



30+ parimat AI transformaatorimudelit: mis need on ja kuidas need töötavad







Viimastel kuudel on tehisintellektis esile kerkinud arvukalt Transformeri mudeleid, millest igaühel on unikaalsed ja mõnikord ka lõbusad nimed. Need nimed ei pruugi aga anda palju ülevaadet sellest, mida need mudelid tegelikult teevad. Selle artikli eesmärk on pakkuda kõikehõlmavat ja lihtsat nimekirja kõige populaarsematest Transformeri mudelitest. See klassifitseerib need mudelid ja tutvustab ka Transformerite perekonna olulisi aspekte ja uuendusi. Top nimekiri katab modellid koolitatud läbi iseseisvalt juhendatud õppimise, nagu BERT või GPT-3, aga ka mudelid, mis läbivad inimeste osalusel täiendava koolituse, näiteks InstructGPT poolt kasutatud mudel ChatGPT.

| Pro näpunäited |
|---|
| Käesolev juhend eesmärk on anda põhjalikke teadmisi ja praktilisi oskusi kiires inseneritöös algajatele kuni edasijõudnutele. |
| Kursuseid on palju saadaval inimestele, kes soovivad AI ja sellega seotud tehnoloogiate kohta rohkem teada saada. |
| Heitke pilk 10+ parimat AI kiirendit mis peaksid jõudluse poolest turgu juhtima. |
Mis on AI transformerid?
Transformerid on teatud tüüpi süvaõppe mudelid, mida tutvustati uurimistöös nimega "Tähelepanu on kõik, mida vajateGoogle'i teadlased 2017. aastal. See artikkel on pälvinud tohutut tunnustust, kogudes vaid viie aastaga üle 38,000 XNUMX tsitaadi.
Algne Transformeri arhitektuur on kodeerija-dekoodri mudelite spetsiifiline vorm, mis oli populaarsust kogunud enne selle kasutuselevõttu. Need mudelid tuginesid peamiselt LSTM ja muud korduvate närvivõrkude variatsioonid (RNN-id), kusjuures tähelepanu on vaid üks kasutatud mehhanismidest. Transformeri artikkel pakkus aga välja revolutsioonilise idee, et tähelepanu võiks olla ainsa mehhanismina sisendi ja väljundi vahelise sõltuvuse kindlakstegemiseks.
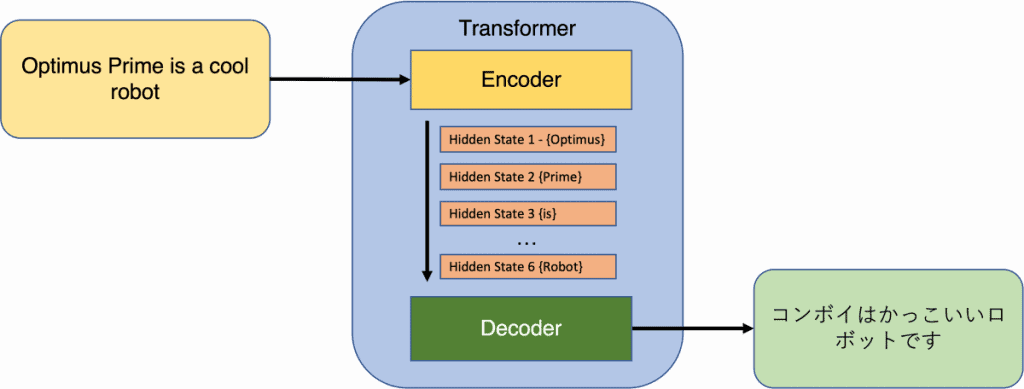
Transformerite kontekstis koosneb sisend märkide jadast, milleks võivad loomuliku keele töötlemisel olla sõnad või alamsõnad (NLP). Alamsõnu kasutatakse NLP-mudelites tavaliselt sõnavaraväliste sõnade probleemi lahendamiseks. Kodeerija väljund loob iga märgi jaoks fikseeritud mõõtmega esituse koos kogu jada jaoks eraldi manustamisega. Dekooder võtab kodeerija väljundi ja genereerib väljundina žetoonide jada.
