



30+ populārākie AI transformatoru modeļi: kas tie ir un kā tie darbojas







Pēdējos mēnešos mākslīgajā intelektā ir parādījušies daudzi transformatoru modeļi, katram no kuriem ir unikāli un dažreiz uzjautrinoši nosaukumi. Tomēr šie nosaukumi, iespējams, nesniedz lielu ieskatu par to, ko šie modeļi faktiski dara. Šī raksta mērķis ir sniegt visaptverošu un vienkāršu sarakstu ar populārākajiem transformatoru modeļiem. Tas klasificēs šos modeļus, kā arī ieviesīs svarīgus aspektus un jauninājumus Transformeru saimē. Top saraksts aptvers apmācīti modeļi izmantojot pašpārvaldes apmācību, piemēram, BERT vai GPT-3, kā arī modeļi, kas tiek pakļauti papildu apmācībai, iesaistot cilvēkus, piemēram, InstructGPT modelis, ko izmantoja ChatGPT.

| Pro padomi |
|---|
| Šī rokasgrāmata ir izstrādāts, lai sniegtu visaptverošas zināšanas un praktiskās iemaņas tūlītējā inženierijā iesācējiem līdz pieredzējušiem audzēkņiem. |
| Ir daudz kursu pieejams personām, kuras vēlas uzzināt vairāk par AI un ar to saistītajām tehnoloģijām. |
| Veikt apskatīt 10+ labākie AI paātrinātāji sagaidāms, ka tas būs tirgus līderis veiktspējas ziņā. |
Kas ir AI transformatori?
Transformatori ir dziļas mācīšanās modeļu veids, kas tika ieviests pētnieciskajā dokumentā ar nosaukumu "Uzmanība ir viss, kas jums nepieciešamsGoogle pētnieki 2017. gadā. Šis dokuments ir guvis milzīgu atzinību, tikai piecu gadu laikā uzkrājot vairāk nekā 38,000 XNUMX citātu.
Sākotnējā Transformatora arhitektūra ir specifiska kodētāja-dekodētāja modeļu forma, kas bija guvusi popularitāti pirms tās ieviešanas. Šie modeļi galvenokārt balstījās uz LSTM un citas atkārtotu neironu tīklu variācijas (RNNs), uzmanība ir tikai viens no izmantotajiem mehānismiem. Tomēr Transformera dokumentā tika ierosināta revolucionāra ideja, ka uzmanība varētu kalpot kā vienīgais mehānisms, lai noteiktu atkarības starp ievadi un izvadi.
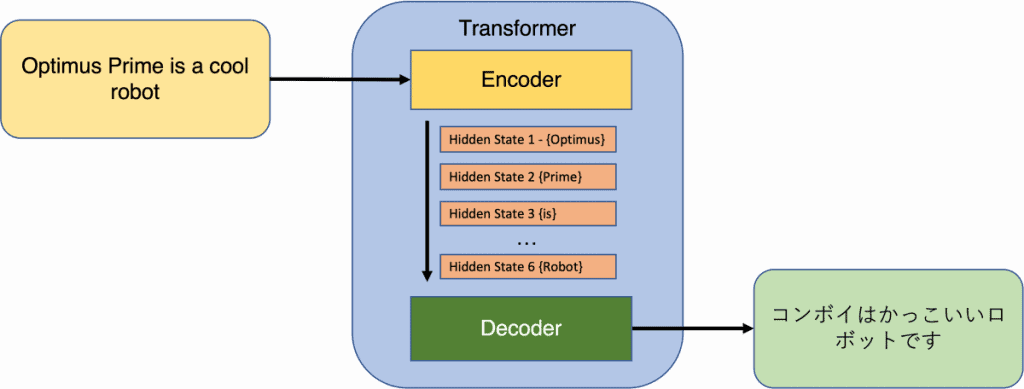
Transformatoru kontekstā ievade sastāv no marķieru secības, kas var būt vārdi vai apakšvārdi dabiskās valodas apstrādē (NLP). Apakšvārdi parasti tiek izmantoti NLP modeļos, lai risinātu jautājumu par vārdiem, kas ir ārpus vārdnīcas. Kodētāja izvade rada fiksētas dimensijas attēlojumu katram marķierim, kā arī atsevišķu iegulšanu visai secībai. Dekodētājs izmanto kodētāja izvadi un ģenerē marķieru secību kā izvadi.
