



GPT-4 Pārmanto “halucinējošus” faktus un pamatojuma kļūdas no agrāk GPT Modeļi






Īsumā
OpenAI saka GPT-4 ir līdzīgi ierobežojumi kā iepriekš GPT modeļi.
GPT-4 joprojām halucinē faktus un pieļauj argumentācijas kļūdas.
Tomēr, GPT-4 punktu skaits ir par 40% augstāks nekā OpenAIir jaunākais GPT-3.5 par uzņēmuma iekšējiem pretrunīguma faktu novērtējumiem.

OpenAI ir brīdinājis lietotājus, ka tā jaunākais valodas modelis, GPT-4, joprojām nav pilnībā uzticams un var “halucinēt” faktus un pieļaut argumentācijas kļūdas. Uzņēmums mudina lietotājus ievērot piesardzību, izmantojot valodas modeļa rezultātus, jo īpaši “augstu likmju kontekstos”.
Tomēr labā ziņa ir tā GPT-4 ievērojami samazina halucinācijas salīdzinājumā ar iepriekšējiem modeļiem. OpenAI apgalvo, ka GPT-4 punktu skaits ir par 40% augstāks nekā jaunākais GPT-3.5 par iekšējiem pretrunīguma faktu novērtējumiem.
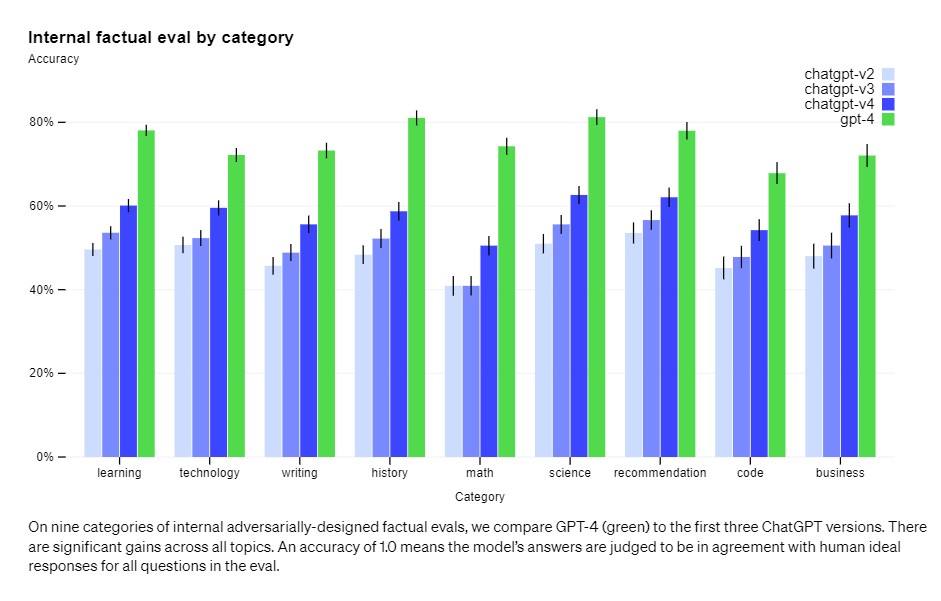
“Mēs esam panākuši progresu ārējos etalonos, piemēram, TruthfulQA, kas pārbauda modeļa spēju nošķirt faktus no pretinieku izvēlētas nepareizu apgalvojumu kopas. Šie jautājumi ir saistīti ar faktiski nepareizām atbildēm, kas ir statistiski pievilcīgas. OpenAI rakstīja a blog post.
Neskatoties uz šo uzlabojumu, modelim joprojām trūkst zināšanu par notikumiem, kas notikuši pēc 2021. gada septembra, un dažreiz tas pieļauj vienkāršas argumentācijas kļūdas, tāpat kā iepriekšējos modeļos. Turklāt tas var būt pārāk lētticīgs, pieņemot acīmredzamus nepatiesus paziņojumus no lietotājiem, un nespēj atrisināt nopietnas problēmas, piemēram, ieviešot savā kodā drošības ievainojamības. Tā arī nepārbauda sniegto informāciju.
Tāpat kā tās priekšgājēji, GPT-4 var radīt kaitīgus padomus, kļūdainu kodu vai neprecīzu informāciju. Tomēr modeļa papildu iespējas rada jaunas riska virsmas, kas ir jāsaprot. Lai novērtētu šo risku apmēru, vairāk nekā 50 ekspertu No dažādām jomām, tostarp AI saskaņošanas riskiem, kiberdrošības, bioriska, uzticamības un starptautiskās drošības, tika iesaistīti, lai pārbaudītu modeli pretrunīgi. Viņu atsauksmes un dati tika izmantoti, lai uzlabotu modeli, piemēram, apkopotu papildu datus, lai uzlabotu GPT-4spēja noraidīt pieprasījumus par bīstamu ķīmisko vielu sintezēšanu.
Viens no galvenajiem veidiem OpenAI kaitīgo izlaidumu samazināšana tiek veikta, iekļaujot papildu drošības atlīdzības signālu RLHF (Pastiprināšanas mācīšanās no cilvēka atgriezeniskās saites) apmācības laikā. Signāls apmāca modeli atteikt pieprasījumus par kaitīgu saturu, kā defisaskaņā ar modeļa lietošanas vadlīnijām. Atlīdzību nodrošina a GPT-4 nulles šāviena klasifikators, kas nosaka drošības robežas un pabeigšanas stilu pēc ar drošību saistītajiem norādījumiem.
OpenAI arī teica, ka tas ir samazinājis modeļa tendenci atbildēt uz neatļauta satura pieprasījumiem par 82%, salīdzinot ar GPT-3.5 un GPT-4 par 29% biežāk atbild uz sensitīviem pieprasījumiem, piemēram, medicīnisku padomu un paškaitējumu saskaņā ar uzņēmuma politiku.
