



शीर्ष 30+ एआई में ट्रांसफार्मर मॉडल: वे क्या हैं और कैसे काम करते हैं







हाल के महीनों में, एआई में कई ट्रांसफॉर्मर मॉडल सामने आए हैं, जिनमें से प्रत्येक अद्वितीय और कभी-कभी मनोरंजक नामों के साथ है। हालाँकि, ये नाम इस बारे में अधिक जानकारी प्रदान नहीं कर सकते हैं कि ये मॉडल वास्तव में क्या करते हैं। इस लेख का उद्देश्य सबसे लोकप्रिय ट्रांसफार्मर मॉडल की एक व्यापक और सीधी सूची प्रदान करना है। यह इन मॉडलों को वर्गीकृत करेगा और ट्रांसफॉर्मर परिवार के भीतर महत्वपूर्ण पहलुओं और नवाचारों को भी पेश करेगा। शीर्ष सूची शामिल होगी मॉडलों को प्रशिक्षित किया स्व-पर्यवेक्षित शिक्षण के माध्यम से, जैसे BERT या GPT-3, साथ ही ऐसे मॉडल जो मानवीय भागीदारी के साथ अतिरिक्त प्रशिक्षण से गुजरते हैं, जैसे कि निर्देशGPT द्वारा उपयोग किया गया मॉडल ChatGPT.

| प्रो टिप्स |
|---|
| यह गाइड शुरुआती से उन्नत शिक्षार्थियों के लिए शीघ्र इंजीनियरिंग में व्यापक ज्ञान और व्यावहारिक कौशल प्रदान करने के लिए डिज़ाइन किया गया है। |
| कई कोर्स हैं एआई और इससे संबंधित तकनीकों के बारे में अधिक जानने के इच्छुक व्यक्तियों के लिए उपलब्ध है। |
| पर एक नज़र रखना शीर्ष 10+ एआई त्वरक जिनसे प्रदर्शन के मामले में बाजार का नेतृत्व करने की उम्मीद है। |
एआई में ट्रांसफॉर्मर क्या हैं?
ट्रांसफॉर्मर एक प्रकार के गहन शिक्षण मॉडल हैं जिन्हें "" नामक एक शोध पत्र में पेश किया गया था।ध्यान आप सभी की जरूरत है” 2017 में Google शोधकर्ताओं द्वारा। इस पेपर ने केवल पांच वर्षों में 38,000 से अधिक उद्धरणों को जमा करते हुए अत्यधिक मान्यता प्राप्त की है।
मूल ट्रांसफॉर्मर आर्किटेक्चर एनकोडर-डिकोडर मॉडल का एक विशिष्ट रूप है, जिसने इसकी शुरूआत से पहले लोकप्रियता हासिल की थी। ये मॉडल मुख्य रूप से निर्भर थे एलएसटीएम और आवर्ती तंत्रिका नेटवर्क के अन्य रूपों (आरएनएन), ध्यान केवल उपयोग किए जाने वाले तंत्रों में से एक है। हालांकि, ट्रांसफॉर्मर पेपर ने एक क्रांतिकारी विचार का प्रस्ताव दिया कि इनपुट और आउटपुट के बीच निर्भरता स्थापित करने के लिए ध्यान एकमात्र तंत्र के रूप में काम कर सकता है।
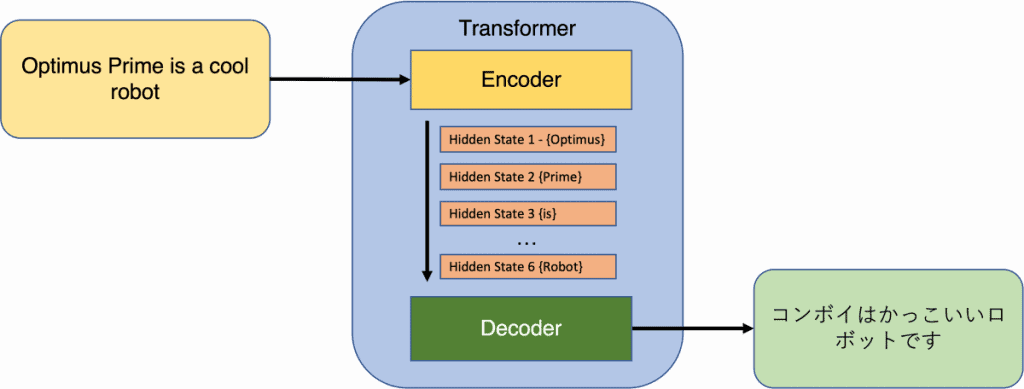
ट्रांसफॉर्मर के संदर्भ में, इनपुट में टोकन का एक क्रम होता है, जो प्राकृतिक भाषा प्रसंस्करण में शब्द या उपशब्द हो सकते हैं (एनएलपी). आउट-ऑफ-वोकैबुलरी शब्दों के मुद्दे को संबोधित करने के लिए एनएलपी मॉडल में आमतौर पर उपशब्दों का उपयोग किया जाता है। एनकोडर का आउटपुट प्रत्येक टोकन के लिए एक निश्चित-आयामी प्रतिनिधित्व का उत्पादन करता है, साथ ही पूरे अनुक्रम के लिए एक अलग एम्बेडिंग के साथ। डिकोडर एनकोडर के आउटपुट को लेता है और इसके आउटपुट के रूप में टोकन का एक क्रम उत्पन्न करता है।
