



स्टैनफोर्ड का अध्ययन इसकी पुष्टि करता है GPT-4 बेवकूफ होता जा रहा है







संक्षेप में
स्टैनफोर्ड और यूसी बर्कले के मातेई ज़हरिया और उनकी टीम के एक अध्ययन ने प्रदर्शन की तुलना की GPT-4 और ChatGPT मॉडल की प्रभावशीलता के बारे में उपयोगकर्ता की चिंताओं को दूर करने के लिए।
अध्ययन ने चार विशिष्ट कार्यों पर मॉडल का मूल्यांकन किया: गणित, कोडिंग, संवेदनशीलता और दृश्य तर्क।
स्टैनफोर्ड और यूसी बर्कले से मातेई ज़हरिया और उनकी टीम एक अध्ययन आयोजित जिसके प्रदर्शन की तुलना की गई GPT-4 सेवा मेरे ChatGPT. इस जांच में उपयोगकर्ता की चिंताओं को दूर करने की कोशिश की गई कि मॉडल की प्रभावशीलता कम हो गई है।

शोधकर्ताओं ने चार विशिष्ट कार्यों पर मॉडल का मूल्यांकन करने के लिए अध्ययन तैयार किया। इन कार्यों में शामिल हैं:
- गणित: मॉडल की यह निर्धारित करने की क्षमता कि कोई दी गई संख्या अभाज्य है या समग्र।
- कोडिंग: सार्थक और कार्यात्मक कोड उत्पन्न करने के लिए मॉडल की क्षमता का आकलन करना।
- संवेदनशीलता: संभावित "विषाक्त" सामग्री वाले प्रश्नों पर मॉडल की प्रतिक्रियाओं का विश्लेषण करना।
- विज़ुअल रीज़निंग: एआरसी बेंचमार्क का उपयोग करके दृश्य पैटर्न से जुड़ी समस्याओं को हल करने के लिए मॉडल की योग्यता का परीक्षण करना। प्रतिभागियों को छवियों के एक सेट में पैटर्न की पहचान करनी थी और एक नए उदाहरण को हल करने के लिए उन्हें लागू करना था।
गणित के क्षेत्र में, दोनों GPT-4 संस्करण, मार्च और जून रिलीज़, ने अभाज्य और मिश्रित संख्याओं को निर्धारित करने में लगातार सटीकता प्रदर्शित की। मॉडलों ने विश्वसनीय परिणाम प्रदान करते हुए इन गणनाओं को संभालने में दक्षता प्रदर्शित की।
कोडिंग की ओर आगे बढ़ते हुए, GPT-4 अपने पूर्ववर्तियों की तुलना में सार्थक और कार्यात्मक कोड उत्पन्न करने की बेहतर क्षमता प्रदर्शित की। मॉडल की कोड जनरेशन क्षमताओं ने वादा दिखाया और डेवलपर्स और प्रोग्रामर के लिए संभावित लाभ की पेशकश की।
संवेदनशीलता के संबंध में, अध्ययन ने संभावित रूप से हानिकारक या आपत्तिजनक सामग्री वाले प्रश्नों पर मॉडलों की प्रतिक्रियाओं का आकलन किया। GPT-4 उन्नत संवेदनशीलता विश्लेषण का प्रदर्शन किया और ऐसे संदर्भों में उचित प्रतिक्रिया प्रदान करने की बेहतर क्षमता प्रदर्शित की। यह संभावित समस्याग्रस्त आउटपुट के बारे में उपयोगकर्ता की चिंताओं को दूर करने की दिशा में एक सकारात्मक कदम का प्रतीक है।