Kopš Transformeru papīra publicēšanas tādi populāri modeļi kā BERT un GPT ir pārņēmuši sākotnējās arhitektūras aspektus, izmantojot kodētāja vai dekodētāja komponentus. Galvenā līdzība starp šiem modeļiem ir slāņu arhitektūrā, kurā ir iekļauti pašizvērības mehānismi un pārejas slāņi. Transformatoros katrs ievades marķieris šķērso savu ceļu cauri slāņiem, vienlaikus saglabājot tiešas atkarības ar katru citu marķieri ievades secībā. Šī unikālā funkcija ļauj paralēli un efektīvi aprēķināt kontekstuālo marķieru attēlojumu, kas nav iespējama ar secīgiem modeļiem, piemēram, RNN.
Lai gan šis raksts tikai saskrāpē transformatora arhitektūras virsmu, tas sniedz ieskatu tās pamataspektos. Lai iegūtu plašāku izpratni, iesakām atsaukties uz oriģinālo pētījumu vai ziņu The Illustrated Transformer.
Kas ir AI kodētāji un dekoderi?
Iedomājieties, ka jums ir divi modeļi — kodētājs un dekodētājs, strādāt kopā kā komanda. Kodētājs ņem ievadi un pārvērš to fiksēta garuma vektorā. Pēc tam dekodētājs ņem šo vektoru un pārveido to izvades secībā. Šie modeļi ir apmācīti kopā, lai pārliecinātos, ka izvade pēc iespējas precīzāk atbilst ievadei.
Gan kodētājam, gan dekodētājam bija vairāki slāņi. Katram kodētāja slānim bija divi apakšslāņi: vairāku galviņu pašapziņas slānis un vienkāršs padeves tīkls. Pašuzmanības slānis palīdz katram ievades marķierim izprast attiecības ar visiem citiem marķieriem. Šiem apakšslāņiem ir arī atlikušais savienojums un slāņu normalizācija, lai mācību process būtu vienmērīgāks.
Dekodera daudzgalva sevis uzmanības slānis darbojas nedaudz savādāk nekā kodētājā. Tas maskē marķierus pa labi no marķiera, uz kuru tas fokusējas. Tas nodrošina, ka dekodētājs aplūko tikai tos marķierus, kas ir pirms tā, ko tas mēģina paredzēt. Šī maskētā vairāku galvu uzmanība palīdz dekodētājam radīt precīzas prognozes. Turklāt dekodētājā ir iekļauts vēl viens apakšslānis, kas ir vairāku galviņu uzmanības slānis pār visām kodētāja izejām.
Ir svarīgi atzīmēt, ka šīs īpašās detaļas ir pārveidotas dažādās transformatora modeļa variācijās. Modeļi, piemēram, BERT un GPT, piemēram, ir balstīti vai nu uz sākotnējās arhitektūras kodētāja vai dekodētāja aspektu.
Kas ir uzmanības slāņi AI?
Modeļa arhitektūrā, par kuru mēs runājām iepriekš, vairāku galvu uzmanības slāņi ir īpašie elementi, kas padara to jaudīgu. Bet kas īsti ir uzmanība? Uztveriet to kā funkciju, kas sakārto jautājumu ar informācijas kopu un dod rezultātu. Katram ievades marķierim ir ar to saistīts vaicājums, atslēga un vērtība. Katra marķiera izvades attēlojums tiek aprēķināts, ņemot svērto vērtību summu, kur katras vērtības svaru nosaka pēc tā, cik labi tā atbilst vaicājumam.
Lai aprēķinātu šos svarus, transformatori izmanto saderības funkciju, ko sauc par mērogotu punktu produktu. Interesantā lieta par uzmanību programmā Transformers ir tāda, ka katrs marķieris iziet savu aprēķina ceļu, ļaujot paralēli aprēķināt visus ievades secības marķierus. Tie ir vienkārši vairāki uzmanības bloki, kas neatkarīgi aprēķina katra marķiera attēlojumu. Pēc tam šie attēlojumi tiek apvienoti, lai izveidotu marķiera galīgo attēlojumu.