Alates Transformeri paberi avaldamisest on populaarsed mudelid nagu BERT ja GPT on võtnud kasutusele algse arhitektuuri aspektid, kasutades kas kodeerijat või dekoodri komponente. Nende mudelite peamine sarnasus seisneb kihiarhitektuuris, mis sisaldab enesetähelepanu mehhanisme ja edasisuunas kihte. Transformaatorites läbib iga sisendmärk oma tee läbi kihtide, säilitades samal ajal otsesed sõltuvused sisendjada kõigi teiste märgistega. See ainulaadne funktsioon võimaldab paralleelselt ja tõhusalt arvutada kontekstuaalseid märgiesitusi, mis pole järjestikuste mudelite, nagu RNN-ide, puhul teostatav.
Kuigi see artikkel kriibib ainult Transformeri arhitektuuri pinda, annab see pilgu selle põhiaspektidele. Põhjalikuma arusaamise saamiseks soovitame viidata algsele uurimistööle või The Illustrated Transformeri postitusele.
Mis on AI kodeerijad ja dekoodrid?
Kujutage ette, et teil on kaks mudelit, kodeerija ja dekooder, koostööd nagu meeskond. Kodeerija võtab sisendi ja muudab selle fikseeritud pikkusega vektoriks. Seejärel võtab dekooder selle vektori ja teisendab selle väljundjadaks. Neid mudeleid koolitatakse koos tagamaks, et väljund vastab võimalikult täpselt sisendile.
Nii kodeerijal kui ka dekooderil oli mitu kihti. Igal kodeerija kihil oli kaks alamkihti: mitme peaga enesetähelepanu kiht ja lihtne edasisuunav võrk. Enesetähelepanu kiht aitab igal sisendis oleval märgil mõista seoseid kõigi teiste märkidega. Nendel alamkihtidel on ka jääkühendus ja kihtide normaliseerimine, et muuta õppeprotsess sujuvamaks.
Dekoodri mitmepealine enesetähelepanu kiht töötab kodeerija omast pisut erinevalt. See maskeerib märgid, mis asuvad märgist paremal, millele see keskendub. See tagab, et dekooder vaatab ainult neid märke, mis tulevad enne seda, mida ta üritab ennustada. See maskeeritud mitmepealine tähelepanu aitab dekoodril luua täpseid ennustusi. Lisaks sisaldab dekooder veel üht alamkihti, mis on kõigi kodeerija väljundite mitmepealine tähelepanukiht.
Oluline on märkida, et neid konkreetseid üksikasju on Transformeri mudeli erinevates variatsioonides muudetud. Mudelid nagu BERT ja GPTNäiteks põhinevad algse arhitektuuri kodeerija või dekoodri aspektil.
Mis on AI-s tähelepanukihid?
Varem käsitletud mudeliarhitektuuris on mitme peaga tähelepanukihid erielemendid, mis muudavad selle võimsaks. Aga mis täpselt on tähelepanu? Mõelge sellele kui funktsioonile, mis kaardistab küsimuse teabekogumiga ja annab väljundi. Igal sisendis oleval märgil on sellega seotud päring, võti ja väärtus. Iga märgi väljundi esitus arvutatakse väärtuste kaalutud summana, kus iga väärtuse kaal määratakse selle järgi, kui hästi see päringule vastab.
Transformaatorid kasutavad nende kaalude arvutamiseks ühilduvusfunktsiooni, mida nimetatakse skaleeritud punktitooteks. Trafode tähelepanu juures on huvitav see, et iga luba läbib oma arvutustee, mis võimaldab paralleelselt arvutada kõik sisendjärjestuses olevad märgid. See on lihtsalt mitu tähelepanuplokki, mis arvutavad sõltumatult iga märgi esituse. Seejärel ühendatakse need esitused, et luua märgi lõplik esitus.
Võrreldes teist tüüpi võrkudega nagu korduvad ja konvolutsioonivõrgud, on tähelepanukihtidel mõned eelised. Need on arvutuslikult tõhusad, mis tähendab, et nad saavad teavet kiiresti töödelda. Neil on ka suurem ühenduvus, mis on abiks pikaajaliste suhete jäädvustamisel järjestustes.
Mis on AI peenhäälestatud mudelid?
Vundamendi mudelid on võimsad mudelid, mis on koolitatud suure hulga üldiste andmete põhjal. Seejärel saab neid kohandada või täpsustada konkreetsete ülesannete jaoks, treenides neid väiksemal komplektil sihtmärgipõhised andmed. Seda lähenemisviisi on populariseerinud BERT paber, on viinud Transformeri-põhiste mudelite domineerimiseni keelega seotud masinõppeülesannetes.