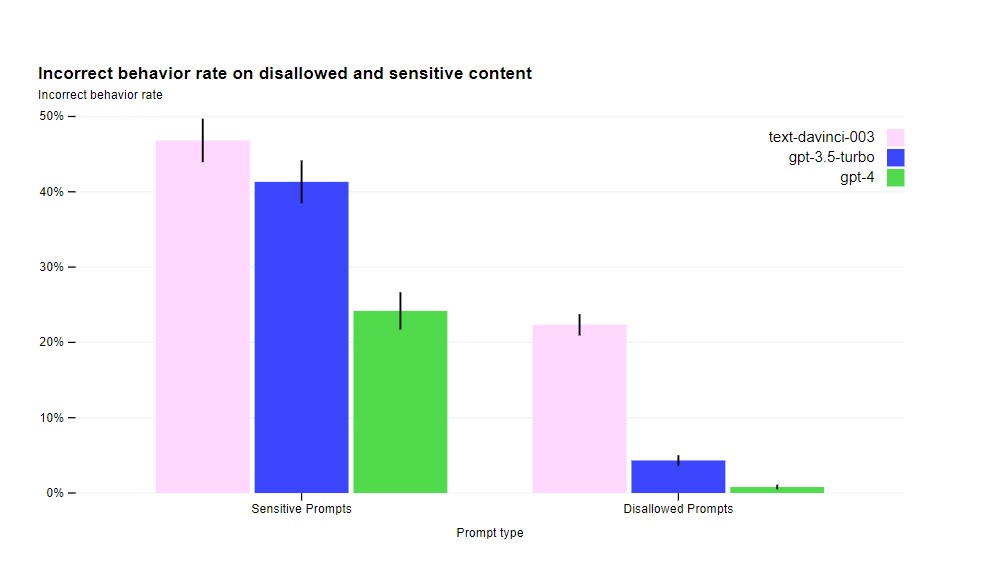
Kamēr OpenAI's iejaukšanās ir palielinājusi grūtības izraisīt sliktu uzvedību GPT-4, tas joprojām ir iespējams, un joprojām ir jailbreaks, kas var ģenerēt saturu, kas pārkāpj lietošanas vadlīnijas.
“Tā kā mākslīgā intelekta sistēmas kļūst arvien izplatītākas, augstas uzticamības pakāpes sasniegšana šajās intervencēs kļūs arvien svarīgāka. Pagaidām ir svarīgi šos ierobežojumus papildināt ar izvietošanas laika drošības metodēm, piemēram, ļaunprātīgas izmantošanas uzraudzību, ”piebilda uzņēmums.
OpenAI sadarbojas ar ārējiem pētniekiem, lai labāk izprastu un novērtētu iespējamo ietekmi GPT-4 un tā pēcteču modeļiem. Komanda arī izstrādā novērtējumus par bīstamām iespējām, kas var parādīties turpmākajās AI sistēmās. Tā kā viņi turpina pētīt potenciālo sociālo un ekonomiskā ietekme of GPT-4 un citas AI sistēmas, OpenAI savos atklājumos un atziņās savlaicīgi dalīsies ar sabiedrību.
Lasīt vairāk:
Atbildības noraidīšana
Atbilstīgi Uzticības projekta vadlīnijas, lūdzu, ņemiet vērā, ka šajā lapā sniegtā informācija nav paredzēta un to nedrīkst interpretēt kā juridisku, nodokļu, ieguldījumu, finanšu vai jebkāda cita veida padomu. Ir svarīgi ieguldīt tikai to, ko varat atļauties zaudēt, un meklēt neatkarīgu finanšu padomu, ja jums ir šaubas. Lai iegūtu papildinformāciju, iesakām skatīt pakalpojumu sniegšanas noteikumus, kā arī palīdzības un atbalsta lapas, ko nodrošina izdevējs vai reklāmdevējs. MetaversePost ir apņēmies sniegt precīzus, objektīvus pārskatus, taču tirgus apstākļi var tikt mainīti bez iepriekšēja brīdinājuma.
Par Autors
Sindija ir žurnāliste Metaverse Post, aptverot tēmas, kas saistītas ar web3, NFT, metaverse un AI, koncentrējoties uz intervijām ar Web3 nozares spēlētājiem. Viņa ir runājusi ar vairāk nekā 30 C līmeņa vadītājiem, sniedzot lasītājiem viņu vērtīgās atziņas. Sākotnēji no Singapūras, Sindija tagad atrodas Tbilisi, Džordžijas štatā. Viņai ir bakalaura grāds komunikāciju un mediju studijās Dienvidaustrālijas Universitātē, un viņai ir desmit gadu pieredze žurnālistikā un rakstniecībā. Sazinieties ar viņu, izmantojot [e-pasts aizsargāts] ar preses prezentācijām, paziņojumiem un interviju iespējām.
Vairāk rakstus
Sindija ir žurnāliste Metaverse Post, aptverot tēmas, kas saistītas ar web3, NFT, metaverse un AI, koncentrējoties uz intervijām ar Web3 nozares spēlētājiem. Viņa ir runājusi ar vairāk nekā 30 C līmeņa vadītājiem, sniedzot lasītājiem viņu vērtīgās atziņas. Sākotnēji no Singapūras, Sindija tagad atrodas Tbilisi, Džordžijas štatā. Viņai ir bakalaura grāds komunikāciju un mediju studijās Dienvidaustrālijas Universitātē, un viņai ir desmit gadu pieredze žurnālistikā un rakstniecībā. Sazinieties ar viņu, izmantojot [e-pasts aizsargāts] ar preses prezentācijām, paziņojumiem un interviju iespējām.