ट्रांसफॉर्मर पेपर के प्रकाशन के बाद से लोकप्रिय मॉडल जैसे बर्ट और GPT एनकोडर या डिकोडर घटकों का उपयोग करके, मूल वास्तुकला के पहलुओं को अपनाया है। इन मॉडलों के बीच मुख्य समानता परत वास्तुकला में निहित है, जिसमें आत्म-ध्यान तंत्र और फ़ीड-फ़ॉरवर्ड परतें शामिल हैं। ट्रांसफॉर्मर में, प्रत्येक इनपुट टोकन इनपुट अनुक्रम में हर दूसरे टोकन के साथ प्रत्यक्ष निर्भरता बनाए रखते हुए परतों के माध्यम से अपना स्वयं का पथ पार करता है। यह अनूठी सुविधा प्रासंगिक टोकन अभ्यावेदन की समानांतर और कुशल गणना की अनुमति देती है, यह क्षमता आरएनएन जैसे अनुक्रमिक मॉडल के साथ संभव नहीं है।
हालांकि यह लेख केवल ट्रांसफॉर्मर आर्किटेक्चर की सतह को खंगालता है, लेकिन यह इसके मूलभूत पहलुओं की एक झलक प्रदान करता है। अधिक व्यापक समझ के लिए, हम मूल शोध पत्र या द इलस्ट्रेटेड ट्रांसफॉर्मर पोस्ट को संदर्भित करने की सलाह देते हैं।
AI में एनकोडर और डिकोडर क्या हैं?
कल्पना कीजिए कि आपके पास दो मॉडल हैं, एक एनकोडर और एक डिकोडर, एक साथ काम कर एक टीम की तरह। एनकोडर एक इनपुट लेता है और इसे एक निश्चित-लंबाई वाले वेक्टर में बदल देता है। फिर, डिकोडर उस वेक्टर को लेता है और इसे आउटपुट अनुक्रम में बदल देता है। यह सुनिश्चित करने के लिए इन मॉडलों को एक साथ प्रशिक्षित किया जाता है कि आउटपुट इनपुट से यथासंभव निकटता से मेल खाता है।
एनकोडर और डिकोडर दोनों में कई परतें होती हैं। एनकोडर में प्रत्येक परत में दो उप परतें होती हैं: एक मल्टी-हेड सेल्फ-अटेंशन लेयर और एक साधारण फीड फॉरवर्ड नेटवर्क। स्व-ध्यान परत इनपुट में प्रत्येक टोकन को अन्य सभी टोकन के साथ संबंधों को समझने में मदद करती है। सीखने की प्रक्रिया को सुचारू बनाने के लिए इन उप-परतों में एक अवशिष्ट संबंध और एक परत सामान्यीकरण भी होता है।
डिकोडर का मल्टी-हेड आत्म-ध्यान परत एनकोडर में एक से थोड़ा अलग काम करता है। यह टोकन को उस टोकन के दाईं ओर मास्क करता है जिस पर वह ध्यान केंद्रित कर रहा है। यह सुनिश्चित करता है कि डिकोडर केवल उन टोकन को देखता है जो भविष्यवाणी करने की कोशिश कर रहे टोकन से पहले आते हैं। यह नकाबपोश मल्टी-हेड ध्यान डिकोडर को सटीक भविष्यवाणियां करने में मदद करता है। इसके अतिरिक्त, डिकोडर में एक और सबलेयर शामिल है, जो एनकोडर से सभी आउटपुट पर एक मल्टी-हेड ध्यान परत है।
यह ध्यान रखना महत्वपूर्ण है कि इन विशिष्ट विवरणों को ट्रांसफॉर्मर मॉडल के विभिन्न रूपों में संशोधित किया गया है। BERT और जैसे मॉडल GPT, उदाहरण के लिए, मूल आर्किटेक्चर के एनकोडर या डिकोडर पहलू पर आधारित हैं।
एआई में अटेंशन लेयर्स क्या हैं?