Selliste mudelite puhul nagu BERT toodavad nad sisendmärke, kuid ei täida konkreetseid ülesandeid üksinda. Et need oleksid kasulikud, lisage närvikihid lisatakse peale ja mudelit õpetatakse lõpuni, seda protsessi nimetatakse peenhäälestamiseks. Siiski koos generatiivsed mudelid nagu GPT, on lähenemine veidi erinev. GPT on dekooderkeele mudel, mis on treenitud ennustama lause järgmist sõna. Treenides tohutul hulgal veebiandmeid, GPT suudab sisendpäringute või viipade põhjal genereerida mõistlikke väljundeid.
Et GPT rohkem abi, OpenAI teadlased arendasid JuhendaGPT, mis on koolitatud järgima inimese juhiseid. See saavutatakse peenhäälestusega GPT kasutades inimmärgistatud andmeid erinevatest ülesannetest. JuhendaGPT on võimeline täitma mitmesuguseid ülesandeid ja seda kasutavad populaarsed mootorid nagu ChatGPT.
Peenhäälestamist saab kasutada ka vundamendimudelite jaoks optimeeritud variantide loomiseks konkreetsetel eesmärkidel väljaspool keele modelleerimist. Näiteks on olemas mudelid, mis on peenhäälestatud semantiliste ülesannete jaoks, nagu teksti klassifitseerimine ja otsingu otsimine. Lisaks on trafokoodereid edukalt viimistletud mitme ülesande raames õpperaamistikud mitme semantilise ülesande täitmiseks ühe jagatud mudeli abil.
Tänapäeval kasutatakse peenhäälestamist vundamendimudelite versioonide loomiseks, mida saab kasutada suur hulk kasutajaid. Protsess hõlmab sisendile vastuste genereerimist viipasid ja lasta inimestel tulemusi järjestada. Seda pingerida kasutatakse a treenimiseks tasu mudel, mis määrab igale väljundile hinded. Õppimise tugevdamine inimeste tagasisidega kasutatakse seejärel mudeli edasiseks koolitamiseks.
Miks on Transformers AI tulevik?
Transformereid, teatud tüüpi võimsaid mudeleid, demonstreeriti esmakordselt keeletõlke valdkonnas. Teadlased mõistsid aga kiiresti, et Transformereid saab kasutada mitmesuguste keelega seotud ülesannete jaoks, koolitades neid suure hulga märgistamata tekstiga ja seejärel viimistledes neid väiksema märgistatud andmete kogumi alusel. See lähenemisviis võimaldas Transformeritel omandada olulisi teadmisi keele kohta.
Transformeri arhitektuuri, mis oli algselt loodud keeleülesannete jaoks, on rakendatud ka muudele rakendustele, nagu piltide genereerimine, heli, muusika ja isegi toimingud. See on muutnud Transformersist võtmekomponendiks generatiivse tehisintellekti valdkonnas, mis muudab ühiskonna erinevaid aspekte.
Tööriistade ja raamistike kättesaadavus nagu PyTorch ja TensorFlow on mänginud otsustavat rolli Transformeri mudelite laialdasel kasutuselevõtul. Sellised ettevõtted nagu Huggingface on loonud oma äri idee ümber avatud lähtekoodiga Transformeri teekide kommertsialiseerimine ja spetsiaalne riistvara, nagu NVIDIA Hopper Tensor Cores, on veelgi kiirendanud nende mudelite treenimist ja järelduste kiirust.
Transformerite üks tähelepanuväärne rakendus on ChatGPT, poolt välja antud vestlusbot OpenAI. See sai uskumatult populaarseks, jõudes lühikese aja jooksul miljonite kasutajateni. OpenAI on samuti teatanud vabastamisest GPT-4, võimsam versioon, mis suudab saavutada inimesesarnase jõudluse sellistes ülesannetes nagu meditsiinilised ja juriidilised eksamid.
Transformerite mõju tehisintellekti ja nende laiaulatuslike rakenduste valdkonnas on vaieldamatu. Neil on muutis teed läheneme keelega seotud ülesannetele ja sillutame teed generatiivse AI uutele edusammudele.
3 eelkoolitusarhitektuuri tüüpi
Transformeri arhitektuur, mis algselt koosnes kodeerijast ja dekooderist, on arenenud nii, et see sisaldab erinevaid variatsioone, mis põhinevad konkreetsetel vajadustel. Jaotame need variatsioonid lihtsate sõnadega.
