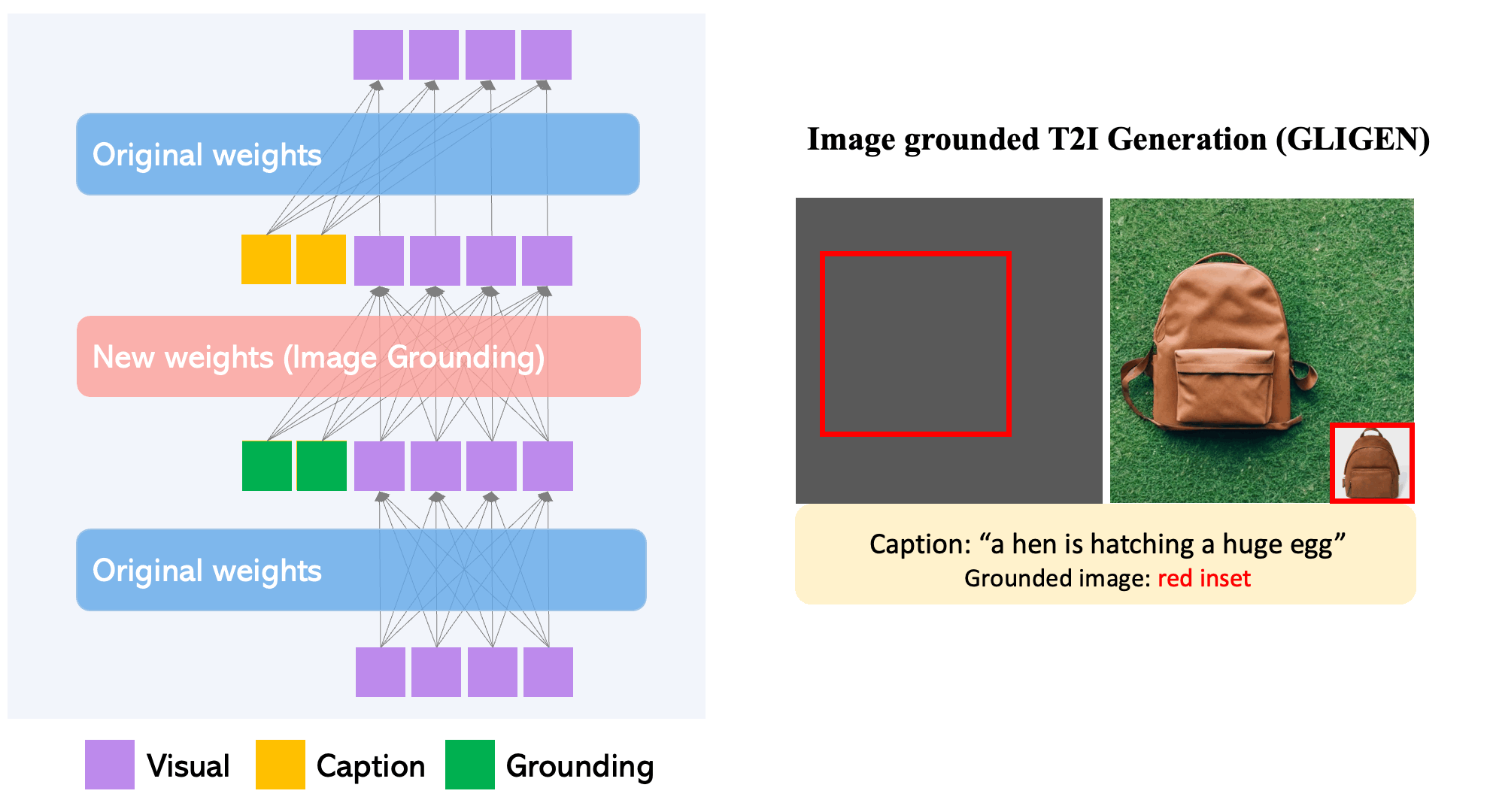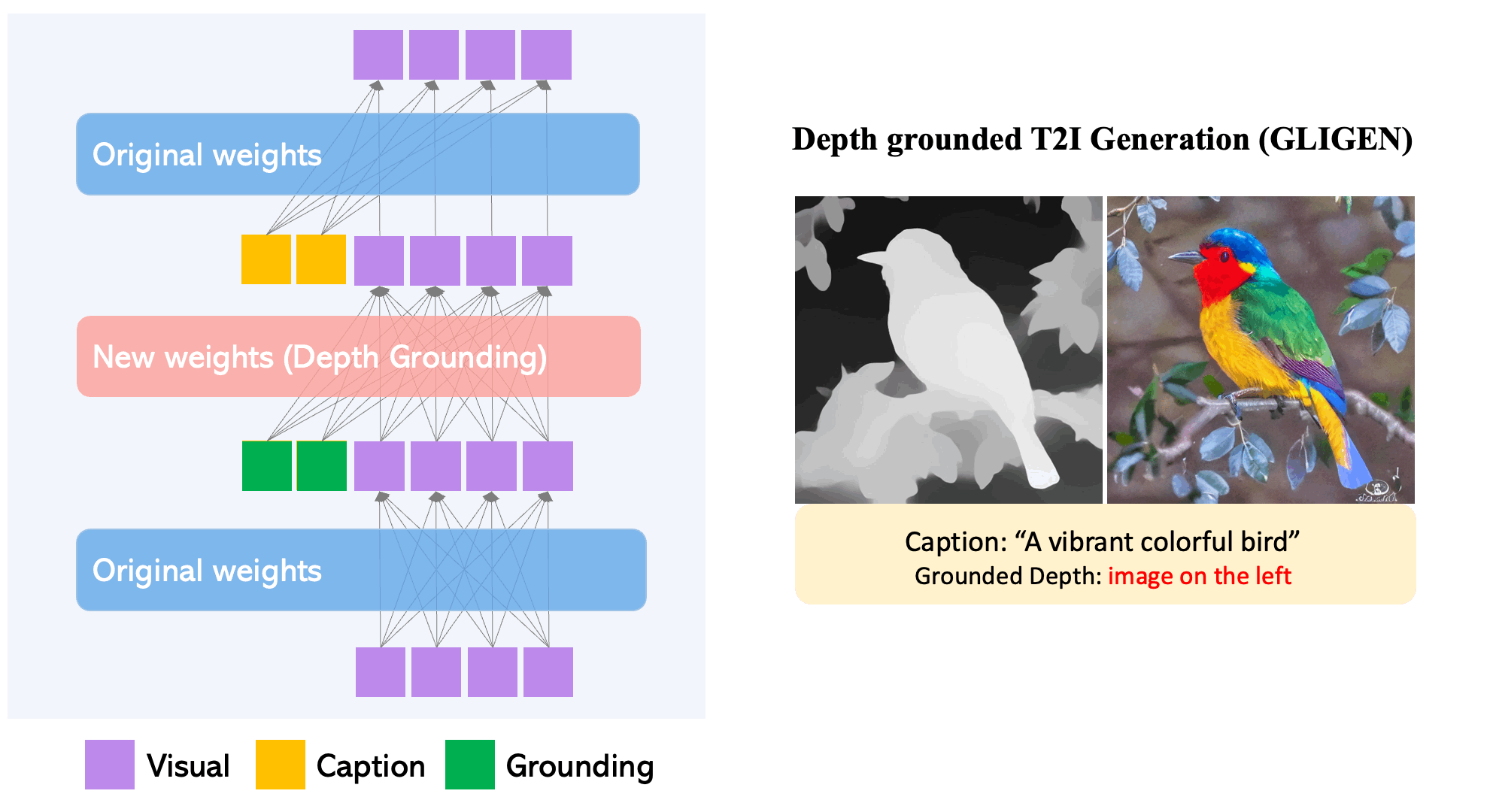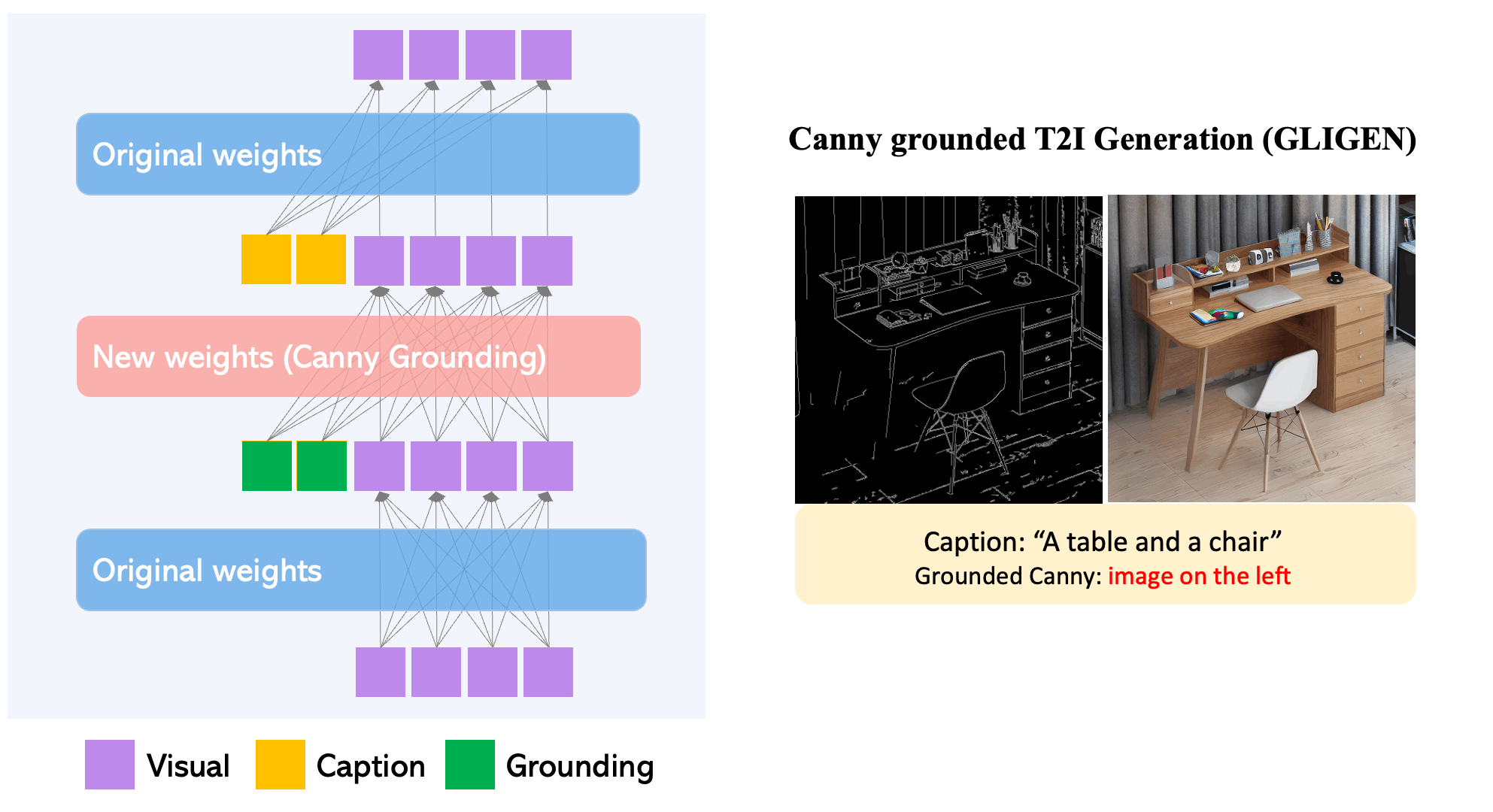
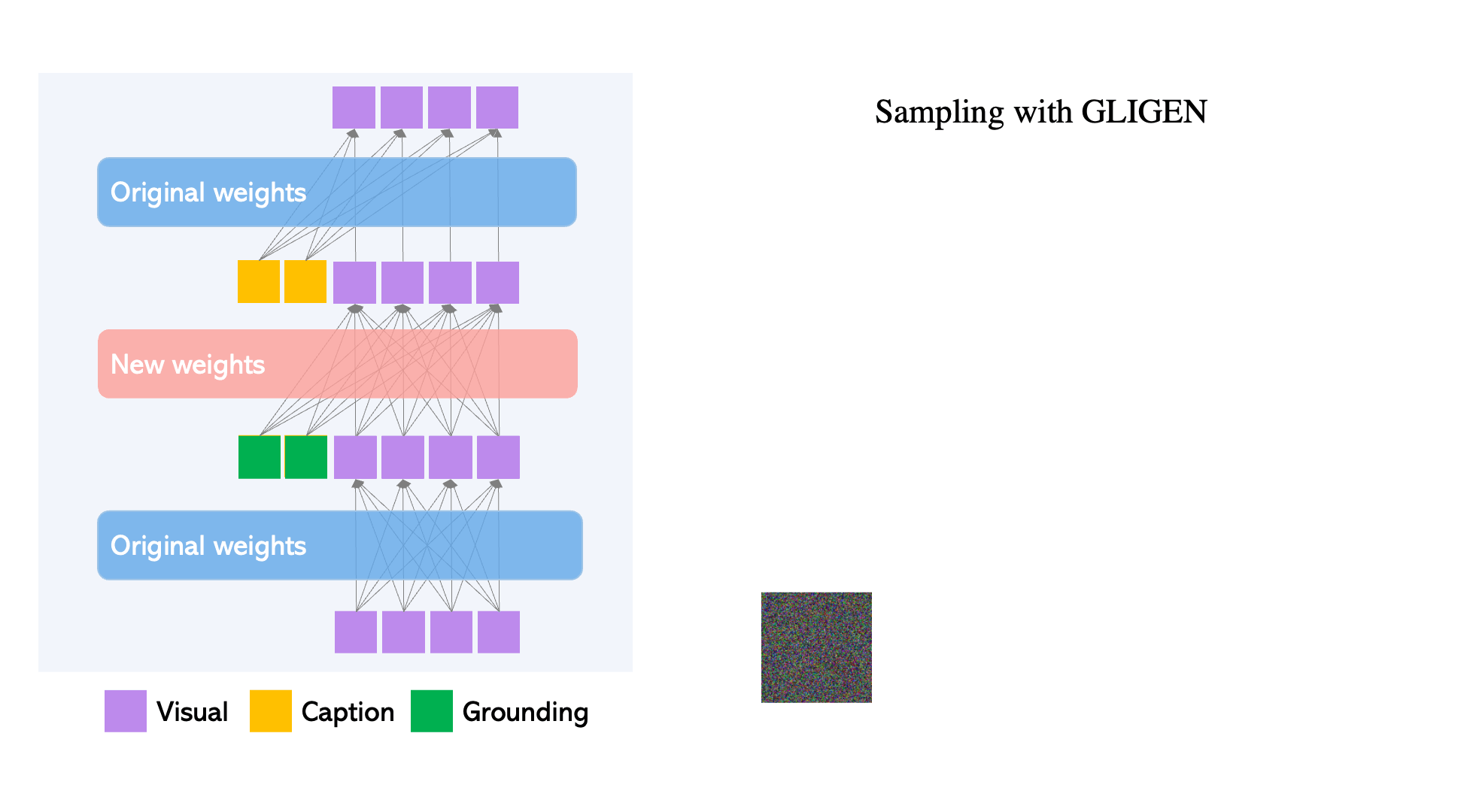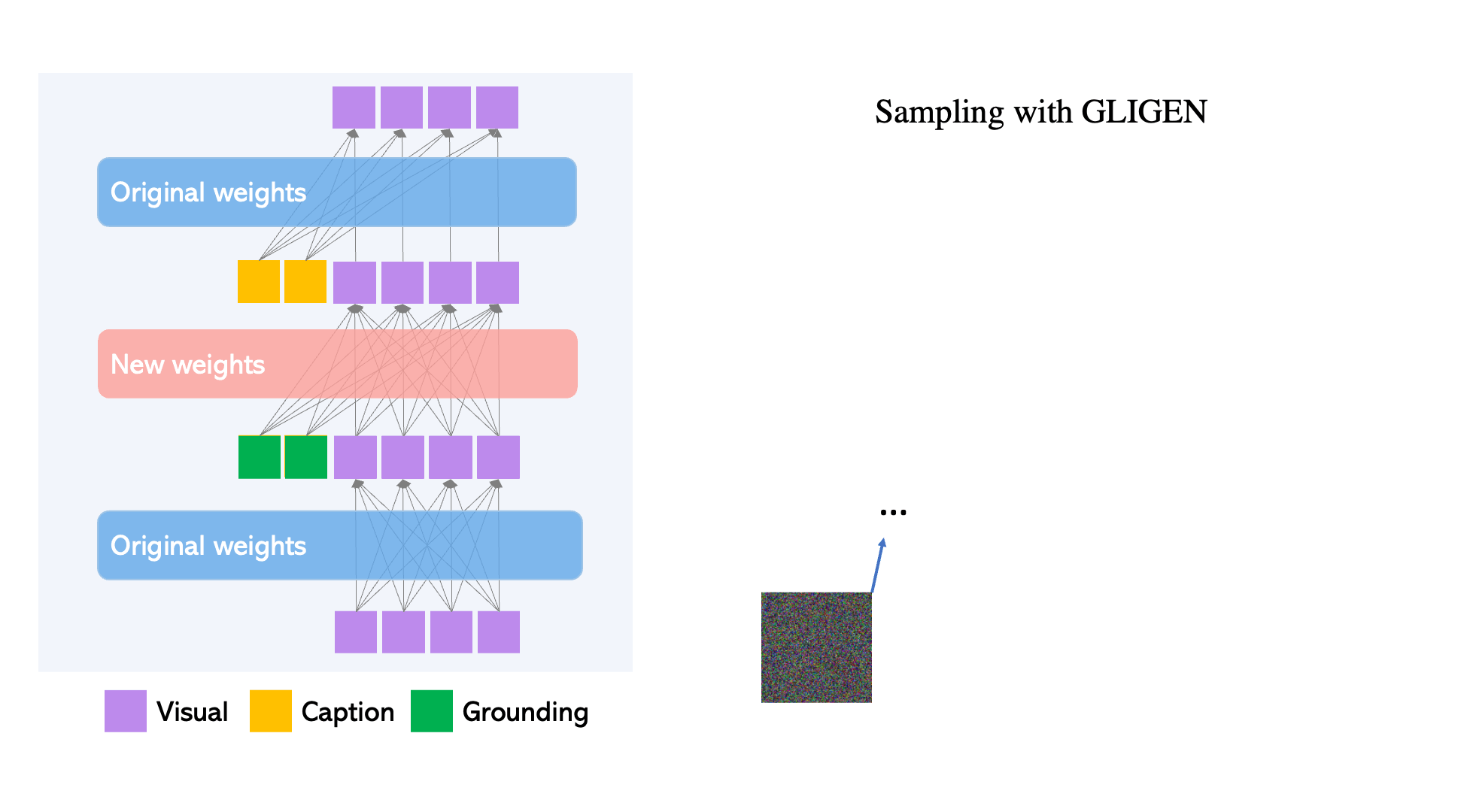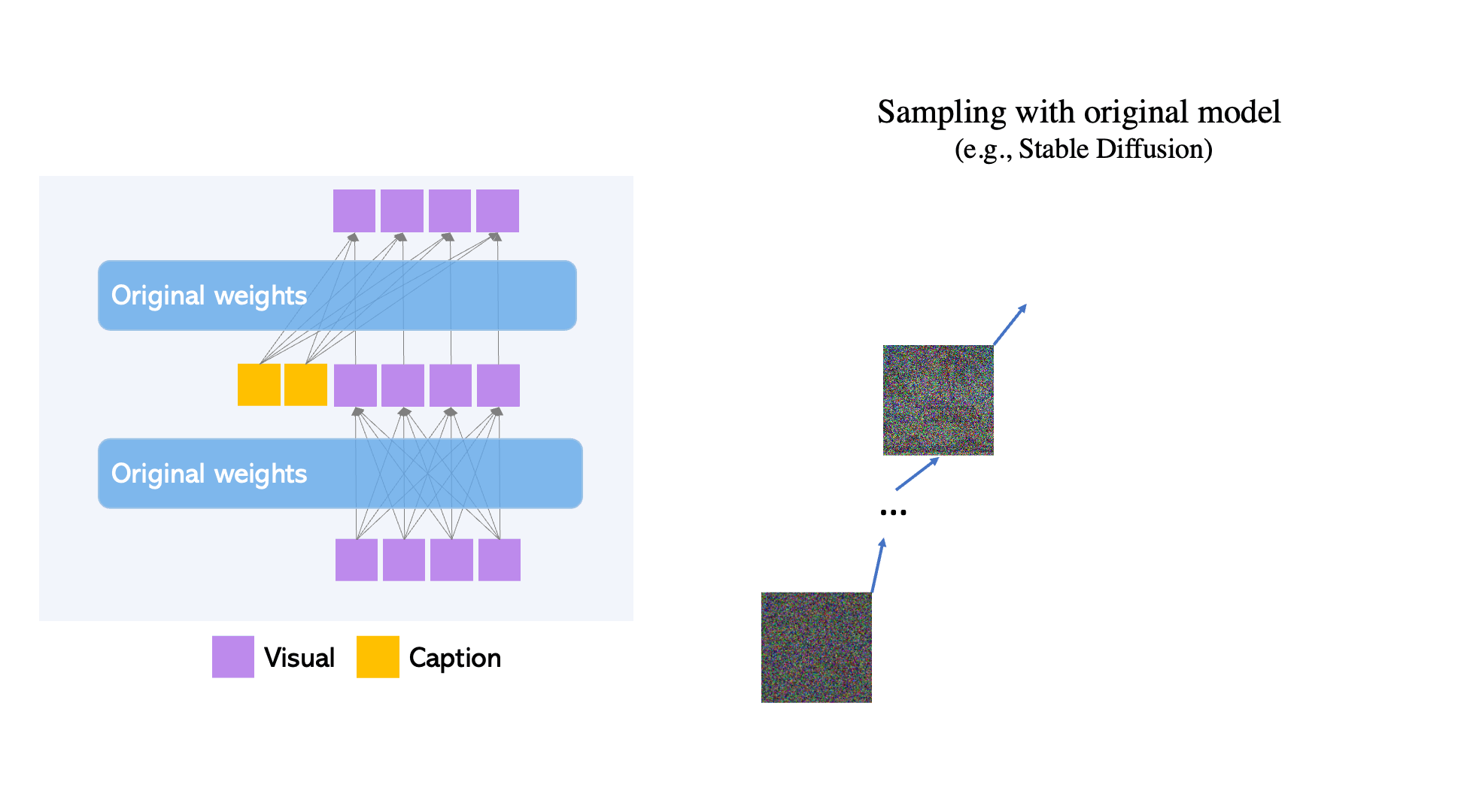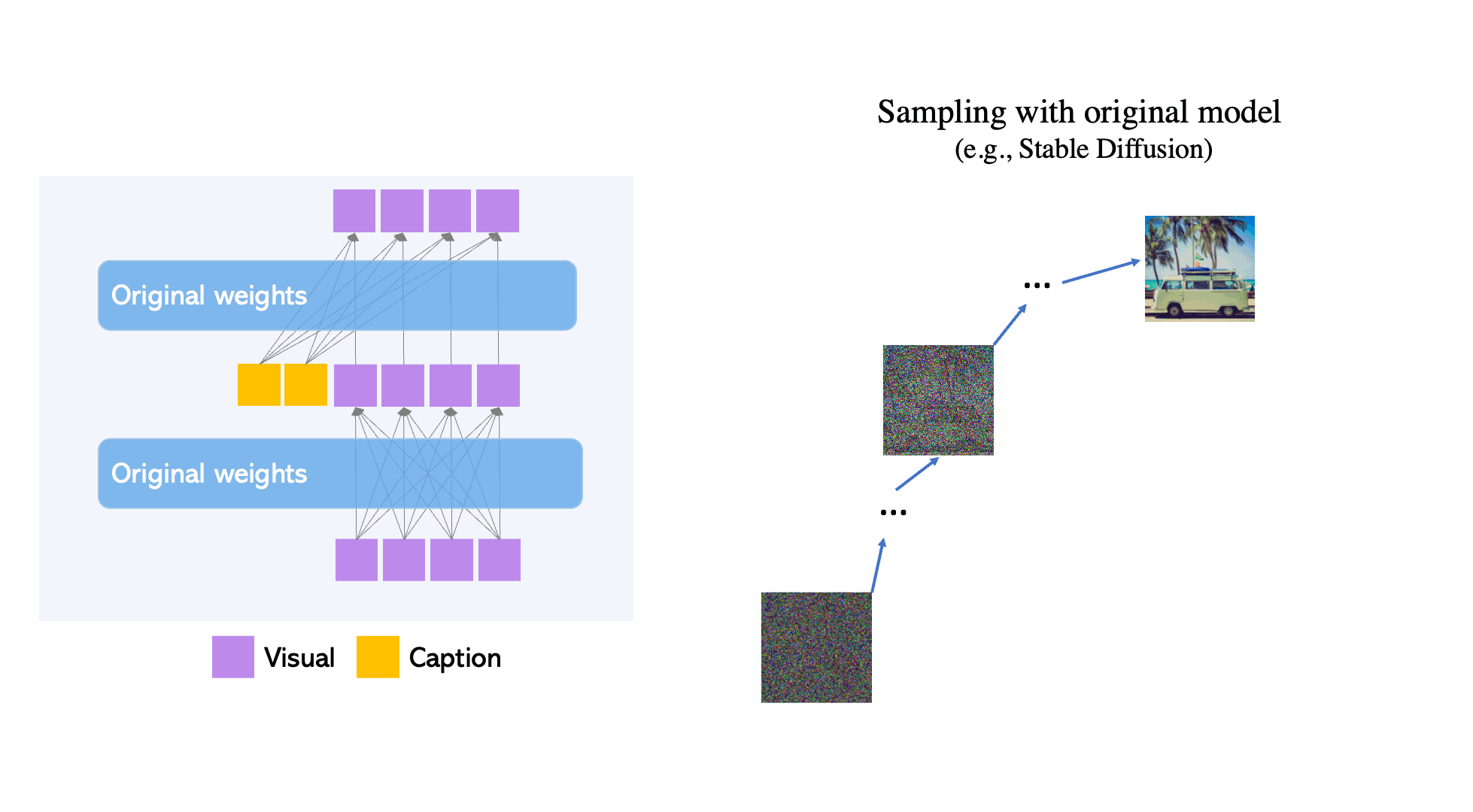
Per mantenir l'extens coneixement del concepte del model pre-entrenat, els desenvolupadors congelen tots els seus pesos i bombegen la informació de connexió a terra en capes entrenables noves mitjançant un procés controlat. Amb les