मॉडल आर्किटेक्चर में हमने पहले चर्चा की, मल्टी-हेड ध्यान परतें विशेष तत्व हैं जो इसे शक्तिशाली बनाती हैं। लेकिन वास्तव में ध्यान क्या है ? इसे एक ऐसे फंक्शन के रूप में सोचें जो एक प्रश्न को सूचना के एक सेट पर मैप करता है और एक आउटपुट देता है। इनपुट में प्रत्येक टोकन में एक क्वेरी, कुंजी और मूल्य जुड़ा होता है। प्रत्येक टोकन के आउटपुट प्रतिनिधित्व की गणना मानों का भारित योग करके की जाती है, जहाँ प्रत्येक मान के लिए वजन यह निर्धारित करता है कि यह क्वेरी से कितनी अच्छी तरह मेल खाता है।
ट्रांसफॉर्मर इन भारों की गणना करने के लिए स्केल किए गए डॉट उत्पाद नामक संगतता फ़ंक्शन का उपयोग करते हैं। ट्रांसफॉर्मर में ध्यान देने के बारे में दिलचस्प बात यह है कि प्रत्येक टोकन अपने स्वयं के गणना पथ से गुजरता है, जिससे इनपुट अनुक्रम में सभी टोकन की समानांतर गणना की अनुमति मिलती है। यह केवल एकाधिक ध्यान ब्लॉक है जो स्वतंत्र रूप से प्रत्येक टोकन के लिए अभ्यावेदन की गणना करता है। टोकन के अंतिम प्रतिनिधित्व को बनाने के लिए इन अभ्यावेदन को जोड़ा जाता है।
अन्य प्रकार के नेटवर्क जैसे आवर्तक और की तुलना में दृढ़ नेटवर्क, ध्यान परतों के कुछ लाभ हैं। वे कम्प्यूटेशनल रूप से कुशल हैं, जिसका अर्थ है कि वे सूचनाओं को जल्दी से संसाधित कर सकते हैं। उनके पास उच्च कनेक्टिविटी भी है, जो अनुक्रमों में दीर्घकालिक संबंधों को कैप्चर करने में सहायक है।
एआई में फाइन-ट्यून मॉडल क्या हैं?
फाउंडेशन मॉडल शक्तिशाली मॉडल हैं जिन्हें बड़ी मात्रा में सामान्य डेटा पर प्रशिक्षित किया जाता है। फिर उन्हें छोटे सेट पर प्रशिक्षित करके विशिष्ट कार्यों के लिए अनुकूलित या ठीक किया जा सकता है लक्ष्य-विशिष्ट डेटा. द्वारा लोकप्रिय यह दृष्टिकोण BERT पेपर, भाषा से संबंधित मशीन सीखने के कार्यों में ट्रांसफार्मर-आधारित मॉडल के प्रभुत्व का नेतृत्व किया है।
बीईआरटी जैसे मॉडल के मामले में, वे इनपुट टोकन के प्रतिनिधित्व का उत्पादन करते हैं लेकिन विशिष्ट कार्यों को स्वयं पूरा नहीं करते हैं। उन्हें उपयोगी बनाने के लिए, अतिरिक्त तंत्रिका परतें शीर्ष पर जोड़े जाते हैं और मॉडल को शुरू से अंत तक प्रशिक्षित किया जाता है, इस प्रक्रिया को फ़ाइन-ट्यूनिंग के रूप में जाना जाता है। हालाँकि, साथ जेनेरिक मॉडल पसंद GPT, दृष्टिकोण थोड़ा अलग है. GPT एक डिकोडर भाषा मॉडल है जिसे एक वाक्य में अगले शब्द की भविष्यवाणी करने के लिए प्रशिक्षित किया जाता है। विशाल मात्रा में वेब डेटा पर प्रशिक्षण द्वारा, GPT इनपुट प्रश्नों या संकेतों के आधार पर उचित आउटपुट उत्पन्न कर सकता है।
बनाने के लिए GPT अधिक सहायताकारक, OpenAI शोधकर्ताओं ने विकसित किया हिदायतGPT, जिसे मानवीय निर्देशों का पालन करने के लिए प्रशिक्षित किया जाता है। यह फाइन-ट्यूनिंग द्वारा हासिल किया गया है GPT विभिन्न कार्यों से मानव-लेबल डेटा का उपयोग करना। हिदायतGPT कई प्रकार के कार्य करने में सक्षम है और इसका उपयोग लोकप्रिय इंजनों द्वारा किया जाता है ChatGPT.