- Kodeerija eelkoolitus: need mudelid keskenduvad terviklike lausete või lõikude mõistmisele. Eeltreeningu ajal kasutatakse kodeerijat sisendlauses maskeeritud märkide rekonstrueerimiseks. See aitab mudelil õppida mõistma üldist konteksti. Sellised mudelid on kasulikud selliste ülesannete jaoks nagu teksti klassifitseerimine, tagajärjed ja küsimustele vastamine.
- Dekoodri eelkoolitus: Dekoodri mudelid on koolitatud genereerima järgmist märki eelmise žetoonide jada põhjal. Neid tuntakse autoregressiivsete keelemudelitena. Dekoodri enesetähelepanu kihid pääsevad juurde ainult žetoonidele, mis on lauses etteantud märgi ees. Need mudelid sobivad ideaalselt teksti genereerimisega seotud ülesannete jaoks.
- Trafo (kooder-dekooder) eelkoolitus: see variatsioon ühendab endas nii kodeerija kui ka dekoodri komponendid. Kodeerija enesetähelepanu kihid pääsevad juurde kõikidele sisendtunnustele, samas kui dekoodri enesetähelepanu kihid pääsevad juurde ainult enne antud luba. See arhitektuur võimaldab dekoodril kasutada kodeerija õpitud esitusi. Kodeerija-dekoodri mudelid sobivad hästi selliste ülesannete jaoks nagu kokkuvõtete tegemine, tõlkimine või generatiivne küsimustele vastamine.
Koolituseelsed eesmärgid võivad hõlmata müra vähendamist või põhjusliku keele modelleerimist. Need eesmärgid on kodeerija-dekoodri mudelite puhul keerukamad kui ainult kodeerija või ainult dekoodriga mudelitega. Transformeri arhitektuuril on sõltuvalt mudeli fookusest erinevad variatsioonid. Olgu selleks siis terviklike lausete mõistmine, teksti genereerimine või mõlema kombineerimine erinevate ülesannete jaoks, pakub Transformers paindlikkust erinevate keelega seotud väljakutsete lahendamisel.
8 tüüpi ülesandeid eelkoolitatud modellidele
Modelli koolitamisel peame andma talle ülesande või eesmärgi, millest õppida. Loomuliku keele töötlemisel (NLP) on erinevaid ülesandeid, mida saab kasutada mudelite eelkoolitamiseks. Jaotame mõned neist ülesannetest lihtsate sõnadega:
- Keele modelleerimine (LM): mudel ennustab lause järgmise märgi. Õpib mõistma konteksti ja genereerima sidusaid lauseid.
- Põhjusliku keele modelleerimine: mudel ennustab järgmise märgi tekstijadas, järgides järjestust vasakult paremale. See on nagu jutuvestmismudel, mis genereerib lauseid ühe sõna kaupa.
- Prefiksi keele modelleerimine: mudel eraldab põhijadast eesliite osa. See võib käsitleda mis tahes märgi eesliites ja seejärel genereerib ülejäänud jada autoregressiivselt.
- Maskeeritud keele modelleerimine (MLM): mõned sisendlausetes olevad märgid on maskeeritud ja mudel ennustab puuduvad märgid ümbritseva konteksti põhjal. See õpib lünki täitma.
- Permuteeritud keele modelleerimine (PLM): mudel ennustab sisendjärjestuse juhusliku permutatsiooni põhjal järgmise märgi. See õpib käsitlema erinevaid märkide järjekordi.
- Denoising Autoencoder (DAE): mudel kasutab osaliselt rikutud sisendit ja selle eesmärk on taastada algne, moonutamata sisend. Ta õpib käsitlema müra või puuduvaid tekstiosi.
- Asendatud märgi tuvastamine (RTD): mudel tuvastab, kas märk pärineb originaaltekstist või genereeritud versioonist. See õpib tuvastama asendatud või manipuleeritud märke.
- Järgmise lause ennustamine (NSP): mudel õpib eristama, kas kaks sisendlauset on treeningandmetest pidevad segmendid. Ta mõistab lausete vahelist seost.
Need ülesanded aitavad mudelil õppida keele struktuuri ja tähendust. Nende ülesannete täitmiseks eelkoolitades saavad mudelid keelest hästi aru, enne kui neid konkreetsete rakenduste jaoks peenhäälestatakse.
