



Programes de LLM: el nou camí per ajustar els models neuronals en situacions complexes







En breu
Els autors proposen un camí alternatiu anomenat LLM Programs, que es pot considerar com el desenvolupament de l'aprenentatge en context.
La clau per resoldre un problema mitjançant el programa LLM és la capacitat de descompondre la solució d'un problema en una seqüència de passos més senzills.
Hi ha dues àrees principals de personalització de LLM: afinar (o formació addicional) el model base pre-entrenat i aprenentatge en context. L'afinació requereix recursos informàtics importants, recollida de dades i infraestructura per fer-ho i després allotjar models ajustats. Mentrestant, l'aprenentatge en context implica compilar la indicació adequada amb exemples de resolució del problema, com ara la cadena de pensament (CoT). No obstant això, hi ha algunes dificultats, com ara la mida limitada del text que es pot enviar al model i el fet que en un missatge de pas múltiples complexos, els passos poden interferir entre ells i el model es pot distreure amb alguna cosa. això no s'ha de distreure en aquest moment. Els autors proposen un camí alternatiu anomenat Programes de LLM, que es pot considerar com el desenvolupament de l'aprenentatge en context.

| Recomanat: Prompt Engineering Ultimate Guide 2023 |
LLM està integrat al programa (de manera convencional llenguatge de programació, per exemple, a Python). Aquest codi extern s'encarrega d'emmagatzemar l'estat i mantenir el model pas a pas. Té alguns avantatges importants: els llenguatges de programació estan adaptats per a això, la mida del context disponible creix i els passos no s'interfereixen entre ells. La clau per resoldre un problema mitjançant el programa LLM és la capacitat de descompondre la solució d'un problema en una seqüència de passos més senzills. Aquest enfocament es diferencia dels treballs anteriors, on el model utilitzava eines externes com calculadores o intèrprets de codi per mantenir l'estat. Aquest enfocament és bo perquè és possible descriure una tasca complexa i extensiva d'aquesta manera, facilitant la prova, la depuració i l'avaluació de la qualitat.
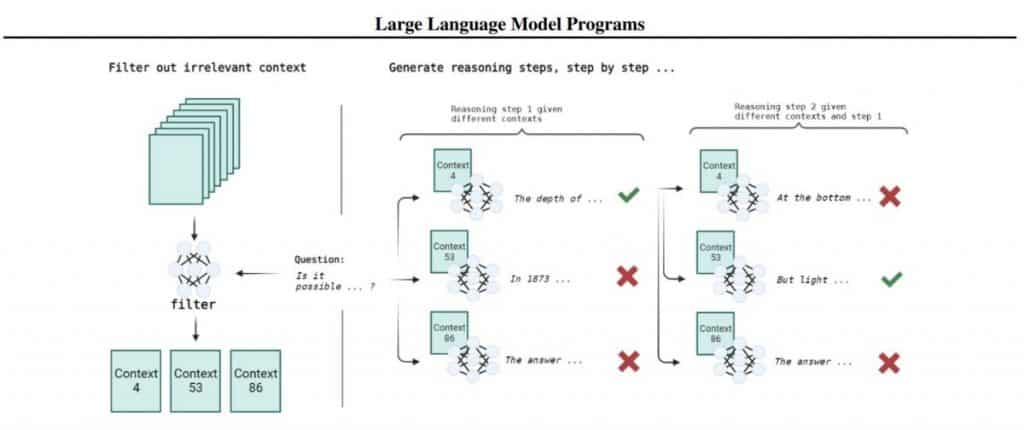
A més, no hi ha interferències entre els passos, cosa que facilita el treball amb LLM. Els sistemes de preguntes-respostes tampoc són nous; han existit molt abans dels LLM. Com es resol ara la tasca de respondre preguntes?
Els llocs s'actualitzen amb freqüència, per tant a model congelat no és una opció; ràpidament quedarà obsolet i no podrà respondre preguntes sobre nous productes. El reciclatge constant del model per a cada actualització no és una opció realista: és car i requereix molt de temps. En canvi, les pàgines d'un lloc web normalment s'indexen, es posen en algun tipus de base de dades i sovint es vectoritzen. A petició de l'usuari, els documents rellevants s'obtenen i s'envien com a context a LLM.
En aquest paradigma, el problema es resol de manera natural mitjançant el programa LLM. Com a avantatge, això es fa possible per implementar una lògica multipass més complexa que no encaixaria completament en el context.
Provat al Conjunt de dades StrategyQA que conté problemes de classificació binària, la solució dels quals implica un raonament multidireccional. Com "La llum del sol penetra al lloc més profund del mar Negre?". Per respondre, cal trobar la profunditat màxima (2 km) i fins a quina profunditat penetra la llum a l'aigua (1 km) i després treure una conclusió. Fem una ullada a una altra pregunta d'exemple: "Aristòtil va utilitzar un ordinador portàtil?" Aquesta pregunta no és tan senzilla i no segueix explícitament la seqüència de passos de raonament com "Va Aristòtil viu quan es va inventar l'ordinador portàtil?" fa. El conjunt de dades se centra en preguntes on aquesta seqüència està implícita. Només hi ha 2,780 preguntes al conjunt de dades, de les quals només 918 tenen paràgrafs amb evidències que reforcen tots els passos del raonament. En el treball actual, es limita a aquest subconjunt; en cas contrari, hauríem de confiar en que LLM aprengui alguns fets durant la formació prèvia.
L'OPT-175B LLM, per defecte, no és molt bo per seguir instruccions; no havia d'ajustar les instruccions ni les dades de conversa. Per resoldre el problema de resposta a preguntes recolzats per evidències, es divideix en una etapa de filtratge de dades i una etapa de cerca en arbre.
