



एलएलएम प्रोग्राम: द न्यू पाथ टू फाइन-ट्यूनिंग न्यूरल मॉडल्स इन कॉम्प्लेक्स सिचुएशंस







संक्षेप में
लेखक एलएलएम कार्यक्रम नामक एक वैकल्पिक मार्ग का प्रस्ताव करते हैं, जिसे संदर्भ में सीखने के विकास के रूप में माना जा सकता है।
एलएलएम कार्यक्रम के माध्यम से किसी समस्या को हल करने की कुंजी किसी समस्या के समाधान को सरल चरणों के अनुक्रम में विघटित करने की क्षमता है।
एलएलएम अनुकूलन के दो मुख्य क्षेत्र हैं: पूर्व-प्रशिक्षित बेस मॉडल और इन-कॉन्टेक्स्ट लर्निंग को फाइन-ट्यूनिंग (या अतिरिक्त प्रशिक्षण)। फाइन-ट्यूनिंग के लिए महत्वपूर्ण कंप्यूटिंग संसाधनों, डेटा संग्रह और आधारभूत संरचना की आवश्यकता होती है ताकि ऐसा किया जा सके और फिर फाइन-ट्यून किए गए मॉडल होस्ट किए जा सकें। इस बीच, इन-कॉन्टेक्स्ट लर्निंग में समस्या को हल करने के उदाहरणों के साथ सही प्रॉम्प्ट को संकलित करना शामिल है, जैसे कि चेन-ऑफ-थॉट (सीओटी)। हालाँकि, कुछ कठिनाइयाँ हैं, जैसे कि पाठ का सीमित आकार जो मॉडल को प्रस्तुत किया जा सकता है और यह तथ्य कि एक जटिल मल्टी-पास प्रॉम्प्ट में, चरण एक-दूसरे के साथ हस्तक्षेप कर सकते हैं, और मॉडल को किसी चीज़ से विचलित किया जा सकता है जिससे फिलहाल विचलित नहीं होना चाहिए। लेखक एक वैकल्पिक मार्ग प्रस्तावित करते हैं जिसे कहा जाता है एलएलएम कार्यक्रम, जिसे इन-कॉन्टेक्स्ट लर्निंग के विकास के रूप में माना जा सकता है।

| अनुशंसित: शीघ्र इंजीनियरिंग अंतिम गाइड 2023 |
एलएलएम कार्यक्रम में बनाया गया है (एक पारंपरिक प्रोग्रामिंग भाषा, उदाहरण के लिए, पायथन में)। यह बाहरी कोड राज्य को संग्रहीत करने और मॉडल को चरण दर चरण बनाए रखने के लिए जिम्मेदार है। इसके कुछ प्रमुख फायदे हैं: प्रोग्रामिंग भाषाओं को इसके लिए अनुकूलित किया जाता है, उपलब्ध संदर्भ का आकार बढ़ता है, और चरण एक दूसरे के साथ हस्तक्षेप नहीं करते हैं। एलएलएम कार्यक्रम के माध्यम से किसी समस्या को हल करने की कुंजी किसी समस्या के समाधान को सरल चरणों के अनुक्रम में विघटित करने की क्षमता है। यह दृष्टिकोण पिछले कार्यों से भिन्न है, जहां मॉडल ने कैलकुलेटर जैसे बाहरी उपकरणों का उपयोग किया था कोड दुभाषिए राज्य को बनाए रखने के लिए. यह दृष्टिकोण अच्छा है क्योंकि इस तरह से एक जटिल और व्यापक कार्य का वर्णन करना संभव है, जिससे परीक्षण, डिबग और गुणवत्ता का मूल्यांकन करना आसान हो जाता है।
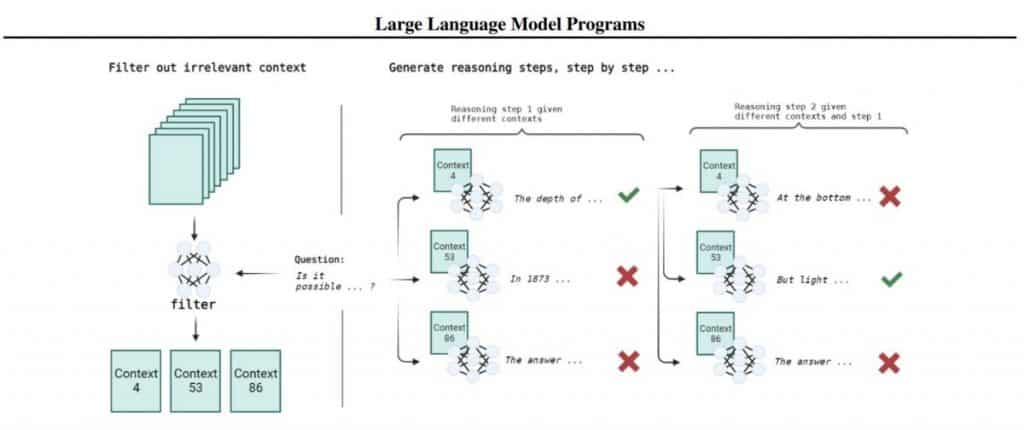
