



Stability AI'S Stable Diffusion L'algoritme 2 és finalment públic: nou model depth2img, escalador de super-resolució, sense contingut per a adults







En breu
Stable Diffusion El model 2.0 és més ràpid, de codi obert, escalable i més robust que l'anterior
Stable Diffusion està preparat per a la GPU amb noves funcions per a la representació en temps real
Guiada en profunditat stable diffusion model – Imatge a imatge amb noves idees per a aplicacions creatives
Stability AI té alliberat un nou article al seu blog sobre Stable Diffusion 2. En ell, Stability AI proposa un nou algorisme que és més eficient i robust que l'anterior alhora que el compara amb altres mètodes d'última generació.

Original de CompVis Stable Diffusion Model V1 revolucionat la naturalesa del codi obert Models d'IA i va produir centenars de models i avenços diferents arreu del món. Va veure una de les pujades més ràpides a 10,000 estrelles de Github, acumulant-ne 33,000 en menys de dos mesos, més ràpid que més programes a Github.
L'original Stable Diffusion El llançament V1 va ser liderat per l'equip dinàmic de Robin Rombach (Stability AI) i Patrick Esser (Runway ML) del Grup CompVis de LMU Munich, dirigit pel Prof. Dr. Björn Ommer. Es van basar en el treball anterior del laboratori amb Latent Models de difusió i va rebre el suport crític de LAION i Eleuther AI.


El que fa Stable Diffusion v1 diferent de Stable Diffusion v2?
Stable Diffusion 2.0 inclou una sèrie de millores i funcions importants respecte a la versió anterior, així que fem-hi una ullada.
El Stable Diffusion La versió 2.0 inclou models robustos de text a imatge entrenats amb un nou codificador de text nou (OpenCLIP) desenvolupat per LAION amb l'assistència de Stability AI, que millora significativament la qualitat del imatges generades respecte a les versions anteriors de la V1. Els models de text a imatge d'aquesta versió poden produir imatges amb resolucions predeterminades de 512 × 512 píxels i 768 × 768 píxels.
Aquests models s'entrenen mitjançant un subconjunt estètic del conjunt de dades LAION-5B generat per Stability AIl'equip DeepFloyd de, que després es filtra per excloure contingut per a adults mitjançant el filtre NSFW de LAION.
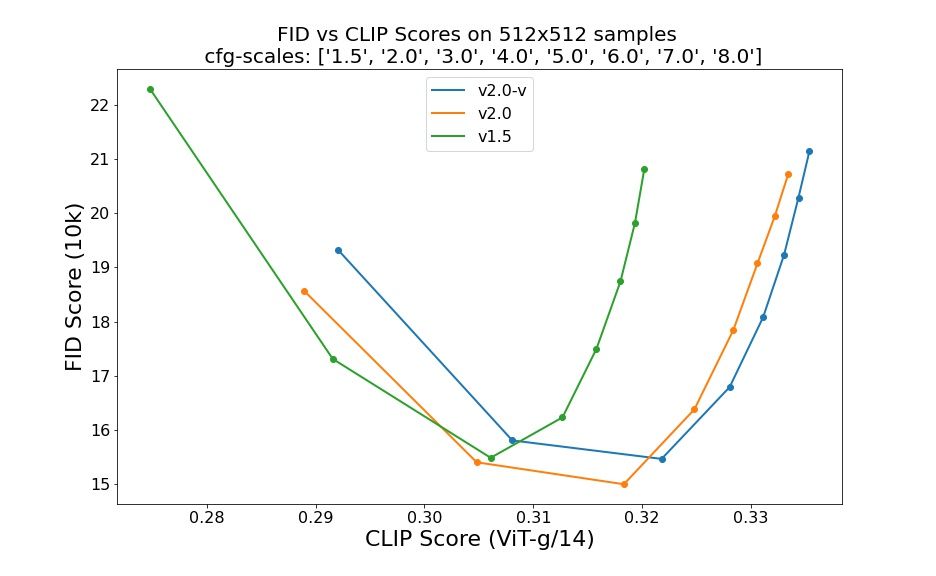
Les avaluacions que utilitzen 50 passos de mostra DDIM, 50 escales de guia sense classificadors i 1.5, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0 i 8.0 indiquen millores relatives dels punts de control:
Stable Diffusion 2.0 ara incorpora un model Upscaler Diffusion, que augmenta la resolució de la imatge en un factor de quatre. Un exemple del nostre model ampliació de l'escala A continuació es mostra una imatge generada de baixa qualitat (128×128) en una imatge de resolució més alta (512×512). Stable Diffusion 2.0, quan es combina amb els nostres models de text a imatge, ara pot generar imatges amb resolucions de 2048 × 2048 o superior.