entrades de condició de subtítols i quadres delimitadors, el model GLIGEN genera text-a-imatge basat en el món obert i la capacitat de connexió a terra es generalitza eficaçment a noves configuracions i conceptes espacials.
Fes una ullada a la Demo aquí.

- GLIGEN es basa en la formació prèvia existent models de difusió, els pesos originals dels quals s'han congelat per retenir grans quantitats de coneixements pre-entrenats.
- A cada bloc de transformadors, es crea una nova capa d'autoatenció amb gated entrenable per absorbir l'entrada de terra addicional.
- Cada testimoni de connexió a terra té dos tipus d'informació: informació semàntica sobre la cosa a terra (text codificat o imatge) i informació de posició espacial (quadre delimitador codificat o punts clau).
| Article relacionat: VToonify: un model d'IA en temps real per generar vídeos de retrats artístics |
| Article relacionat: Microsoft ha llançat un model de difusió que pot crear un avatar 3D a partir d'una sola foto d'una persona |



Llegeix més sobre AI:
renúncia
En línia amb la Directrius del projecte Trust, si us plau, tingueu en compte que la informació proporcionada en aquesta pàgina no pretén ni s'ha d'interpretar com a assessorament legal, fiscal, d'inversió, financer o de cap altra forma. És important invertir només el que et pots permetre perdre i buscar assessorament financer independent si tens dubtes. Per obtenir més informació, us suggerim que feu referència als termes i condicions, així com a les pàgines d'ajuda i assistència proporcionades per