



VALL-E:微软新的零镜头文本转语音模型可以在三秒内复制每个人的声音






简单来说
只需任何语音的三秒样本,基于 Transformer 的 TTS 模型 VALL-E 可以产生各种声音的语音.
这是在听起来更自然的 TTS 系统方向上的重大进步。
然而,Microsoft 提供了一些正在使用的模型示例,很明显,这代表了 TTS 技术的重大发展。
自第一个文本转语音 (TTS) 模型发布以来,研究人员一直在寻找改进这些系统生成语音方式的方法。 微软最新型号, 瓦力, 是在这方面向前迈出的重要一步。
VALL-E 是一种基于变压器的 TTS 模型,它可以在仅听到该语音的三秒样本后生成任何语音的语音。 这是对以前模型的重大改进,以前的模型需要更长的训练时间才能生成新的声音。

此外,语音的语调、魅力和风格在生成的语音中都保持完好无损。 这是使 TTS 系统听起来更自然的重要一步。
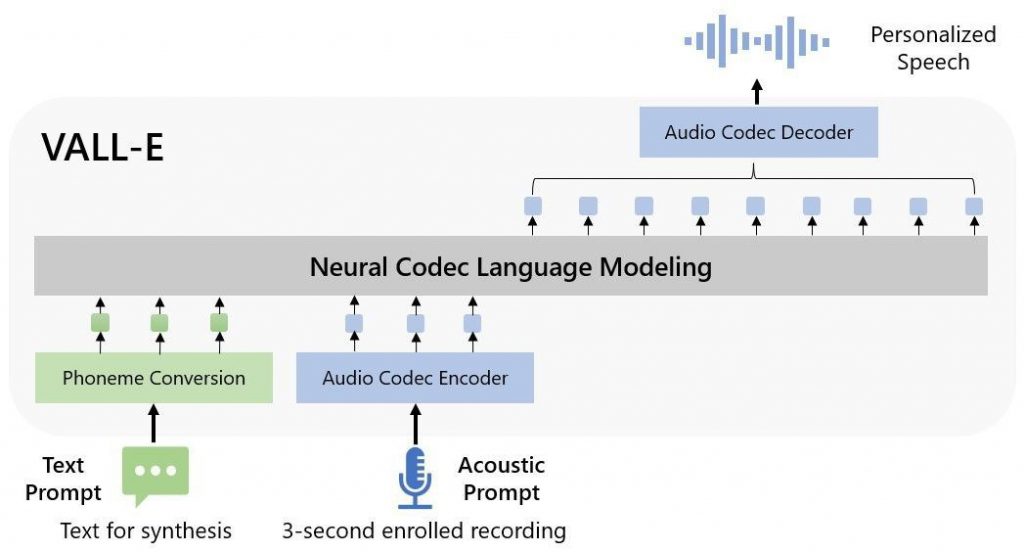
该模型基于变形金刚并具有 Dale-1 外观。 不要与基于扩散的 Dalle-2 相混淆。 代码仍然缺乏。 用户对他们是否会发布它持怀疑态度。
不过,Microsoft 已经发布了几个实际模型示例,很明显这是 TTS 技术的重大进步。
例#1:
示例#2:
例#3:
阅读有关人工智能的更多信息:
免责声明
在与行 信托项目指南,请注意,本页提供的信息无意且不应被解释为法律、税务、投资、财务或任何其他形式的建议。 重要的是,仅投资您可以承受损失的金额,并在有任何疑问时寻求独立的财务建议。 如需了解更多信息,我们建议您参阅条款和条件以及发行人或广告商提供的帮助和支持页面。 MetaversePost 致力于提供准确、公正的报告,但市场状况如有变更,恕不另行通知。
关于作者
Damir 是团队领导、产品经理和编辑 Metaverse Post,涵盖 AI/ML、AGI、LLM、Metaverse 等主题 Web3- 相关领域。 他的文章每月吸引超过一百万用户的大量读者。 他似乎是一位在 SEO 和数字营销方面拥有 10 年经验的专家。 达米尔曾在 Mashable、Wired、 Cointelegraph、《纽约客》、Inside.com、Entrepreneur、BeInCrypto 和其他出版物。 他作为数字游牧者往返于阿联酋、土耳其、俄罗斯和独联体国家之间。 达米尔获得了物理学学士学位,他认为这赋予了他在不断变化的互联网格局中取得成功所需的批判性思维技能。
更多文章
Damir 是团队领导、产品经理和编辑 Metaverse Post,涵盖 AI/ML、AGI、LLM、Metaverse 等主题 Web3- 相关领域。 他的文章每月吸引超过一百万用户的大量读者。 他似乎是一位在 SEO 和数字营销方面拥有 10 年经验的专家。 达米尔曾在 Mashable、Wired、 Cointelegraph、《纽约客》、Inside.com、Entrepreneur、BeInCrypto 和其他出版物。 他作为数字游牧者往返于阿联酋、土耳其、俄罗斯和独联体国家之间。 达米尔获得了物理学学士学位,他认为这赋予了他在不断变化的互联网格局中取得成功所需的批判性思维技能。