30+ parimat AI transformerit
| Nimi | Arhitektuuri eelkoolitus | Ülesanne | taotlus | Välja töötanud |
|---|---|---|---|---|
| ALBERT | Encoder | MLM/NSP | Sama mis BERT | |
| Alpaca | dekooder | LM | Teksti genereerimise ja klassifitseerimise ülesanded | Stanfordi |
| AlfaFold | Encoder | Valkude voltimise ennustus | Valkude voltimine | Sügavkülm |
| Antroopne assistent (vt ka) | dekooder | LM | Ülddialoogist koodiassistendini. | Antroopne |
| BART | Kodeerija/dekooder | AED | Teksti genereerimise ja tekstist arusaamise ülesanded | |
| BERT | Encoder | MLM/NSP | Keele mõistmine ja küsimustele vastamine | |
| BlenderBot 3 | dekooder | LM | Teksti genereerimise ja tekstist arusaamise ülesanded | |
| BLOOM | dekooder | LM | Teksti genereerimise ja tekstist arusaamise ülesanded | Suur Teadus / Kallistanud nägu |
| ChatGPT | dekooder | LM | Dialoogiagendid | OpenAI |
| tšintšilja | dekooder | LM | Teksti genereerimise ja tekstist arusaamise ülesanded | Sügavkülm |
| CLIP | Encoder | Kujutise/objekti klassifikatsioon | OpenAI | |
| CTRL | dekooder | Kontrollitav teksti genereerimine | Sales Force | |
| DALL-E | dekooder | Tiitrite ennustus | Tekst pildiks | OpenAI |
| DALL-E-2 | Kodeerija/dekooder | Tiitrite ennustus | Tekst pildiks | OpenAI |
| DeBERTa | dekooder | MLM | Sama mis BERT | Microsoft |
| Otsuste transformaatorid | dekooder | Järgmise tegevuse ennustus | Üldine RL (tugevdamise õppeülesanded) | Google/UC Berkeley/FAIR |
| DialoGPT | dekooder | LM | Teksti genereerimine dialoogiseadetes | Microsoft |
| DistilBERT | Encoder | MLM/NSP | Keele mõistmine ja küsimustele vastamine | Kallistav nägu |
| DQ-BART | Kodeerija/dekooder | AED | Teksti genereerimine ja mõistmine | Amazon |
| Dolly | dekooder | LM | Teksti genereerimise ja klassifitseerimise ülesanded | Databricks, Inc |
| ERNIE | Encoder | MLM | Teadmismahukad seotud ülesanded | Erinevad Hiina institutsioonid |
| Flamingo | dekooder | Tiitrite ennustus | Tekst pildiks | Sügavkülm |
| Galaktika | dekooder | LM | Teaduslik kvaliteedi tagamine, matemaatiline arutluskäik, kokkuvõte, dokumentide genereerimine, molekulaarsete omaduste ennustamine ja olemi eraldamine. | Meta |
| KLAAS | Encoder | Tiitrite ennustus | Tekst pildiks | OpenAI |
| GPT-3.5 | dekooder | LM | Dialoog ja üldkeel | OpenAI |
| GPTJuhenda | dekooder | LM | Teadmusmahukad dialoogi- või keeleülesanded | OpenAI |
| HTML | Kodeerija/dekooder | AED | Keelemudel, mis võimaldab struktureeritud HTML-i viipasid | |
| Pilt | T5 | Tiitrite ennustus | Tekst pildiks | |
| LAMDA | dekooder | LM | Üldkeele modelleerimine | |
| LLaMA | dekooder | LM | Tervislik arutluskäik, küsimustele vastamine, koodi genereerimine ja lugemise mõistmine. | Meta |
| Minerva | dekooder | LM | Matemaatiline arutluskäik | |
| palm | dekooder | LM | Keele mõistmine ja genereerimine | |
| RoBERTa | Encoder | MLM | Keele mõistmine ja küsimustele vastamine | UW/Google |
| Sparrow | dekooder | LM | Dialoogiagendid ja üldised keele genereerimise rakendused, nagu küsimused ja vastused | Sügavkülm |
| Stabiilne difusioon | Kodeerija/dekooder | Pealkirja ennustus | Tekst pildiks | LMU München + Stability.ai + Eleuther.ai |
| Vicuna | dekooder | LM | Dialoogiagendid | UC Berkeley, CMU, Stanford, UC San Diego ja MBZUAI |
KKK
AI transformerid on teatud tüüpi süvaõppe arhitektuur mis on muutnud loomulikku keeletöötlust ja muid ülesandeid. Nad kasutavad enesetähelepanu mehhanisme, et tabada lauses sõnade vahelisi seoseid, võimaldades neil mõista ja genereerida inimlikku teksti.
