



Sber AI ha presentat Kandinsky 2.0, el primer model de text a imatge per generar en més de 100 idiomes






En breu
Kandinsky 2.0, el primer model de difusió multilingüe, va ser creat i format per investigadors de Sber AI amb l'ajuda d'investigadors de l'AI Institute of Artificial Intelligence utilitzant el conjunt de dades combinat de 1 milions de parells de text-imatge de Sber AI i SberDevices.
La difusió està substituint cada cop més els GAN i els models autoregressius en una sèrie de tasques de processament d'imatges digitals. Això no és sorprenent perquè la difusió és més fàcil d'aprendre, no requereix una selecció complexa d'hiperparàmetres, optimització min-max i no pateix inestabilitat d'aprenentatge. I el més important, els models de difusió demostren resultats d'última generació en gairebé totes les tasques generatives: generació d'imatges per text, generació de so, vídeo i fins i tot. 3D.

Malauradament, la major part del treball en l'àmbit del text-to-something se centra només en l'anglès i el xinès. Per corregir aquesta injustícia, Sber AI decidit crear un model de difusió text a imatge multilingüe Kandinsky 2.0, que entén consultes en més de 100 idiomes. Cara abraçada ja ofereix Kandinsky 2.0. Els investigadors de SberAI i SberDevices ho han fet va col·laborar amb experts de l'AI Institute of Artificial Intelligence en aquest projecte.
Què és la difusió?
A l'article del 2015 Aprenentatge profund no supervisat mitjançant termodinàmica no equilibri, els models de difusió es van descriure per primera vegada com l'acte de barrejar una substància donant lloc a una difusió, que iguala la distribució. Tal com indica el títol de l'article, es van apropar a l'explicació dels models de difusió a través del marc de la termodinàmica.
En el cas de les imatges, aquest procés podria semblar, per exemple, a l'eliminació gradual del soroll gaussià de la imatge.
El paper Models de difusió Vèncer GANs on Image Synthesis, publicat el 2021, va ser el primer a demostrar la superioritat dels models de difusió sobre GANS. Els autors també van idear l'enfocament de control de primera generació (condicionament), que van anomenar guia del classificador. Aquest mètode crea objectes que s'ajusten a la classe prevista mitjançant degradats d'un classificador diferent (per exemple, gossos). Mitjançant el mecanisme Adaptive Group Norm, que implica la previsió de coeficients de normalització, es realitza el propi control.
Aquest article es pot veure com un punt d'inflexió en el camp de la IA generativa, que porta molts a recórrer a l'estudi de la difusió. Nous articles sobre text a vídeo, text a 3D, imatge pintar, generació d'àudio, difusió per superresolució, i fins i tot la generació de moviment va començar a aparèixer cada poques setmanes.
Difusió text a imatge
Com hem esmentat anteriorment, la reducció de soroll i l'eliminació de soroll són normalment els components principals dels processos de difusió en el context de les modalitats d'imatge, de manera que UNet i les seves moltes variacions s'utilitzen freqüentment com a arquitectura fonamental.
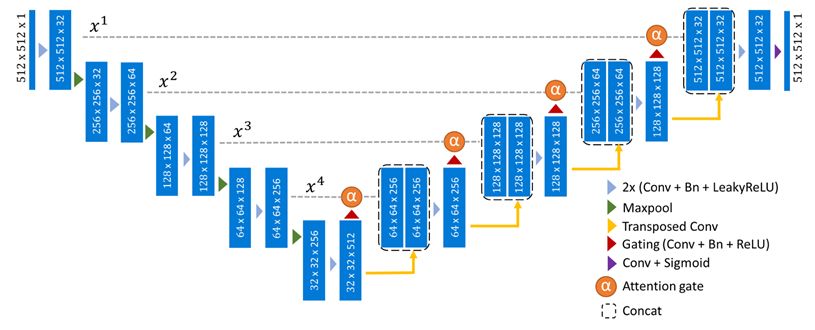
És fonamental que aquest text es tingui en compte d'alguna manera durant la generació per tal de crear una imatge a partir d'ell. Els autors de la OpenAI L'article sobre el model GLIDE va suggerir modificar l'enfocament d'orientació sense classificadors per al text.
L'ús de codificadors de text preirradiats congelats i el mecanisme de millora de la resolució en cascada en el futur van millorar considerablement la producció de text (Imatge). Va resultar que no hi havia necessitat d'entrenar la part de text models de text a imatge ja que l'ús del T5-xxl congelat va donar lloc a una millora considerable de la qualitat de la imatge i la comprensió del text i va utilitzar molts menys recursos d'entrenament.
Els autors d’un Difusió latent L'article va demostrar que el component d'imatge en realitat no requereix formació (almenys no completament). L'aprenentatge procedirà encara més ràpidament si utilitzem un potent codificador automàtic d'imatges (VQ-VAE o KL-VAE) com a descodificador visual i intentem generar incrustacions a partir del seu espai latent per difusió en lloc de la pròpia imatge. Aquesta metodologia també és la base de la recentment llançada Stable Diffusion model.
Model Kandinsky 2.0 AI
Amb algunes millores clau, Kandinsky 2.0 es basa en una tècnica de difusió latent millorada (no fem imatges, sinó els seus vectors latents):
- S'han utilitzat dos codificadors de text multilingües i han concatenat les seves incrustacions.
- S'ha afegit UNet (1.2 milions de paràmetres).
- Procediment de mostreig llindar dinàmic.
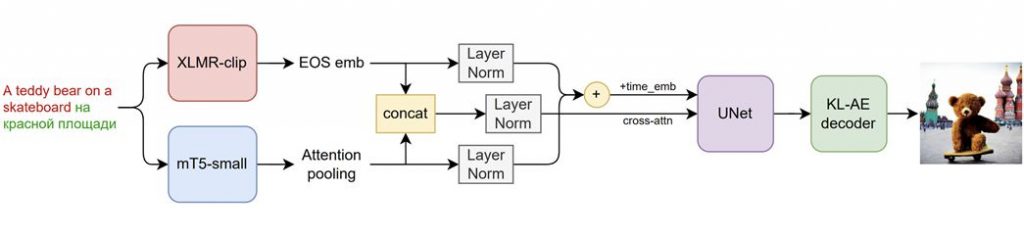
Els investigadors van emprar dos codificadors multilingües simultàniament (XLMR-clip i mT5-small) per tal de model realment multilingüe. Per tant, a més de l'anglès, el rus, el francès i l'alemany, el model també pot entendre idiomes com el mongol, l'hebreu i el farsi. L'IA sap un total de 101 idiomes. Per què es va decidir codificar el text utilitzant dos models simultàniament? Com que XLMR-clip ha vist imatges i proporciona incrustacions properes per a diversos idiomes, i mT5-small és capaç d'entendre textos complexos, aquests models tenen característiques diferents però crucials. Com que tots dos models només tenen un nombre reduït de paràmetres (560M i 146M), tal com demostren les nostres proves preliminars, es va decidir utilitzar dos codificadors simultàniament.
Imatges acabades de generar pel model Kandinsky 2.0 AI a continuació:




Com es va fer la formació del model Kandinsky 2.0?
Es van utilitzar superordinadors Christofari per a la formació a la plataforma ML Space. Necessitava 196 targetes NVIDIA A100, cadascuna amb 80 GB de RAM. Va trigar 14 dies, o 65,856 hores de GPU, per completar la formació. L'anàlisi va trigar cinc dies amb una resolució de 256 × 256, seguits de sis dies amb una resolució de 512 × 512, i després tres dies addicionals amb les dades més pures.
Com a dades d'entrenament, es van combinar molts conjunts de dades que s'havien filtrat prèviament per a marques d'aigua, baixa resolució i baixa adherència a la descripció del text mesurada per la mètrica de puntuació CLIP.
Generació multilingüe
Kandinsky 2.0 és el primer model multilingüe per crear imatges a partir de paraules, la qual cosa ens ofereix la primera oportunitat d'avaluar els canvis lingüístics i visuals de les cultures lingüístiques. A continuació es mostren els resultats de traduir la mateixa consulta a diversos idiomes. Per exemple, només els homes blancs apareixen als resultats de la generació per a la consulta russa "una persona amb estudis superiors", mentre que els resultats de la traducció francesa, "Photo d'une personne diplômée de l'enseignement supérieur", són més diversificats. M'agradaria assenyalar que les persones dolentes amb estudis superiors només estan presents a l'edició en rus.



Tot i que encara hi ha un munt de proves amb grans models lingüístics i diferents mètodes del procés de difusió previst, ja podem afirmar amb confiança que Kandinsky 2.0 és el primer model de difusió totalment multilingüe! A la Lloc web de FusionBrain i Google Colab, podeu veure exemples dels seus dibuixos.
Llegeix més sobre AI:
renúncia
En línia amb la Directrius del projecte Trust, si us plau, tingueu en compte que la informació proporcionada en aquesta pàgina no pretén ni s'ha d'interpretar com a assessorament legal, fiscal, d'inversió, financer o de cap altra forma. És important invertir només el que et pots permetre perdre i buscar assessorament financer independent si tens dubtes. Per obtenir més informació, us suggerim que feu referència als termes i condicions, així com a les pàgines d'ajuda i assistència proporcionades per l'emissor o l'anunciant. MetaversePost es compromet a fer informes precisos i imparcials, però les condicions del mercat estan subjectes a canvis sense previ avís.
About The Autor
Damir és el líder d'equip, cap de producte i editor de Metaverse Post, que cobreix temes com AI/ML, AGI, LLMs, Metaverse i Web3-camps relacionats. Els seus articles atrauen una audiència massiva de més d'un milió d'usuaris cada mes. Sembla ser un expert amb 10 anys d'experiència en SEO i màrqueting digital. Damir ha estat esmentat a Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto i altres publicacions. Viatja entre els Emirats Àrabs Units, Turquia, Rússia i la CEI com a nòmada digital. Damir va obtenir una llicenciatura en física, que creu que li ha donat les habilitats de pensament crític necessàries per tenir èxit en el paisatge en constant canvi d'Internet.
més articles
Damir és el líder d'equip, cap de producte i editor de Metaverse Post, que cobreix temes com AI/ML, AGI, LLMs, Metaverse i Web3-camps relacionats. Els seus articles atrauen una audiència massiva de més d'un milió d'usuaris cada mes. Sembla ser un expert amb 10 anys d'experiència en SEO i màrqueting digital. Damir ha estat esmentat a Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto i altres publicacions. Viatja entre els Emirats Àrabs Units, Turquia, Rússia i la CEI com a nòmada digital. Damir va obtenir una llicenciatura en física, que creu que li ha donat les habilitats de pensament crític necessàries per tenir èxit en el paisatge en constant canvi d'Internet.