Salīdzinot ar cita veida tīkliem, piemēram, atkārtotiem un konvolūcijas tīkli, uzmanības slāņiem ir dažas priekšrocības. Tie ir skaitļošanas ziņā efektīvi, kas nozīmē, ka tie var ātri apstrādāt informāciju. Viņiem ir arī augstāka savienojamība, kas ir noderīga ilgtermiņa attiecību tveršanai secībā.
Kas ir precīzi noregulētie AI modeļi?
Pamatu modeļi ir spēcīgi modeļi, kas tiek apmācīti, izmantojot lielu daudzumu vispārīgu datu. Pēc tam tos var pielāgot vai precīzi noregulēt konkrētiem uzdevumiem, apmācot tos mazākā komplektācijā mērķim specifiski dati. Šo pieeju popularizēja BERT papīrs, ir novedis pie transformatora modeļu dominēšanas ar valodu saistītos mašīnmācīšanās uzdevumos.
Tādu modeļu kā BERT gadījumā tie veido ievades marķieru attēlojumus, bet neveic konkrētus uzdevumus atsevišķi. Lai tie būtu noderīgi, papildu nervu slāņi tiek pievienoti augšpusē, un modelis tiek apmācīts līdz galam — šis process ir pazīstams kā precizēšana. Tomēr ar ģeneratīvie modeļi tāpat GPT, pieeja ir nedaudz atšķirīga. GPT ir dekodētāja valodas modelis, kas apmācīts paredzēt nākamo vārdu teikumā. Apmācot lielu daudzumu tīmekļa datu, GPT var ģenerēt saprātīgus rezultātus, pamatojoties uz ievades vaicājumiem vai uzvednēm.
Lai veiktu GPT noderīgāks, OpenAI pētnieki izstrādāja NorādietGPT, kas ir apmācīts ievērot cilvēku norādījumus. Tas tiek panākts, precizējot GPT izmantojot cilvēku marķētus datus no dažādiem uzdevumiem. PamācītGPT spēj veikt plašu uzdevumu klāstu, un to izmanto tādi populāri dzinēji kā ChatGPT.
Precizitāti var izmantot arī, lai izveidotu pamatu modeļu variantus, kas ir optimizēti īpašiem mērķiem ārpus valodas modelēšanas. Piemēram, ir modeļi, kas precīzi pielāgoti tādiem semantiskiem uzdevumiem kā teksta klasifikācija un meklēšanas izguve. Turklāt transformatoru kodētāji ir veiksmīgi noregulēti vairāku uzdevumu ietvaros mācību ietvarus veikt vairākus semantiskus uzdevumus, izmantojot vienu koplietotu modeli.
Mūsdienās precizēšanu izmanto, lai izveidotu pamatu modeļu versijas, kuras var izmantot liels skaits lietotāju. Process ietver atbildes ģenerēšanu uz ievadi uzvednes un likt cilvēkiem sarindot rezultātus. Šo klasifikāciju izmanto, lai apmācītu a atlīdzības modelis, kas piešķir punktu skaitu katrai izvadei. Mācību pastiprināšana ar cilvēku atgriezenisko saiti pēc tam tiek izmantots, lai turpinātu modeļa apmācību.
Kāpēc Transformatori ir AI nākotne?
Transformatori, jaudīga modeļa veids, pirmo reizi tika demonstrēti valodu tulkošanas jomā. Tomēr pētnieki ātri saprata, ka Transformatorus var izmantot dažādiem ar valodu saistītiem uzdevumiem, apmācot tos ar lielu daudzumu nemarķēta teksta un pēc tam precizējot tos, izmantojot mazāku marķētu datu kopu. Šī pieeja ļāva Transformatoriem iegūt nozīmīgas zināšanas par valodu.