l'emissor o l'anunciant. MetaversePost es compromet a fer informes precisos i imparcials, però les condicions del mercat estan subjectes a canvis sense previ avís.
About The Autor
Damir és el líder d'equip, cap de producte i editor de Metaverse Post, que cobreix temes com AI/ML, AGI, LLMs, Metaverse i Web3-camps relacionats. Els seus articles atrauen una audiència massiva de més d'un milió d'usuaris cada mes. Sembla ser un expert amb 10 anys d'experiència en SEO i màrqueting digital. Damir ha estat esmentat a Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto i altres publicacions. Viatja entre els Emirats Àrabs Units, Turquia, Rússia i la CEI com a nòmada digital. Damir va obtenir una llicenciatura en física, que creu que li ha donat les habilitats de pensament crític necessàries per tenir èxit en el paisatge en constant canvi d'Internet.
més articles
Damir és el líder d'equip, cap de producte i editor de Metaverse Post, que cobreix temes com AI/ML, AGI, LLMs, Metaverse i Web3-camps relacionats. Els seus articles atrauen una audiència massiva de més d'un milió d'usuaris cada mes. Sembla ser un expert amb 10 anys d'experiència en SEO i màrqueting digital. Damir ha estat esmentat a Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto i altres publicacions. Viatja entre els Emirats Àrabs Units, Turquia, Rússia i la CEI com a nòmada digital. Damir va obtenir una llicenciatura en física, que creu que li ha donat les habilitats de pensament crític necessàries per tenir èxit en el paisatge en constant canvi d'Internet.