Kodeerijad ja dekoodrid on komponendid, mida tavaliselt kasutatakse järjestus-jada mudelites. Kodeerijad töötlevad sisendandmeid, nagu tekst või pildid, ja teisendavad need tihendatud esituseks, samas kui dekoodrid genereerivad kodeeritud esituse põhjal väljundandmeid, võimaldades selliseid toiminguid nagu keeletõlge või piltide pealdised.
Tähelepanu kihid on komponendid, mida kasutatakse närvivõrgud, eriti trafode mudelites. Need võimaldavad mudelil keskenduda valikuliselt sisendjärjestuse erinevatele osadele, määrates igale elemendile kaalud selle asjakohasuse alusel, võimaldades tõhusalt tabada sõltuvusi ja seoseid elementide vahel.
Peenhäälestatud mudelid viitavad eelkoolitatud mudelitele, mida on konkreetse ülesande või andmekogumi jaoks täiendavalt koolitatud, et parandada nende toimivust ja kohandada neid selle ülesande spetsiifiliste nõuetega. See peenhäälestusprotsess hõlmab mudeli parameetrite kohandamist, et optimeerida selle ennustusi ja muuta see sihtülesande jaoks spetsialiseeritumaks.
Transformereid peetakse tehisintellekti tulevikuks, kuna need on näidanud erakordset jõudlust paljudes ülesannetes, sealhulgas loomuliku keele töötlemisel, kujutiste genereerimisel ja muul viisil. Nende võime tabada pikamaa sõltuvusi ja töödelda tõhusalt järjestikuseid andmeid muudab need erinevate rakenduste jaoks väga kohanemisvõimeliseks ja tõhusaks, sillutades teed generatiivse tehisintellekti arengule ja muutes revolutsiooni paljudes ühiskonna aspektides.
AI kuulsaimate trafomudelite hulka kuuluvad BERT (transformaatorite kahesuunalised kodeerijad), GPT (Generatiivne eelkoolitatud transformer) ja T5 (tekst-teksti edastamise transformer). Need mudelid on saavutanud märkimisväärseid tulemusi erinevates loomuliku keele töötlemise ülesannetes ja saavutanud märkimisväärse populaarsuse tehisintellekti teadlaskonnas.
Loe AI kohta lähemalt:
Kaebused
Vastavalt Usaldusprojekti juhised, pange tähele, et sellel lehel esitatud teave ei ole mõeldud ega tohiks tõlgendada kui juriidilist, maksu-, investeerimis-, finants- või muud nõuannet. Oluline on investeerida ainult seda, mida saate endale lubada kaotada, ja kahtluste korral küsida sõltumatut finantsnõu. Lisateabe saamiseks soovitame vaadata nõudeid ja tingimusi ning väljaandja või reklaamija pakutavaid abi- ja tugilehti. MetaversePost on pühendunud täpsele ja erapooletule aruandlusele, kuid turutingimusi võidakse ette teatamata muuta.
Umbes Autor
Damir on ettevõtte meeskonnajuht, tootejuht ja toimetaja Metaverse Post, mis hõlmab selliseid teemasid nagu AI/ML, AGI, LLM-id, Metaverse ja Web3-seotud väljad. Tema artiklid meelitavad igal kuul tohutut vaatajaskonda, üle miljoni kasutaja. Ta näib olevat ekspert, kellel on 10-aastane SEO ja digitaalse turunduse kogemus. Damirit on mainitud ajakirjades Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto ja muud väljaanded. Ta reisib digitaalse nomaadina AÜE, Türgi, Venemaa ja SRÜ vahel. Damir omandas bakalaureusekraadi füüsikas, mis on tema arvates andnud talle kriitilise mõtlemise oskused, mida on vaja pidevalt muutuval Interneti-maastikul edukaks saamiseks.
Veel artikleid
Damir on ettevõtte meeskonnajuht, tootejuht ja toimetaja Metaverse Post, mis hõlmab selliseid teemasid nagu AI/ML, AGI, LLM-id, Metaverse ja Web3-seotud väljad. Tema artiklid meelitavad igal kuul tohutut vaatajaskonda, üle miljoni kasutaja. Ta näib olevat ekspert, kellel on 10-aastane SEO ja digitaalse turunduse kogemus. Damirit on mainitud ajakirjades Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto ja muud väljaanded. Ta reisib digitaalse nomaadina AÜE, Türgi, Venemaa ja SRÜ vahel. Damir omandas bakalaureusekraadi füüsikas, mis on tema arvates andnud talle kriitilise mõtlemise oskused, mida on vaja pidevalt muutuval Interneti-maastikul edukaks saamiseks.