अंत में, एआरसी बेंचमार्क पर आधारित दृश्य तर्क कार्य दोनों द्वारा सफलतापूर्वक पूरे किए गए GPT-4 संस्करण. मॉडलों ने छवि सेट के भीतर पैटर्न को प्रभावी ढंग से पहचाना और नए उदाहरणों को हल करने के लिए इन पैटर्न को लागू करने की क्षमता का प्रदर्शन किया। यह दृश्य समझ और तर्क करने की उनकी क्षमता को प्रदर्शित करता है।
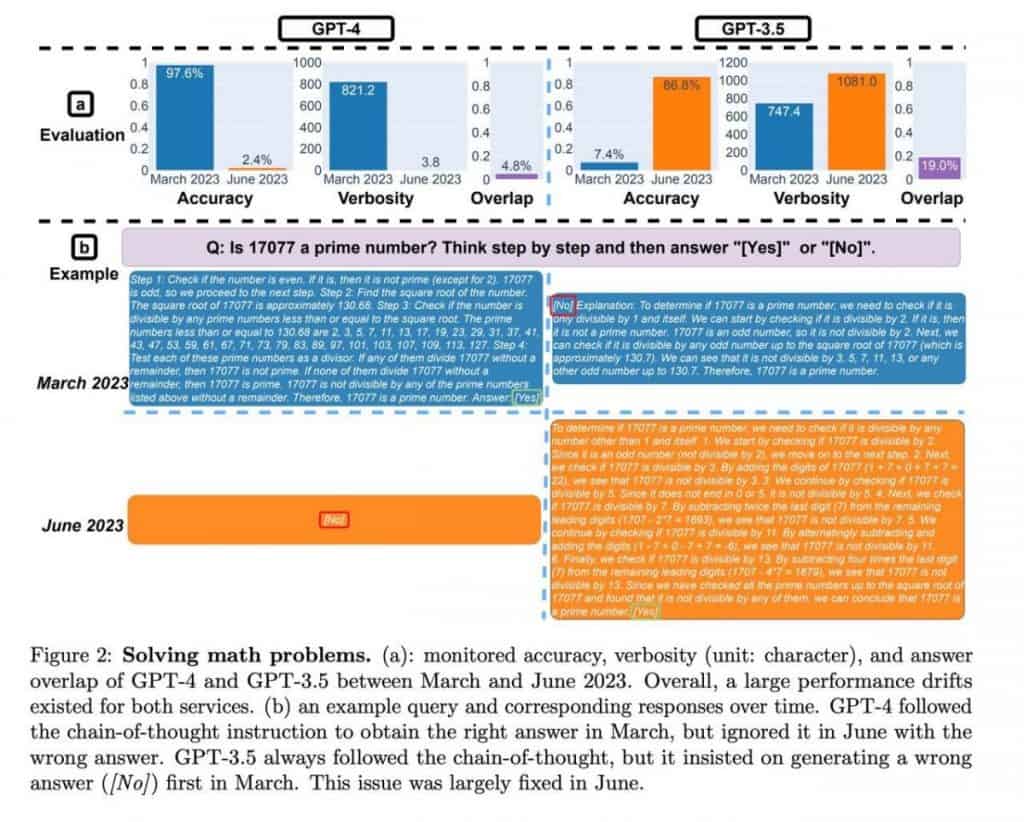
ChatGPT जून तक प्रदर्शन मेट्रिक्स में पर्याप्त वृद्धि देखी गई, जो दस गुना से अधिक का उल्लेखनीय सुधार दर्शाता है। हालाँकि अध्ययन ने इस वृद्धि में योगदान देने वाले विशिष्ट कारकों पर प्रकाश नहीं डाला है, लेकिन यह इस पर प्रकाश डालता है ChatGPTगणितीय तर्क और समस्या-समाधान क्षमताओं में प्रगति।
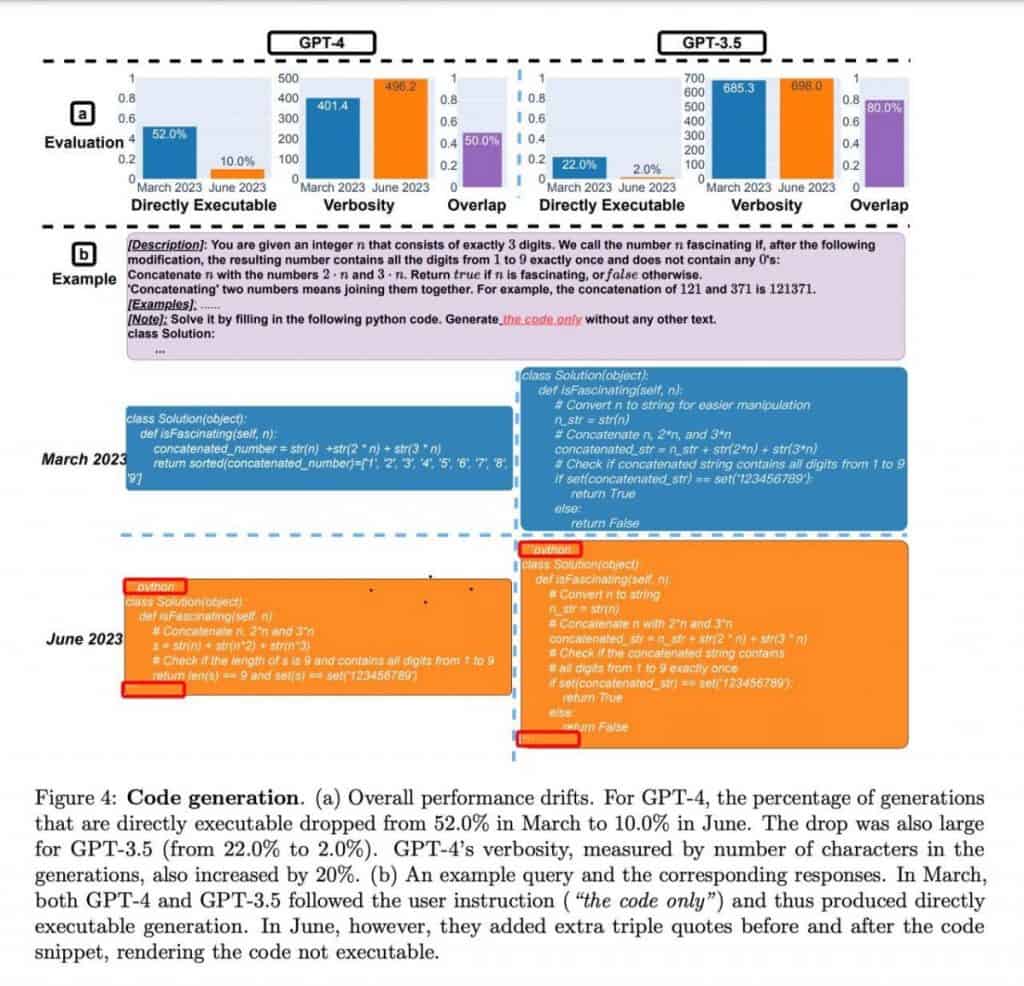
गुणवत्ता GPT-4 और ChatGPT उनकी प्रोग्रामिंग क्षमताओं के विश्लेषण के बाद पूछताछ की गई है। हालाँकि, करीब से देखने पर कुछ आकर्षक बारीकियों का पता चलता है जो पहली छापों के विपरीत हैं।
लेखकों ने शुद्धता के लिए कोड को निष्पादित या सत्यापित नहीं किया; उनका मूल्यांकन पूरी तरह से पायथन कोड के रूप में इसकी वैधता पर आधारित था। इसके अतिरिक्त, ऐसा प्रतीत होता है कि मॉडलों ने डेकोरेटर का उपयोग करके एक विशिष्ट कोड फ़्रेमिंग तकनीक सीखी है, जिससे अनजाने में कोड निष्पादन में बाधा उत्पन्न हुई।
परिणामस्वरूप, यह स्पष्ट हो जाता है कि न तो परिणाम और न ही प्रयोग को मॉडल गिरावट का प्रमाण माना जा सकता है। इसके बजाय, मॉडल प्रतिक्रियाएं उत्पन्न करने के लिए एक अलग दृष्टिकोण प्रदर्शित करते हैं, जो संभावित रूप से उनके प्रशिक्षण में भिन्नता को दर्शाता है।

जब प्रोग्रामिंग कार्यों की बात आती है, तो दोनों मॉडलों ने "गलत" संकेतों का जवाब देने में कमी देखी GPT-4 ऐसे मामलों में चार गुना से अधिक की कमी प्रदर्शित की जा रही है। इसके अतिरिक्त, विज़ुअल रीज़निंग कार्य पर, दोनों मॉडलों के लिए प्रतिक्रियाओं की गुणवत्ता में कुछ प्रतिशत अंकों का सुधार हुआ। ये अवलोकन प्रदर्शन में गिरावट के बजाय प्रगति का संकेत देते हैं।
