



LLM-programmid: uus tee närvimudelite peenhäälestamiseks keerulistes olukordades







Põgusalt
Autorid pakuvad välja alternatiivse tee nimega LLM programmid, mida võib pidada kontekstisisese õppimise arendamiseks.
LLM-programmi kaudu probleemi lahendamise võti on võime jagada probleemi lahendus lihtsamate sammude jadaks.
LLM-i kohandamisel on kaks peamist valdkonda: eelkoolitatud baasmudeli peenhäälestus (või lisakoolitus) ja kontekstisisene õpe. Peenhäälestus nõuab selleks märkimisväärseid arvutusressursse, andmete kogumist ja infrastruktuuri ning seejärel peenhäälestatud mudelite hostimist. Samal ajal hõlmab kontekstis õppimine õige viipe koostamist probleemi lahendamise näidetega, näiteks mõtteahel (CoT). Siiski on mõningaid raskusi, näiteks mudelile esitatava teksti piiratud suurus ja asjaolu, et keerulises mitme läbimise viipa korral võivad sammud üksteist segada ja miski võib mudelit segada. mida ei tohiks praegu segada. Autorid pakuvad välja alternatiivse tee nimega LLM programmid, mida võib pidada kontekstisisese õppimise arendamiseks.

| Soovitan: Prompt Engineering Ultimate Guide 2023 |
LLM on programmi sisse ehitatud (tavapärases programmeerimiskeel, näiteks Pythonis). See väline kood vastutab oleku salvestamise ja mudeli samm-sammult hooldamise eest. Sellel on mõned olulised eelised: programmeerimiskeeled on selleks kohandatud, saadaoleva konteksti suurus kasvab ja sammud ei sega üksteist. LLM-programmi kaudu probleemi lahendamise võti on võime jagada probleemi lahendus lihtsamate sammude jadaks. Selline lähenemine erineb varasematest töödest, kus mudelis kasutati väliseid tööriistu nagu kalkulaatorid või kooditõlgid riiki ülal pidada. Selline lähenemine on hea, sest nii on võimalik kirjeldada keerulist ja laialivalguvat ülesannet, mis muudab testimise, silumise ja kvaliteedi hindamise lihtsamaks.
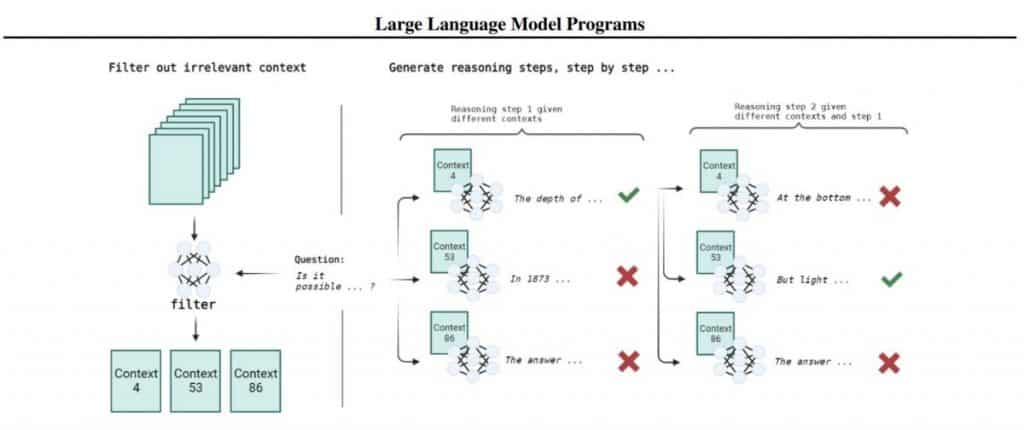
Lisaks ei esine sammude vahel häireid, mis muudab LLM-iga töötamise lihtsamaks. Ka küsimuste-vastuste süsteemid pole uued; nad on eksisteerinud ammu enne LLM-e. Kuidas nüüd lahendatakse küsimustele vastamise ülesanne?
Saite värskendatakse sageli, nii et a külmutatud mudel ei ole valik; see aegub kiiresti ja ei suuda vastata uute toodetega seotud küsimustele. Mudeli pidev ümberõpe iga värskenduse jaoks ei ole realistlik: see on kallis ja aeganõudev. Selle asemel on veebisaidi lehed tavaliselt indekseeritud, paigutatud mingisse andmebaasi ja sageli vektoriseeritud. Kasutaja soovil tõmmatakse asjakohased dokumendid üles ja saadetakse kontekstina LLM-ile.
Sellises paradigmas lahendatakse probleem loomulikult LLM programmi kaudu. Boonusena see muutub võimalikuks rakendada keerukamat mitme läbipääsuga loogikat, mis ei sobituks täielikult konteksti.