Transformatora arhitektūra, kas sākotnēji bija paredzēta valodu uzdevumiem, ir piemērota arī citām lietojumprogrammām, piemēram attēlu ģenerēšana, audio, mūzika un pat darbības. Tas ir padarījis transformatorus par galveno sastāvdaļu ģeneratīvā AI jomā, kas maina dažādus sabiedrības aspektus.
Tādu rīku un ietvaru pieejamība kā PyTorch un TensorFlow ir bijusi izšķiroša loma Transformeru modeļu plašā ieviešanā. Tādi uzņēmumi kā Huggingface ir izveidojuši savu bizness ap ideju Atvērtā koda Transformatoru bibliotēku komercializācija un specializētā aparatūra, piemēram, NVIDIA Hopper Tensor Cores, ir vēl vairāk paātrinājusi šo modeļu apmācību un secinājumu veikšanas ātrumu.
Viens ievērojams Transformeru pielietojums ir ChatGPT, tērzēšanas robots, ko izlaida OpenAI. Tas kļuva neticami populārs, īsā laikā sasniedzot miljoniem lietotāju. OpenAI ir arī paziņojis par atbrīvošanu GPT-4, jaudīgāka versija, kas spēj sasniegt cilvēkam līdzīgu veiktspēju tādos uzdevumos kā medicīniskās un juridiskās pārbaudes.
Transformatoru ietekme AI jomā un to plašā pielietojuma klāsts ir nenoliedzama. Viņiem ir pārveidoja ceļu mēs pievēršamies ar valodu saistītiem uzdevumiem un bruģējam ceļu jauniem sasniegumiem ģeneratīvajā AI.
3 Pirmsapmācības arhitektūru veidi
Transformatora arhitektūra, kas sākotnēji sastāvēja no kodētāja un dekodētāja, ir attīstījusies, iekļaujot dažādas variācijas, pamatojoties uz īpašām vajadzībām. Sadalīsim šīs variācijas vienkāršā izteiksmē.
- Kodētāja priekšapmācība: šie modeļi ir vērsti uz pilnīgu teikumu vai fragmentu izpratni. Iepriekšējas apmācības laikā kodētājs tiek izmantots, lai ievades teikumā rekonstruētu maskētos marķierus. Tas palīdz modelim iemācīties izprast vispārējo kontekstu. Šādi modeļi ir noderīgi tādiem uzdevumiem kā teksta klasifikācija, saistība un izsmeļoša atbildes uz jautājumiem.
- Dekodera priekšapmācība: Dekoderu modeļi ir apmācīti ģenerēt nākamo marķieri, pamatojoties uz iepriekšējo marķieru secību. Tie ir pazīstami kā automātiski regresīvie valodu modeļi. Pašuzmanības slāņi dekodētājā var piekļūt tikai tiem marķieriem, kas ir pirms dotā marķiera teikumā. Šie modeļi ir ideāli piemēroti uzdevumiem, kas saistīti ar teksta ģenerēšanu.
- Transformatora (kodētāja-dekodētāja) iepriekšēja apmācība: šajā variantā ir apvienoti gan kodētāja, gan dekodētāja komponenti. Kodētāja pašapziņas slāņi var piekļūt visiem ievades marķieriem, savukārt dekodētāja pašapziņas slāņi var piekļūt tikai marķieriem pirms dotā marķiera. Šī arhitektūra ļauj dekodētājam izmantot kodētāja apgūtos attēlojumus. Kodētāja-dekodētāja modeļi ir labi piemēroti tādiem uzdevumiem kā apkopošana, tulkošana vai ģeneratīvas atbildes uz jautājumiem.
Pirmsapmācības mērķi var ietvert trokšņa mazināšanu vai cēloņsakarības valodas modelēšanu. Šie mērķi ir sarežģītāki kodētāja-dekodētāja modeļiem, salīdzinot ar modeļiem, kas paredzēti tikai kodētājam vai tikai dekodētājam. Transformatora arhitektūrai ir dažādas variācijas atkarībā no modeļa fokusa. Neatkarīgi no tā, vai tā ir veselu teikumu izpratne, teksta ģenerēšana vai abu apvienošana dažādiem uzdevumiem, Transformers piedāvā elastību dažādu ar valodu saistītu problēmu risināšanā.