फ़ाइन-ट्यूनिंग का उपयोग अनुकूलित किए गए फ़ाउंडेशन मॉडल के वेरिएंट बनाने के लिए भी किया जा सकता है विशिष्ट उद्देश्य भाषा मॉडलिंग से परे। उदाहरण के लिए, पाठ वर्गीकरण और खोज पुनर्प्राप्ति जैसे सिमेंटिक-संबंधित कार्यों के लिए ठीक-ठीक मॉडल हैं। इसके अतिरिक्त, बहु-कार्य के भीतर ट्रांसफॉर्मर एन्कोडर्स को सफलतापूर्वक ठीक किया गया है सीखने के ढांचे एक साझा मॉडल का उपयोग करके कई सिमेंटिक कार्य करने के लिए।
आज, फ़ाइन-ट्यूनिंग का उपयोग फ़ाउंडेशन मॉडल के संस्करण बनाने के लिए किया जाता है जिनका उपयोग बड़ी संख्या में उपयोगकर्ताओं द्वारा किया जा सकता है। इस प्रक्रिया में इनपुट पर प्रतिक्रियाएँ उत्पन्न करना शामिल है संकेत देता है और मनुष्यों से परिणामों को रैंक करवाता है. इस रैंकिंग का उपयोग प्रशिक्षित करने के लिए किया जाता है इनाम मॉडल, जो प्रत्येक आउटपुट को स्कोर प्रदान करता है। मानव प्रतिक्रिया के साथ सुदृढीकरण सीखना फिर मॉडल को और प्रशिक्षित करने के लिए नियोजित किया जाता है।
ट्रांसफॉर्मर एआई का भविष्य क्यों हैं?
ट्रांसफॉर्मर, एक प्रकार का शक्तिशाली मॉडल, पहली बार भाषा अनुवाद के क्षेत्र में प्रदर्शित किया गया था। हालांकि, शोधकर्ताओं ने जल्दी से महसूस किया कि ट्रांसफॉर्मर का उपयोग भाषा से संबंधित विभिन्न कार्यों के लिए किया जा सकता है, उन्हें बड़ी मात्रा में बिना लेबल वाले पाठ पर प्रशिक्षित किया जा सकता है और फिर उन्हें लेबल किए गए डेटा के एक छोटे सेट पर ठीक किया जा सकता है। इस दृष्टिकोण ने ट्रांसफॉर्मर्स को भाषा के बारे में महत्वपूर्ण ज्ञान प्राप्त करने की अनुमति दी।
ट्रांसफॉर्मर आर्किटेक्चर, मूल रूप से भाषा कार्यों के लिए डिज़ाइन किया गया है, जैसे अन्य अनुप्रयोगों पर भी लागू किया गया है चित्र उत्पन्न करना, ऑडियो, संगीत और यहां तक कि क्रियाएं भी। इसने ट्रांसफॉर्मर्स को जनरेटिव एआई के क्षेत्र में एक प्रमुख घटक बना दिया है, जो समाज के विभिन्न पहलुओं को बदल रहा है।
उपकरण और ढांचे की उपलब्धता जैसे पायटॉर्च और TensorFlow ट्रांसफार्मर मॉडल को व्यापक रूप से अपनाने में महत्वपूर्ण भूमिका निभाई है। हगिंगफेस जैसी कंपनियों ने अपना निर्माण किया है विचार के आसपास व्यापार ओपन-सोर्स ट्रांसफॉर्मर लाइब्रेरीज़ और एनवीआईडीआईए के हॉपर टेन्सर कोर जैसे विशेष हार्डवेयर के व्यावसायीकरण ने इन मॉडलों के प्रशिक्षण और अनुमान की गति को और तेज कर दिया है।
ट्रांसफार्मर का एक उल्लेखनीय अनुप्रयोग है ChatGPT, द्वारा जारी एक चैटबॉट OpenAI. यह अविश्वसनीय रूप से लोकप्रिय हो गया और कुछ ही समय में लाखों उपयोगकर्ताओं तक पहुंच गया। OpenAI की रिलीज की घोषणा भी कर दी है GPT-4जैसे कार्यों में मानव जैसा प्रदर्शन प्राप्त करने में सक्षम एक अधिक शक्तिशाली संस्करण चिकित्सा और कानूनी परीक्षा.