La nova profunditat guiada stable diffusion model, depth2img, amplia la funció anterior d'imatge a imatge de la V1 amb possibilitats creatives completament noves. Depth2img determina la profunditat d'una imatge d'entrada (utilitzant un model existent) i després genera nous imatges basat tant en el text com en la informació de profunditat. Depth-to-Image pot proporcionar una gran quantitat d'aplicacions creatives noves, oferint canvis que semblen significativament diferents de l'original tot conservant la coherència i la profunditat de la imatge.
Què hi ha de nou Stable Diffusion 2?
- El nou stable diffusion model ofereix una resolució de 768×768.
- L'U-Net té la mateixa quantitat de paràmetres que la versió 1.5, però s'entrena des de zero i utilitza OpenCLIP-ViT/H com a codificador de text. L'anomenat model de predicció v és SD 2.0-v.
- El model esmentat es va ajustar a partir de la base SD 2.0, que també està disponible i es va entrenar com a model típic de predicció de soroll en imatges de 512 × 512.
- S'ha afegit un model de difusió guiada per text latent amb escala x4.
- Base refinada SD 2.0 guiada per profunditat stable diffusion model. El model es pot utilitzar per preservar l'estructura img2img i síntesi condicional de forma i està condicionat a les estimacions de profunditat monocular deduïdes per MiDaS.
- Un model millorat de pintura guiada per text construït sobre la base SD 2.0.
Els desenvolupadors van treballar dur, igual que la iteració inicial de Stable Diffusion, per optimitzar el model perquè s'executi en una única GPU; volien fer-lo accessible a tantes persones com fos possible des del principi. Ja han vist què passa quan milions de persones posen a les seves mans aquests models i col·laboren per construir coses absolutament notables. Aquest és el poder del codi obert: aprofitar el gran potencial de milions de persones amb talent que potser no tenen els recursos per formar un model d'avantguarda però tenen la capacitat de fer coses increïbles amb un.

Aquesta nova actualització, combinada amb noves funcions potents com depth2img i una millor capacitat d'augment de resolució, servirà com a base per a una gran quantitat d'aplicacions noves i permetrà una explosió de nou potencial creatiu.
Llegiu més sobre Stable Diffusion:
renúncia
En línia amb la Directrius del projecte Trust, si us plau, tingueu en compte que la informació proporcionada en aquesta pàgina no pretén ni s'ha d'interpretar com a assessorament legal, fiscal, d'inversió, financer o de cap altra forma. És important invertir només el que et pots permetre perdre i buscar assessorament financer independent si tens dubtes. Per obtenir més informació, us suggerim que feu referència als termes i condicions, així com a les pàgines d'ajuda i assistència proporcionades per l'emissor o l'anunciant. MetaversePost es compromet a fer informes precisos i imparcials, però les condicions del mercat estan subjectes a canvis sense previ avís.
About The Autor
Damir és el líder d'equip, cap de producte i editor de Metaverse Post, que cobreix temes com AI/ML, AGI, LLMs, Metaverse i Web3-camps relacionats. Els seus articles atrauen una audiència massiva de més d'un milió d'usuaris cada mes. Sembla ser un expert amb 10 anys d'experiència en SEO i màrqueting digital. Damir ha estat esmentat a Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto i altres publicacions. Viatja entre els Emirats Àrabs Units, Turquia, Rússia i la CEI com a nòmada digital. Damir va obtenir una llicenciatura en física, que creu que li ha donat les habilitats de pensament crític necessàries per tenir èxit en el paisatge en constant canvi d'Internet.
més articles
Damir és el líder d'equip, cap de producte i editor de Metaverse Post, que cobreix temes com AI/ML, AGI, LLMs, Metaverse i Web3-camps relacionats. Els seus articles atrauen una audiència massiva de més d'un milió d'usuaris cada mes. Sembla ser un expert amb 10 anys d'experiència en SEO i màrqueting digital. Damir ha estat esmentat a Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto i altres publicacions. Viatja entre els Emirats Àrabs Units, Turquia, Rússia i la CEI com a nòmada digital. Damir va obtenir una llicenciatura en física, que creu que li ha donat les habilitats de pensament crític necessàries per tenir èxit en el paisatge en constant canvi d'Internet.