8 uzdevumu veidi iepriekš apmācītiem modeļiem
Apmācot modeli, mums ir jādod tam uzdevums vai mērķis, no kā mācīties. Dabiskās valodas apstrādē (NLP) ir dažādi uzdevumi, kurus var izmantot priekšapmācības modeļiem. Sadalīsim dažus no šiem uzdevumiem vienkāršā izteiksmē:
- Valodas modelēšana (LM): modelis paredz nākamo marķieri teikumā. Tā mācās izprast kontekstu un ģenerēt sakarīgus teikumus.
- Cēloņvalodas modelēšana: modelis paredz nākamo marķieri teksta secībā, ievērojot secību no kreisās uz labo pusi. Tas ir kā stāstu modelis, kas ģenerē teikumus pa vienam vārdam.
- Prefiksa valodas modelēšana: modelis atdala “prefiksa” sadaļu no galvenās secības. Tas var izmantot jebkuru marķieri prefiksā un pēc tam autorregresīvi ģenerē pārējo secību.
- Maskētās valodas modelēšana (MLM): daži marķieri ievades teikumos ir maskēti, un modelis paredz trūkstošos marķierus, pamatojoties uz apkārtējo kontekstu. Tā iemācās aizpildīt tukšās vietas.
- Permutētās valodas modelēšana (PLM): modelis paredz nākamo marķieri, pamatojoties uz nejaušu ievades secības permutāciju. Tā iemācās rīkoties ar dažādiem žetonu pasūtījumiem.
- Denoising Autoencoder (DAE): modelis izmanto daļēji bojātu ievadi, un tā mērķis ir atgūt sākotnējo, neizkropļoto ievadi. Tā iemācās rīkoties ar troksni vai trūkstošām teksta daļām.
- Aizstātā marķiera noteikšana (RTD): modelis nosaka, vai marķieris nāk no oriģinālā teksta vai ģenerētas versijas. Tas iemācās identificēt aizstātos vai manipulētos marķierus.
- Nākamā teikuma paredzēšana (NSP): modelis mācās atšķirt, vai divi ievades teikumi ir nepārtraukti segmenti no apmācības datiem. Tas saprot attiecības starp teikumiem.
Šie uzdevumi palīdz modelim apgūt valodas struktūru un nozīmi. Iepriekš apmācot šos uzdevumus, modeļi iegūst labu valodas izpratni, pirms tie tiek pielāgoti konkrētām lietojumprogrammām.
30+ populārākie AI transformatori
| Vārds | Arhitektūras pirmsapmācība | Uzdevums | iesniegums | Izstrādāja |
|---|---|---|---|---|
| ALBERT | kodētājs | MLM/NSP | Tas pats, kas BERT | |
| Alpaka | dekodētājs | LM | Teksta ģenerēšanas un klasifikācijas uzdevumi | Stenforda |
| AlphaFold | kodētājs | Proteīna locīšanas prognoze | Olbaltumvielu locīšana | Deep Mind |
| Antropiskais palīgs (skatīt arī) | dekodētājs | LM | No vispārīga dialoga līdz koda palīgam. | Antropisks |
| BART | Kodētājs/dekodētājs | DAE | Teksta ģenerēšanas un teksta izpratnes uzdevumi | |
| BERT | kodētājs | MLM/NSP | Valodas izpratne un atbildes uz jautājumiem | |
| BlenderBot 3 | dekodētājs | LM | Teksta ģenerēšanas un teksta izpratnes uzdevumi | |
| BLOOM | dekodētājs | LM | Teksta ģenerēšanas un teksta izpratnes uzdevumi | Lielā zinātne / Huggingface |
| ChatGPT | dekodētājs | LM | Dialoga aģenti | OpenAI |
| šinšilla | dekodētājs | LM | Teksta ģenerēšanas un teksta izpratnes uzdevumi | Deep Mind |
| CLIP | kodētājs | Attēlu/objektu klasifikācija | OpenAI | |
| CTRL | dekodētājs | Kontrolējama teksta ģenerēšana | Salesforce | |
| DALL-E | dekodētājs | Parakstu prognoze | Teksts uz attēlu | OpenAI |