एआई के क्षेत्र में ट्रांसफॉर्मर का प्रभाव और उनके अनुप्रयोगों की विस्तृत श्रृंखला निर्विवाद है। उन्होंने है रास्ता बदल दिया हम भाषा से संबंधित कार्य करते हैं और जनरेटिव एआई में नई प्रगति का मार्ग प्रशस्त कर रहे हैं।
प्रीट्रेनिंग आर्किटेक्चर के 3 प्रकार
ट्रांसफॉर्मर आर्किटेक्चर, मूल रूप से एनकोडर और डिकोडर से मिलकर, विशिष्ट आवश्यकताओं के आधार पर विभिन्न भिन्नताओं को शामिल करने के लिए विकसित हुआ है। आइए इन विविधताओं को सरल शब्दों में तोड़ें।
- एनकोडर प्रीट्रेनिंग: ये मॉडल पूरे वाक्यों या गद्यांश को समझने पर ध्यान केंद्रित करते हैं। पूर्व-प्रशिक्षण के दौरान, एनकोडर का उपयोग इनपुट वाक्य में नकाबपोश टोकन के पुनर्निर्माण के लिए किया जाता है। इससे मॉडल को समग्र संदर्भ को समझने में मदद मिलती है। इस तरह के मॉडल टेक्स्ट क्लासिफिकेशन, एंटेलमेंट और एक्सट्रैक्टिव क्वेश्चन आंसरिंग जैसे कार्यों के लिए उपयोगी होते हैं।
- डिकोडर प्रीट्रेनिंग: डिकोडर मॉडल को टोकन के पिछले अनुक्रम के आधार पर अगला टोकन उत्पन्न करने के लिए प्रशिक्षित किया जाता है। उन्हें ऑटो-रिग्रेसिव लैंग्वेज मॉडल के रूप में जाना जाता है। डिकोडर में आत्म-ध्यान परत केवल वाक्य में दिए गए टोकन से पहले टोकन तक पहुंच सकती है। ये मॉडल टेक्स्ट जनरेशन वाले कार्यों के लिए आदर्श हैं।
- ट्रांसफार्मर (एनकोडर-डिकोडर) प्रीट्रेनिंग: यह भिन्नता एनकोडर और डिकोडर दोनों घटकों को जोड़ती है। एनकोडर की आत्म-ध्यान परत सभी इनपुट टोकन तक पहुंच सकती है, जबकि डिकोडर की आत्म-ध्यान परत केवल दिए गए टोकन से पहले टोकन तक पहुंच सकती है। यह आर्किटेक्चर डिकोडर को एनकोडर द्वारा सीखे गए अभ्यावेदन का उपयोग करने में सक्षम बनाता है। एनकोडर-डिकोडर मॉडल सारांशीकरण, अनुवाद, या जनरेटिव प्रश्न उत्तर देने जैसे कार्यों के लिए उपयुक्त हैं।
पूर्व-प्रशिक्षण उद्देश्यों में denoising या कारणात्मक भाषा मॉडलिंग शामिल हो सकते हैं। एनकोडर-डिकोडर मॉडल के लिए ये उद्देश्य एनकोडर-ओनली या डिकोडर-ओनली मॉडल की तुलना में अधिक जटिल हैं। मॉडल के फोकस के आधार पर ट्रांसफॉर्मर आर्किटेक्चर में अलग-अलग बदलाव होते हैं। चाहे वह पूर्ण वाक्यों को समझना हो, पाठ उत्पन्न करना हो, या विभिन्न कार्यों के लिए दोनों का संयोजन करना हो, ट्रांसफॉर्मर विभिन्न भाषा-संबंधी चुनौतियों को संबोधित करने में लचीलापन प्रदान करते हैं।
पूर्व प्रशिक्षित मॉडल के लिए 8 प्रकार के कार्य
किसी मॉडल को प्रशिक्षित करते समय, हमें उसे सीखने के लिए एक कार्य या उद्देश्य देने की आवश्यकता होती है। प्राकृतिक भाषा प्रसंस्करण (एनएलपी) में विभिन्न कार्य हैं जिनका उपयोग पूर्व-प्रशिक्षण मॉडल के लिए किया जा सकता है। आइए इनमें से कुछ कार्यों को सरल शब्दों में विभाजित करें:
- भाषा मॉडलिंग (एलएम): मॉडल एक वाक्य में अगले टोकन की भविष्यवाणी करता है। यह संदर्भ को समझना और सुसंगत वाक्य उत्पन्न करना सीखता है।
- कारणात्मक भाषा मॉडलिंग: मॉडल बाएं से दाएं क्रम का पालन करते हुए पाठ अनुक्रम में अगले टोकन की भविष्यवाणी करता है। यह एक कहानी कहने वाले मॉडल की तरह है जो एक समय में एक शब्द उत्पन्न करता है।
- उपसर्ग भाषा मॉडलिंग: मॉडल एक 'उपसर्ग' खंड को मुख्य अनुक्रम से अलग करता है। यह उपसर्ग के भीतर किसी भी टोकन में भाग ले सकता है, और उसके बाद शेष अनुक्रम को स्वचालित रूप से उत्पन्न करता है।