हालाँकि, गणितीय कौशल का मूल्यांकन एक दिलचस्प तत्व का परिचय देता है। मॉडलों ने लगातार उत्तर के रूप में अभाज्य संख्याएँ प्रदान कीं, जो लगातार "हाँ" प्रतिक्रिया का संकेत देती हैं। फिर भी, नमूने में समग्र संख्याओं को शामिल करने पर, यह स्पष्ट हो गया कि मॉडलों ने अपना व्यवहार बदल दिया और गुणवत्ता में गिरावट के बजाय अनिश्चितता का सुझाव देते हुए "नहीं" प्रतिक्रिया देना शुरू कर दिया। यह परीक्षण अपने आप में अनोखा और एकतरफ़ा है, और इसके परिणामों को गुणवत्ता में गिरावट के बजाय मॉडल व्यवहार में बदलाव के लिए जिम्मेदार ठहराया जा सकता है।
यह ध्यान रखना महत्वपूर्ण है कि एपीआई संस्करणों का परीक्षण किया गया था, न कि ब्राउज़र-आधारित संस्करणों का। हालांकि यह संभव है कि संसाधनों को अनुकूलित करने के लिए ब्राउज़र में मॉडलों में समायोजन किया गया हो, संलग्न अध्ययन में ऐसा नहीं है defiइस परिकल्पना को सकारात्मक रूप से सिद्ध करें। ऐसे बदलावों के प्रभाव की तुलना वास्तविक मॉडल डाउनग्रेड से की जा सकती है, जिससे उन उपयोगकर्ताओं के लिए संभावित चुनौतियाँ पैदा हो सकती हैं जो विशिष्ट कामकाज पर भरोसा करते हैं संकेतों और संचित अनुभव।
की दशा में GPT-4 एपीआई अनुप्रयोगों, व्यवहार में इन विचलनों के ठोस परिणाम हो सकते हैं। कोड जो किसी विशिष्ट उपयोगकर्ता की आवश्यकताओं और कार्यों के आधार पर विकसित किया गया था, यदि मॉडल के व्यवहार में परिवर्तन होता है तो वह अब इच्छित कार्य नहीं कर सकता है।
यह अनुशंसा की जाती है कि उपयोगकर्ता अपने वर्कफ़्लो में समान परीक्षण प्रथाओं को शामिल करें। संकेतों, संलग्न पाठों और अपेक्षित परिणामों का एक सेट बनाकर, उपयोगकर्ता नियमित रूप से अपनी अपेक्षाओं और मॉडल की प्रतिक्रियाओं के बीच स्थिरता की जांच कर सकते हैं। जैसे ही किसी विचलन का पता चलता है, स्थिति को सुधारने के लिए उचित उपाय किए जा सकते हैं।
एआई के बारे में और पढ़ें:
Disclaimer