| DALL-E-2 | Kodētājs/dekodētājs | Parakstu prognoze | Teksts uz attēlu | OpenAI |
| DeBERta | dekodētājs | MLM | Tas pats, kas BERT | microsoft |
| Lēmumu transformatori | dekodētājs | Nākamās darbības prognoze | Vispārīgi RL (pastiprināšanas mācību uzdevumi) | Google/UC Berkeley/FAIR |
| DialoGPT | dekodētājs | LM | Teksta ģenerēšana dialoga iestatījumos | microsoft |
| DistilBERTS | kodētājs | MLM/NSP | Valodas izpratne un atbildes uz jautājumiem | Apskāva seja |
| DQ-BART | Kodētājs/dekodētājs | DAE | Teksta ģenerēšana un izpratne | Amazone |
| Lellīte | dekodētājs | LM | Teksta ģenerēšanas un klasifikācijas uzdevumi | Databricks, Inc |
| ĒRNIJS | kodētājs | MLM | Zināšanu ietilpīgi saistīti uzdevumi | Dažādas Ķīnas iestādes |
| Flamings | dekodētājs | Parakstu prognoze | Teksts uz attēlu | Deep Mind |
| Galactica | dekodētājs | LM | Zinātniskā kvalitātes nodrošināšana, matemātiskā spriešana, apkopošana, dokumentu ģenerēšana, molekulāro īpašību prognozēšana un entītiju iegūšana. | meta |
| LĪDZEKLIS | kodētājs | Parakstu prognoze | Teksts uz attēlu | OpenAI |
| GPT-3.5 | dekodētājs | LM | Dialogs un vispārīgā valoda | OpenAI |
| GPTNorādiet | dekodētājs | LM | Zināšanu ietilpīgi dialoga vai valodas uzdevumi | OpenAI |
| HTML | Kodētājs/dekodētājs | DAE | Valodas modelis, kas pieļauj strukturētu HTML uzvedni | |
| Attēls | T5 | Parakstu prognoze | Teksts uz attēlu | |
| LAMDA | dekodētājs | LM | Vispārējās valodas modelēšana | |
| LLaMA | dekodētājs | LM | Saprāta spriešana, atbildes uz jautājumiem, koda ģenerēšana un lasīšanas izpratne. | meta |
| Minerva | dekodētājs | LM | Matemātiskā spriešana | |
| palma | dekodētājs | LM | Valodas izpratne un paaudze | |
| Roberta | kodētājs | MLM | Valodas izpratne un atbildes uz jautājumiem | UW/Google |
| Zvirbulis | dekodētājs | LM | Dialoga aģenti un vispārīgas valodu ģenerēšanas lietojumprogrammas, piemēram, jautājumi un atbildes | Deep Mind |
| Stabila difūzija | Kodētājs/dekodētājs | Parakstu pareģošana | Teksts uz attēlu | LMU Minhene + Stability.ai + Eleuther.ai |
| Vicuna | dekodētājs | LM | Dialoga aģenti | UC Berkeley, CMU, Stenforda, UC Sandjego un MBZUAI |
FAQ
AI transformatori ir sava veida dziļas mācīšanās arhitektūra kas ir mainījis dabiskās valodas apstrādi un citus uzdevumus. Viņi izmanto sevis uzmanības mehānismus, lai uztvertu attiecības starp vārdiem teikumā, ļaujot viņiem saprast un ģenerēt cilvēkiem līdzīgu tekstu.
Kodētāji un dekoderi ir komponenti, ko parasti izmanto secības-secības modeļos. Kodētāji apstrādā ievades datus, piemēram, tekstu vai attēlus, un pārvērš tos saspiestā attēlojumā, savukārt dekoderi ģenerē izejas datus, pamatojoties uz kodēto attēlojumu, ļaujot veikt tādus uzdevumus kā valodas tulkošana vai attēlu paraksti.
Uzmanības slāņi ir komponenti, kas tiek izmantoti neironu tīkli, jo īpaši transformatoru modeļos. Tie ļauj modelim selektīvi koncentrēties uz dažādām ievades secības daļām, piešķirot katram elementam svaru, pamatojoties uz tā atbilstību, ļaujot efektīvi uztvert atkarības un attiecības starp elementiem.