- नकाबपोश भाषा मॉडलिंग (MLM): इनपुट वाक्यों में कुछ टोकन नकाबपोश होते हैं, और मॉडल आसपास के संदर्भ के आधार पर लापता टोकन की भविष्यवाणी करता है। यह रिक्त स्थान भरना सीखता है।
- अनुमत भाषा मॉडलिंग (पीएलएम): मॉडल इनपुट अनुक्रम के यादृच्छिक क्रमपरिवर्तन के आधार पर अगले टोकन की भविष्यवाणी करता है। यह टोकन के विभिन्न आदेशों को संभालना सीखता है।
- Denoising Autoencoder (DAE): मॉडल आंशिक रूप से दूषित इनपुट लेता है और मूल, अविकृत इनपुट को पुनर्प्राप्त करने का लक्ष्य रखता है। यह शोर या पाठ के लापता भागों को संभालना सीखता है।
- रिप्लेस्ड टोकन डिटेक्शन (RTD): मॉडल यह पता लगाता है कि टोकन मूल पाठ से आया है या उत्पन्न संस्करण से। यह बदले गए या हेरफेर किए गए टोकन की पहचान करना सीखता है।
- नेक्स्ट सेंटेंस प्रेडिक्शन (NSP): मॉडल यह अंतर करना सीखता है कि क्या दो इनपुट वाक्य प्रशिक्षण डेटा से निरंतर खंड हैं। यह वाक्यों के बीच संबंध को समझता है।
ये कार्य मॉडल को भाषा की संरचना और अर्थ सीखने में मदद करते हैं। इन कार्यों के पूर्व प्रशिक्षण से, मॉडल विशिष्ट अनुप्रयोगों के लिए परिष्कृत होने से पहले भाषा की अच्छी समझ प्राप्त करते हैं।
एआई में शीर्ष 30+ ट्रांसफॉर्मर
| नाम | प्रीट्रेनिंग आर्किटेक्चर | कार्य | आवेदन | द्वारा विकसित |
|---|---|---|---|---|
| एलबर्ट | एनकोडर | एमएलएम/एनएसपी | बर्ट के समान | गूगल |
| उसकी ऊन का कपड़ा | विकोडक | LM | पाठ निर्माण और वर्गीकरण कार्य | स्टैनफोर्ड |
| अल्फाफोल्ड | एनकोडर | प्रोटीन तह भविष्यवाणी | प्रोटीन की तह | दीप मन |
| मानव विज्ञान सहायक (यह भी देखें) | विकोडक | LM | सामान्य संवाद से लेकर कोड सहायक तक। | anthropic |
| बार्ट | एनकोडर / डिकोडर | परमाणु ऊर्जा विभाग | टेक्स्ट जनरेशन और टेक्स्ट समझने के कार्य | फेसबुक |
| बर्ट | एनकोडर | एमएलएम/एनएसपी | भाषा की समझ और सवालों के जवाब | गूगल |
| ब्लेंडरबॉट 3 | विकोडक | LM | टेक्स्ट जनरेशन और टेक्स्ट समझने के कार्य | फेसबुक |
| फूल का खिलना | विकोडक | LM | टेक्स्ट जनरेशन और टेक्स्ट समझने के कार्य | बिग साइंस / हगिंगफेस |
| ChatGPT | विकोडक | LM | संवाद एजेंट | OpenAI |
| चिनचीला | विकोडक | LM | टेक्स्ट जनरेशन और टेक्स्ट समझने के कार्य | दीप मन |
| क्लिप | एनकोडर | छवि / वस्तु वर्गीकरण | OpenAI | |
| दबाएँ | विकोडक | नियंत्रित पाठ पीढ़ी | Salesforce | |
| DALL-E | विकोडक | कैप्शन भविष्यवाणी | छवि के लिए पाठ | OpenAI |
| दाल-ई-2 | एनकोडर / डिकोडर | कैप्शन भविष्यवाणी | छवि के लिए पाठ | OpenAI |
| डेबर्टा | विकोडक | एमएलएम | बर्ट के समान | माइक्रोसॉफ्ट |
| निर्णय ट्रांसफार्मर | विकोडक | अगली कार्रवाई की भविष्यवाणी | सामान्य आरएल (सुदृढीकरण सीखने के कार्य) | गूगल/यूसी बर्कले/फेयर |
| डायलोGPT | विकोडक | LM | डायलॉग सेटिंग में टेक्स्ट जेनरेशन | माइक्रोसॉफ्ट |
| डिस्टिलबर्ट | एनकोडर | एमएलएम/एनएसपी | भाषा की समझ और सवालों के जवाब | हग करने की क्रिया |
| डीक्यू-बार्ट | एनकोडर / डिकोडर | परमाणु ऊर्जा विभाग | पाठ पीढ़ी और समझ | वीरांगना |
| नादान | विकोडक | LM | पाठ निर्माण और वर्गीकरण कार्य | डाटाब्रिक्स, इंक |