इसके अतिरिक्त, चरणों के बीच कोई हस्तक्षेप नहीं है, जिससे एलएलएम के साथ काम करना आसान हो जाता है। प्रश्न-उत्तर प्रणालियां भी नई नहीं हैं; वे एलएलएम से बहुत पहले से मौजूद हैं। सवालों के जवाब देने का काम अब कैसे हल होता है?
साइट्स को बार-बार अपडेट किया जाता है, इसलिए a जमे हुए मॉडल कोई विकल्प नहीं है; यह जल्दी से पुराना हो जाएगा और नए उत्पादों के बारे में प्रश्नों का उत्तर देने में सक्षम नहीं होगा। प्रत्येक अद्यतन के लिए मॉडल का लगातार पुनर्प्रशिक्षण एक यथार्थवादी विकल्प नहीं है: यह महंगा और समय लेने वाला है। इसके बजाय, एक वेबसाइट के पेजों को आमतौर पर अनुक्रमित किया जाता है, किसी प्रकार के डेटाबेस में रखा जाता है, और अक्सर वेक्टर किया जाता है। एक उपयोगकर्ता के अनुरोध पर, प्रासंगिक दस्तावेजों को खींच लिया जाता है और एलएलएम के संदर्भ के रूप में भेजा जाता है।
ऐसे प्रतिमान में, एलएलएम कार्यक्रम के माध्यम से समस्या स्वाभाविक रूप से हल हो जाती है। बोनस के रूप में, यह संभव हो जाता है अधिक जटिल मल्टी-पास लॉजिक को लागू करने के लिए जो पूरी तरह से संदर्भ में फिट नहीं होगा।
पर परीक्षण किया गया रणनीति क्यूए डेटासेट बाइनरी वर्गीकरण समस्याओं से युक्त, जिसके समाधान में बहु-तरफ़ा तर्क शामिल है। जैसे "क्या सूरज की रोशनी काला सागर की सबसे गहरी जगह में प्रवेश करती है?"। उत्तर देने के लिए, आपको अधिकतम गहराई (2 किमी) और कितनी गहरी रोशनी पानी (1 किमी) में प्रवेश करती है, और फिर एक निष्कर्ष निकालने की आवश्यकता है। आइए प्रश्न के एक अन्य उदाहरण पर एक नज़र डालें: "क्या अरस्तू ने लैपटॉप का उपयोग किया था?" यह प्रश्न उतना सीधा नहीं है और स्पष्ट रूप से "लैपटॉप के आविष्कार के समय अरस्तू जीवित था?" करता है। डेटासेट उन सवालों पर ध्यान केंद्रित करता है जहां ऐसा क्रम निहित है। डेटासेट में केवल 2,780 प्रश्न हैं, जिनमें से केवल 918 में साक्ष्य के साथ पैराग्राफ हैं जो तर्क के सभी चरणों को सुदृढ़ करते हैं। वर्तमान कार्य में, यह इस उपसमुच्चय तक सीमित है; अन्यथा, हमें पूर्व-प्रशिक्षण के दौरान कुछ तथ्यों को सीखने के लिए एलएलएम पर निर्भर रहना होगा।
OPT-175B LLM, डिफ़ॉल्ट रूप से, निर्देशों का पालन करने में बहुत अच्छा नहीं है; इसे न तो निर्देशों को ठीक करना था और न ही संवादी डेटा पर। साक्ष्य-समर्थित प्रश्न-उत्तर की समस्या को हल करने के लिए, डेटा फ़िल्टरिंग चरण और ट्री खोज चरण में विभाजित किया गया है।