Precīzi pielāgoti modeļi attiecas uz iepriekš apmācītiem modeļiem, kas ir tālāk apmācīti konkrētam uzdevumam vai datu kopai, lai uzlabotu to veiktspēju un pielāgotu tos konkrētā uzdevuma prasībām. Šis precizēšanas process ietver modeļa parametru pielāgošanu, lai optimizētu tā prognozes un padarītu to specializētāku mērķa uzdevumam.
Transformatori tiek uzskatīti par mākslīgā intelekta nākotni, jo tie ir demonstrējuši izcilu veiktspēju plašā uzdevumu klāstā, tostarp dabiskās valodas apstrādē, attēlu ģenerēšanā un citur. To spēja uztvert liela attāluma atkarības un efektīvi apstrādāt secīgus datus padara tos ļoti pielāgojamus un efektīvus dažādām lietojumprogrammām, paverot ceļu ģeneratīvā AI progresam un mainot daudzus sabiedrības aspektus.
Slavenākie AI transformatoru modeļi ir BERT (transformatoru divvirzienu kodētāja attēlojumi), GPT (Ģeneratīvais iepriekš apmācīts transformators) un T5 (Teksta pārsūtīšanas transformators). Šie modeļi ir sasnieguši ievērojamus rezultātus dažādos dabiskās valodas apstrādes uzdevumos un ir guvuši ievērojamu popularitāti AI pētnieku aprindās.
Lasiet vairāk par AI:
Atbildības noraidīšana
Atbilstīgi Uzticības projekta vadlīnijas, lūdzu, ņemiet vērā, ka šajā lapā sniegtā informācija nav paredzēta un to nedrīkst interpretēt kā juridisku, nodokļu, ieguldījumu, finanšu vai jebkāda cita veida padomu. Ir svarīgi ieguldīt tikai to, ko varat atļauties zaudēt, un meklēt neatkarīgu finanšu padomu, ja jums ir šaubas. Lai iegūtu papildinformāciju, iesakām skatīt pakalpojumu sniegšanas noteikumus, kā arī palīdzības un atbalsta lapas, ko nodrošina izdevējs vai reklāmdevējs. MetaversePost ir apņēmies sniegt precīzus, objektīvus pārskatus, taču tirgus apstākļi var tikt mainīti bez iepriekšēja brīdinājuma.
Par Autors
Damirs ir komandas vadītājs, produktu vadītājs un redaktors Metaverse Post, kas aptver tādas tēmas kā AI/ML, AGI, LLM, Metaverse un Web3- saistītie lauki. Viņa raksti katru mēnesi piesaista lielu auditoriju, kas pārsniedz miljonu lietotāju. Šķiet, ka viņš ir eksperts ar 10 gadu pieredzi SEO un digitālā mārketinga jomā. Damirs ir minēts Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto un citas publikācijas. Viņš ceļo starp AAE, Turciju, Krieviju un NVS kā digitālais nomads. Damirs ir ieguvis bakalaura grādu fizikā, kas, viņaprāt, ir devis viņam kritiskās domāšanas prasmes, kas nepieciešamas, lai gūtu panākumus nepārtraukti mainīgajā interneta vidē.
Vairāk rakstus
Damirs ir komandas vadītājs, produktu vadītājs un redaktors Metaverse Post, kas aptver tādas tēmas kā AI/ML, AGI, LLM, Metaverse un Web3- saistītie lauki. Viņa raksti katru mēnesi piesaista lielu auditoriju, kas pārsniedz miljonu lietotāju. Šķiet, ka viņš ir eksperts ar 10 gadu pieredzi SEO un digitālā mārketinga jomā. Damirs ir minēts Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto un citas publikācijas. Viņš ceļo starp AAE, Turciju, Krieviju un NVS kā digitālais nomads. Damirs ir ieguvis bakalaura grādu fizikā, kas, viņaprāt, ir devis viņam kritiskās domāšanas prasmes, kas nepieciešamas, lai gūtu panākumus nepārtraukti mainīgajā interneta vidē.