| एर्नी | एनकोडर | एमएलएम | ज्ञान गहन संबंधित कार्य | विभिन्न चीनी संस्थान |
| राजहंस | विकोडक | कैप्शन भविष्यवाणी | छवि के लिए पाठ | दीप मन |
| Galactica | विकोडक | LM | वैज्ञानिक क्यूए, गणितीय तर्क, सारांश, दस्तावेज़ निर्माण, आणविक संपत्ति भविष्यवाणी और इकाई निष्कर्षण। | मेटा |
| फिसलन | एनकोडर | कैप्शन भविष्यवाणी | छवि के लिए पाठ | OpenAI |
| GPT-3.5 | विकोडक | LM | संवाद और सामान्य भाषा | OpenAI |
| GPTहिदायत | विकोडक | LM | ज्ञान-गहन संवाद या भाषा कार्य | OpenAI |
| एचटीएमएल | एनकोडर / डिकोडर | परमाणु ऊर्जा विभाग | भाषा मॉडल जो संरचित HTML संकेतन की अनुमति देता है | फेसबुक |
| छवि | T5 | कैप्शन भविष्यवाणी | छवि के लिए पाठ | गूगल |
| लमडा | विकोडक | LM | सामान्य भाषा मॉडलिंग | गूगल |
| LLaMA | विकोडक | LM | कॉमन्सेंस रीजनिंग, प्रश्न उत्तर, कोड जनरेशन और रीडिंग कॉम्प्रिहेंशन। | मेटा |
| सरस्वती | विकोडक | LM | गणितीय तर्क | गूगल |
| हथेली | विकोडक | LM | भाषा समझ और पीढ़ी | गूगल |
| RoberTa | एनकोडर | एमएलएम | भाषा की समझ और सवालों के जवाब | यूडब्ल्यू/गूगल |
| गौरैया | विकोडक | LM | डायलॉग एजेंट और सामान्य भाषा जनरेशन एप्लिकेशन जैसे क्यू एंड ए | दीप मन |
| स्थिर प्रसार | एनकोडर / डिकोडर | कैप्शन भविष्यवाणी | छवि के लिए पाठ | LMU म्यूनिख + Stability.ai + Eleuther.ai |
| विकग्ना | विकोडक | LM | संवाद एजेंट | यूसी बर्कले, सीएमयू, स्टैनफोर्ड, यूसी सैन डिएगो और एमबीजेडयूएआई |
अक्सर पूछे गए प्रश्न
AI में ट्रांसफार्मर एक प्रकार के होते हैं गहन शिक्षण वास्तुकला जिसने प्राकृतिक भाषा प्रसंस्करण और अन्य कार्यों को बदल दिया है। वे एक वाक्य में शब्दों के बीच संबंधों को पकड़ने के लिए आत्म-ध्यान तंत्र का उपयोग करते हैं, जिससे वे मानव-जैसे पाठ को समझने और उत्पन्न करने में सक्षम होते हैं।
एनकोडर और डिकोडर आमतौर पर सीक्वेंस-टू-सीक्वेंस मॉडल में उपयोग किए जाने वाले घटक हैं। एनकोडर इनपुट डेटा को प्रोसेस करते हैं, जैसे कि टेक्स्ट या इमेज, और इसे कंप्रेस्ड रिप्रेजेंटेशन में कन्वर्ट करते हैं, जबकि डिकोडर एन्कोडेड रिप्रेजेंटेशन के आधार पर आउटपुट डेटा जेनरेट करते हैं, जिससे लैंग्वेज ट्रांसलेशन या इमेज कैप्शनिंग जैसे कार्य सक्षम होते हैं।
ध्यान परतें ऐसे घटक हैं जिनका उपयोग किया जाता है तंत्रिका जाल, विशेष रूप से ट्रांसफार्मर मॉडल में। वे मॉडल को इनपुट अनुक्रम के विभिन्न हिस्सों पर चुनिंदा रूप से ध्यान केंद्रित करने में सक्षम बनाते हैं, प्रत्येक तत्व को उसकी प्रासंगिकता के आधार पर वजन प्रदान करते हैं, जिससे तत्वों के बीच निर्भरता और संबंधों को प्रभावी ढंग से पकड़ने की अनुमति मिलती है।
फ़ाइन-ट्यून किए गए मॉडल पूर्व-प्रशिक्षित मॉडल को संदर्भित करते हैं जिन्हें किसी विशिष्ट कार्य या डेटासेट पर उनके प्रदर्शन को बेहतर बनाने और उन्हें उस कार्य की विशिष्ट आवश्यकताओं के अनुकूल बनाने के लिए प्रशिक्षित किया गया है। इस फाइन-ट्यूनिंग प्रक्रिया में अपने पूर्वानुमानों को अनुकूलित करने और लक्ष्य कार्य के लिए इसे और अधिक विशिष्ट बनाने के लिए मॉडल के मापदंडों को समायोजित करना शामिल है।