फ़िल्टरिंग चरण में, एक प्रश्न होने पर, डेवलपर्स सभी अनुच्छेदों के माध्यम से जाते हैं और सबसे प्रासंगिक लोगों का चयन करते हैं। उदाहरण के लिए, कुछ-शॉट संकेत के साथ, एलएलएम से उत्तर देने के लिए कहें (हां/नहीं) कि क्या दिया गया पैराग्राफ पूछे गए प्रश्न के लिए प्रासंगिक है। स्ट्रेटेजीक्यूए के 300 सबसेट पर परीक्षण किया गया, जहां प्रत्येक प्रश्न का मिलान 50/50 के एक पैराग्राफ से किया गया, चाहे वह प्रासंगिक हो या नहीं। OPT-175B और text-davinci-002 में a नहीं है बहुत अधिक गुणवत्ता एक यादृच्छिक आधार रेखा से: 56% तक। उतना ही उन्नत 11बी टीके-निर्देश 61.6% पर ज्यादा बेहतर नहीं है।
इस दृष्टिकोण की खराब गुणवत्ता के कारण, एक विकल्प को एक साथ रखा गया था जो प्रश्न के औसत नकारात्मक लॉग-लाइबिलिटी (NLL) को पाठ के पूर्ववर्ती पैराग्राफ के संयोजन में मानता है और फिर परिणामों को रैंक करता है। डेटासेट पर मूल्यांकन किया गया जहां प्रत्येक प्रश्न के लिए 100 पैराग्राफ थे, और केवल एक ही प्रासंगिक था (इसलिए यादृच्छिक अनुमान 1% देता है)। हमें 1% पर शीर्ष -79 सटीकता और 5% पर शीर्ष -93 प्राप्त हुई। इस गणना के लिए, आपको आमतौर पर मॉडल तक ही पहुंच की आवश्यकता होती है, जो हमेशा एपीआई में नहीं किया जाता है।
इसके बाद आउटपुट चेन बनाने का चरण आता है। यह एक पेड़ के माध्यम से एक खोज के माध्यम से किया जाता है जहां प्रश्न जड़ है, और प्रत्येक स्तर पर, अगले चरण को उत्पन्न करने के लिए संदर्भ के रूप में उपयोग किए जाने वाले संभावित साक्ष्य के साथ कई पैराग्राफ हैं। वृक्ष के माध्यम से प्रत्येक पथ एक संभावित आउटपुट श्रृंखला है। सभी संभावित शृंखलाओं पर निष्कर्ष निकालना अवास्तविक है, इसलिए सभी उपलब्ध शृंखलाओं को श्रेणीबद्ध किया जाता है, और उच्चतम श्रेणी की शृंखला का विस्तार किया जाता है। यह बीम खोज का ऐसा रूपांतर है। जब कोई प्रतिक्रिया दी जाती है या चरणों की अधिकतम अनुमत संख्या पार हो जाती है तो प्रक्रिया रुक जाती है।
ट्री खोज चरण के लिए परीक्षण की गई दो रैंकिंग रणनीतियाँ सबसे महत्वपूर्ण विवरण हैं। पहली रणनीति पूरी श्रृंखला के औसत एनएलएल पर आधारित है, जबकि दूसरी रणनीति एनएलएल में पैराग्राफ (पी) के साथ और बिना प्रश्न (क्यू) के साथ और बिना औसत अंतर को देखती है। स्ट्रेटेजीक्यूए से उपलब्ध 918 प्रश्नों पर, यह दृष्टिकोण सीओटी (60%) के साथ बेसलाइन के सापेक्ष उत्तर गुणवत्ता में काफी सुधार करता है; दोनों खोज विकल्प लगभग 66% देते हैं (थोड़ी अधिक डेल्टा वाली रणनीति)। यदि सुनहरे तथ्य प्रस्तुत किए जाते हैं, तो गुणवत्ता लगभग 81% हो जाती है, जो ऑप्ट के लिए ऊपरी सीमा है। लगता है कि डार्कलैंग कहीं जा रहा है लेकिन थोड़े अलग तरीके से।
लेख टेलीग्राम पर आधारित है पद.