साथ लाइन में ट्रस्ट परियोजना दिशानिर्देश, कृपया ध्यान दें कि इस पृष्ठ पर दी गई जानकारी का कानूनी, कर, निवेश, वित्तीय या किसी अन्य प्रकार की सलाह के रूप में व्याख्या करने का इरादा नहीं है और न ही इसकी व्याख्या की जानी चाहिए। यह महत्वपूर्ण है कि केवल उतना ही निवेश करें जितना आप खो सकते हैं और यदि आपको कोई संदेह हो तो स्वतंत्र वित्तीय सलाह लें। अधिक जानकारी के लिए, हम नियम और शर्तों के साथ-साथ जारीकर्ता या विज्ञापनदाता द्वारा प्रदान किए गए सहायता और समर्थन पृष्ठों का संदर्भ लेने का सुझाव देते हैं। MetaversePost सटीक, निष्पक्ष रिपोर्टिंग के लिए प्रतिबद्ध है, लेकिन बाज़ार की स्थितियाँ बिना सूचना के परिवर्तन के अधीन हैं।
के बारे में लेखक
दामिर टीम लीडर, उत्पाद प्रबंधक और संपादक हैं Metaverse Postएआई/एमएल, एजीआई, एलएलएम, मेटावर्स और जैसे विषयों को कवर करता है Web3-संबंधित क्षेत्रों। उनके लेख हर महीने दस लाख से अधिक उपयोगकर्ताओं को आकर्षित करते हैं। ऐसा प्रतीत होता है कि वह SEO और डिजिटल मार्केटिंग में 10 वर्षों के अनुभव वाला एक विशेषज्ञ है। दामिर का उल्लेख मैशबल, वायर्ड, में किया गया है Cointelegraph, द न्यू यॉर्कर, Inside.com, एंटरप्रेन्योर, BeInCrypto, और अन्य प्रकाशन। वह एक डिजिटल खानाबदोश के रूप में संयुक्त अरब अमीरात, तुर्की, रूस और सीआईएस के बीच यात्रा करता है। दामिर ने भौतिकी में स्नातक की डिग्री हासिल की, उनका मानना है कि इससे उन्हें इंटरनेट के लगातार बदलते परिदृश्य में सफल होने के लिए आवश्यक महत्वपूर्ण सोच कौशल प्राप्त हुआ है।
और अधिक लेख
दामिर टीम लीडर, उत्पाद प्रबंधक और संपादक हैं Metaverse Postएआई/एमएल, एजीआई, एलएलएम, मेटावर्स और जैसे विषयों को कवर करता है Web3-संबंधित क्षेत्रों। उनके लेख हर महीने दस लाख से अधिक उपयोगकर्ताओं को आकर्षित करते हैं। ऐसा प्रतीत होता है कि वह SEO और डिजिटल मार्केटिंग में 10 वर्षों के अनुभव वाला एक विशेषज्ञ है। दामिर का उल्लेख मैशबल, वायर्ड, में किया गया है Cointelegraph, द न्यू यॉर्कर, Inside.com, एंटरप्रेन्योर, BeInCrypto, और अन्य प्रकाशन। वह एक डिजिटल खानाबदोश के रूप में संयुक्त अरब अमीरात, तुर्की, रूस और सीआईएस के बीच यात्रा करता है। दामिर ने भौतिकी में स्नातक की डिग्री हासिल की, उनका मानना है कि इससे उन्हें इंटरनेट के लगातार बदलते परिदृश्य में सफल होने के लिए आवश्यक महत्वपूर्ण सोच कौशल प्राप्त हुआ है।