En l'etapa de filtratge, tenint una pregunta, els desenvolupadors passen per tots els paràgrafs i seleccionen els més rellevants. Per exemple, amb una indicació d'uns quants cops, demaneu al LLM que respongui (sí/no) si un paràgraf determinat és rellevant per a la pregunta formulada. Es va provar en un subconjunt de 300 StrategyQA, on cada pregunta es va relacionar amb un paràgraf, rellevant o no, 50/50. OPT-175B i text-davinci-002 no tenen a qualitat molt superior que una línia de base aleatòria: fins al 56%. El més avançat 11B Tk-Instruct no és molt millor amb un 61.6%.
A causa de la mala qualitat d'aquest enfocament, es va crear una alternativa que considera la probabilitat logarítmica negativa (NLL) mitjana de la pregunta en combinació amb el paràgraf de text anterior i després classifica els resultats. Avaluat en un conjunt de dades on per a cada pregunta hi havia 100 paràgrafs i només un era rellevant (per tant, les endevinades aleatòries donen un 1%). Tenim una precisió del primer 1 al 79% i del 5 al 93%. Per a aquest càlcul, normalment necessiteu accedir al model en si, que no sempre es fa a l'API.
A continuació ve l'etapa de construcció de cadenes de producció. Això es fa mitjançant una cerca a través d'un arbre on la pregunta és l'arrel, i a cada nivell, hi ha molts paràgrafs amb possibles evidències utilitzades com a context per generar el següent pas. Cada camí a través de l'arbre és una cadena de sortida potencial. No és realista treure una conclusió sobre totes les cadenes possibles, de manera que es classifiquen totes les cadenes disponibles i s'amplia la cadena de més alt rang. Aquesta és una variació de la cerca de feix. El procés s'atura quan es fa una resposta o s'ha passat el nombre màxim de passos permès.
Els detalls més importants són les dues estratègies de classificació provades per al pas de cerca d'arbres. La primera estratègia es basa en el NLL mitjà de tota la cadena, mentre que la segona estratègia mira la diferència mitjana en NLL amb i sense paràgraf (P), amb i sense pregunta (Q). A les 918 preguntes disponibles de StrategyQA, aquest enfocament millora significativament la qualitat de la resposta en relació amb la línia de base amb CoT (60%); ambdues opcions de cerca donen al voltant del 66% (l'estratègia amb un delta lleugerament superior). Si s'envien fets d'or, la qualitat es torna al voltant del 81%, que és el límit superior per a OPT. Darklang sembla anar-hi a algun lloc, però d'una manera una mica diferent.
L'article està basat en Telegram enviar.
Llegeix més sobre AI:
renúncia
En línia amb la Directrius del projecte Trust, si us plau, tingueu en compte que la informació proporcionada en aquesta pàgina no pretén ni s'ha d'interpretar com a assessorament legal, fiscal, d'inversió, financer o de cap altra forma. És important invertir només el que et pots permetre perdre i buscar assessorament financer independent si tens dubtes. Per obtenir més informació, us suggerim que feu referència als termes i condicions, així com a les pàgines d'ajuda i assistència proporcionades per l'emissor o l'anunciant. MetaversePost es compromet a fer informes precisos i imparcials, però les condicions del mercat estan subjectes a canvis sense previ avís.
About The Autor
Damir és el líder d'equip, cap de producte i editor de Metaverse Post, que cobreix temes com AI/ML, AGI, LLMs, Metaverse i Web3-camps relacionats. Els seus articles atrauen una audiència massiva de més d'un milió d'usuaris cada mes. Sembla ser un expert amb 10 anys d'experiència en SEO i màrqueting digital. Damir ha estat esmentat a Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto i altres publicacions. Viatja entre els Emirats Àrabs Units, Turquia, Rússia i la CEI com a nòmada digital. Damir va obtenir una llicenciatura en física, que creu que li ha donat les habilitats de pensament crític necessàries per tenir èxit en el paisatge en constant canvi d'Internet.
més articles
Damir és el líder d'equip, cap de producte i editor de Metaverse Post, que cobreix temes com AI/ML, AGI, LLMs, Metaverse i Web3-camps relacionats. Els seus articles atrauen una audiència massiva de més d'un milió d'usuaris cada mes. Sembla ser un expert amb 10 anys d'experiència en SEO i màrqueting digital. Damir ha estat esmentat a Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto i altres publicacions. Viatja entre els Emirats Àrabs Units, Turquia, Rússia i la CEI com a nòmada digital. Damir va obtenir una llicenciatura en física, que creu que li ha donat les habilitats de pensament crític necessàries per tenir èxit en el paisatge en constant canvi d'Internet.