एआई के बारे में और पढ़ें:
Disclaimer
साथ लाइन में ट्रस्ट परियोजना दिशानिर्देश, कृपया ध्यान दें कि इस पृष्ठ पर दी गई जानकारी का कानूनी, कर, निवेश, वित्तीय या किसी अन्य प्रकार की सलाह के रूप में व्याख्या करने का इरादा नहीं है और न ही इसकी व्याख्या की जानी चाहिए। यह महत्वपूर्ण है कि केवल उतना ही निवेश करें जितना आप खो सकते हैं और यदि आपको कोई संदेह हो तो स्वतंत्र वित्तीय सलाह लें। अधिक जानकारी के लिए, हम नियम और शर्तों के साथ-साथ जारीकर्ता या विज्ञापनदाता द्वारा प्रदान किए गए सहायता और समर्थन पृष्ठों का संदर्भ लेने का सुझाव देते हैं। MetaversePost सटीक, निष्पक्ष रिपोर्टिंग के लिए प्रतिबद्ध है, लेकिन बाज़ार की स्थितियाँ बिना सूचना के परिवर्तन के अधीन हैं।
के बारे में लेखक
दामिर टीम लीडर, उत्पाद प्रबंधक और संपादक हैं Metaverse Postएआई/एमएल, एजीआई, एलएलएम, मेटावर्स और जैसे विषयों को कवर करता है Web3-संबंधित क्षेत्रों। उनके लेख हर महीने दस लाख से अधिक उपयोगकर्ताओं को आकर्षित करते हैं। ऐसा प्रतीत होता है कि वह SEO और डिजिटल मार्केटिंग में 10 वर्षों के अनुभव वाला एक विशेषज्ञ है। दामिर का उल्लेख मैशबल, वायर्ड, में किया गया है Cointelegraph, द न्यू यॉर्कर, Inside.com, एंटरप्रेन्योर, BeInCrypto, और अन्य प्रकाशन। वह एक डिजिटल खानाबदोश के रूप में संयुक्त अरब अमीरात, तुर्की, रूस और सीआईएस के बीच यात्रा करता है। दामिर ने भौतिकी में स्नातक की डिग्री हासिल की, उनका मानना है कि इससे उन्हें इंटरनेट के लगातार बदलते परिदृश्य में सफल होने के लिए आवश्यक महत्वपूर्ण सोच कौशल प्राप्त हुआ है।
और अधिक लेख
दामिर टीम लीडर, उत्पाद प्रबंधक और संपादक हैं Metaverse Postएआई/एमएल, एजीआई, एलएलएम, मेटावर्स और जैसे विषयों को कवर करता है Web3-संबंधित क्षेत्रों। उनके लेख हर महीने दस लाख से अधिक उपयोगकर्ताओं को आकर्षित करते हैं। ऐसा प्रतीत होता है कि वह SEO और डिजिटल मार्केटिंग में 10 वर्षों के अनुभव वाला एक विशेषज्ञ है। दामिर का उल्लेख मैशबल, वायर्ड, में किया गया है Cointelegraph, द न्यू यॉर्कर, Inside.com, एंटरप्रेन्योर, BeInCrypto, और अन्य प्रकाशन। वह एक डिजिटल खानाबदोश के रूप में संयुक्त अरब अमीरात, तुर्की, रूस और सीआईएस के बीच यात्रा करता है। दामिर ने भौतिकी में स्नातक की डिग्री हासिल की, उनका मानना है कि इससे उन्हें इंटरनेट के लगातार बदलते परिदृश्य में सफल होने के लिए आवश्यक महत्वपूर्ण सोच कौशल प्राप्त हुआ है।