ट्रांसफॉर्मर को एआई का भविष्य माना जाता है क्योंकि उन्होंने प्राकृतिक भाषा प्रसंस्करण, छवि निर्माण, और बहुत कुछ सहित कार्यों की एक विस्तृत श्रृंखला में असाधारण प्रदर्शन का प्रदर्शन किया है। लंबी दूरी की निर्भरता पर कब्जा करने और अनुक्रमिक डेटा को कुशलतापूर्वक संसाधित करने की उनकी क्षमता उन्हें विभिन्न अनुप्रयोगों के लिए अत्यधिक अनुकूलनीय और प्रभावी बनाती है, जिससे जनरेटिव एआई में प्रगति का मार्ग प्रशस्त होता है और समाज के कई पहलुओं में क्रांति आती है।
एआई में सबसे प्रसिद्ध ट्रांसफार्मर मॉडल में बीईआरटी (ट्रांसफॉर्मर्स से द्विदिश एनकोडर प्रतिनिधित्व) शामिल हैं। GPT (जेनरेटिव प्री-ट्रेंड ट्रांसफार्मर), और T5 (टेक्स्ट-टू-टेक्स्ट ट्रांसफर ट्रांसफार्मर)। इन मॉडलों ने विभिन्न प्राकृतिक भाषा प्रसंस्करण कार्यों में उल्लेखनीय परिणाम प्राप्त किए हैं और एआई अनुसंधान समुदाय में महत्वपूर्ण लोकप्रियता हासिल की है।
एआई के बारे में और पढ़ें:
Disclaimer
साथ लाइन में ट्रस्ट परियोजना दिशानिर्देश, कृपया ध्यान दें कि इस पृष्ठ पर दी गई जानकारी का कानूनी, कर, निवेश, वित्तीय या किसी अन्य प्रकार की सलाह के रूप में व्याख्या करने का इरादा नहीं है और न ही इसकी व्याख्या की जानी चाहिए। यह महत्वपूर्ण है कि केवल उतना ही निवेश करें जितना आप खो सकते हैं और यदि आपको कोई संदेह हो तो स्वतंत्र वित्तीय सलाह लें। अधिक जानकारी के लिए, हम नियम और शर्तों के साथ-साथ जारीकर्ता या विज्ञापनदाता द्वारा प्रदान किए गए सहायता और समर्थन पृष्ठों का संदर्भ लेने का सुझाव देते हैं। MetaversePost सटीक, निष्पक्ष रिपोर्टिंग के लिए प्रतिबद्ध है, लेकिन बाज़ार की स्थितियाँ बिना सूचना के परिवर्तन के अधीन हैं।
के बारे में लेखक
दामिर टीम लीडर, उत्पाद प्रबंधक और संपादक हैं Metaverse Postएआई/एमएल, एजीआई, एलएलएम, मेटावर्स और जैसे विषयों को कवर करता है Web3-संबंधित क्षेत्रों। उनके लेख हर महीने दस लाख से अधिक उपयोगकर्ताओं को आकर्षित करते हैं। ऐसा प्रतीत होता है कि वह SEO और डिजिटल मार्केटिंग में 10 वर्षों के अनुभव वाला एक विशेषज्ञ है। दामिर का उल्लेख मैशबल, वायर्ड, में किया गया है Cointelegraph, द न्यू यॉर्कर, Inside.com, एंटरप्रेन्योर, BeInCrypto, और अन्य प्रकाशन। वह एक डिजिटल खानाबदोश के रूप में संयुक्त अरब अमीरात, तुर्की, रूस और सीआईएस के बीच यात्रा करता है। दामिर ने भौतिकी में स्नातक की डिग्री हासिल की, उनका मानना है कि इससे उन्हें इंटरनेट के लगातार बदलते परिदृश्य में सफल होने के लिए आवश्यक महत्वपूर्ण सोच कौशल प्राप्त हुआ है।
और अधिक लेख
दामिर टीम लीडर, उत्पाद प्रबंधक और संपादक हैं Metaverse Postएआई/एमएल, एजीआई, एलएलएम, मेटावर्स और जैसे विषयों को कवर करता है Web3-संबंधित क्षेत्रों। उनके लेख हर महीने दस लाख से अधिक उपयोगकर्ताओं को आकर्षित करते हैं। ऐसा प्रतीत होता है कि वह SEO और डिजिटल मार्केटिंग में 10 वर्षों के अनुभव वाला एक विशेषज्ञ है। दामिर का उल्लेख मैशबल, वायर्ड, में किया गया है Cointelegraph, द न्यू यॉर्कर, Inside.com, एंटरप्रेन्योर, BeInCrypto, और अन्य प्रकाशन। वह एक डिजिटल खानाबदोश के रूप में संयुक्त अरब अमीरात, तुर्की, रूस और सीआईएस के बीच यात्रा करता है। दामिर ने भौतिकी में स्नातक की डिग्री हासिल की, उनका मानना है कि इससे उन्हें इंटरनेट के लगातार बदलते परिदृश्य में सफल होने के लिए आवश्यक महत्वपूर्ण सोच कौशल प्राप्त हुआ है।