Testitud peal StrategyQA andmestik mis sisaldab binaarseid klassifikatsiooniülesandeid, mille lahendamine hõlmab mitmesuunalist arutlust. Nagu "Kas päikesevalgus tungib Musta mere sügavaimasse kohta?". Vastamiseks tuleb leida maksimaalne sügavus (2 km) ja kui sügavale valgus vette tungib (1 km) ning seejärel teha järeldus. Vaatame veel ühte näidet: "Kas Aristoteles kasutas sülearvutit?" See küsimus ei ole nii lihtne ega järgi selgesõnaliselt arutluskäiku kui "Kas Aristoteles oli sülearvuti leiutamise ajal elus?" teeb. Andmekogum keskendub küsimustele, kus selline jada on kaudne. Andmekogus on ainult 2,780 küsimust, millest ainult 918-l on lõigud tõenditega, mis tugevdavad kõiki arutluskäike. Praeguses töös piirdub see selle alamhulgaga; vastasel juhul peaksime lootma, et LLM õpib eelkoolituse käigus mõned faktid.
Vaikimisi OPT-175B LLM ei järgi juhiseid eriti hästi; see ei pidanud viimistlema juhiseid ega vestlusandmeid. Tõenduspõhiste küsimuste-vastuste probleemi lahendamiseks jaguneb see andmete filtreerimise etapiks ja puuotsingu etapiks.
Filtreerimisetapis vaatavad arendajad küsimusega läbi kõik lõigud ja valivad välja kõige asjakohasemad. Näiteks paluge LLM-il mõne löögiga viipaga vastata (jah/ei), kas antud lõik on esitatud küsimuse jaoks asjakohane. Testitud StrategyQA 300 alamhulgaga, kus iga küsimus sobitati lõiguga, olenemata sellest, kas see on asjakohane või mitte, 50/50. OPT-175B ja text-davinci-002 ei sisalda a palju kvaliteetsem kui juhuslik baasjoon: kuni 56%. Mida arenenum 11B Tk-Instruct ei ole palju parem – 61.6%.
Selle lähenemisviisi halva kvaliteedi tõttu pandi kokku alternatiiv, mis arvestab küsimuse keskmist negatiivset logaritmilist tõenäosust (NLL) koos eelmise teksti lõiguga ja reastab seejärel tulemused. Hinnati andmekogumis, kus iga küsimuse jaoks oli 100 lõiku ja ainult üks oli asjakohane (nii et juhuslik arvamine annab 1%). Saime tipp-1 täpsuse 79% ja top-5 93%. Selle arvutuse jaoks vajate tavaliselt juurdepääsu mudelile endale, mida API-s alati ei tehta.
Edasi tuleb väljundahelate ülesehitamise etapp. Seda tehakse puu kaudu otsinguga, kus küsimus on juur, ja igal tasandil on palju lõike koos võimalike tõenditega, mida kasutatakse kontekstina järgmise sammu loomiseks. Iga tee läbi puu on potentsiaalne väljundahel. Kõigi võimalike ahelate kohta järelduste tegemine on ebareaalne, seetõttu järjestatakse kõik saadaolevad ahelad ja kõrgeima järjekohaga ahelat laiendatakse. See on selline kiirotsingu variatsioon. Protsess peatub, kui vastatakse või kui maksimaalne lubatud arv samme on möödas.
Kõige olulisemad üksikasjad on kaks puuotsingu etapis testitud järjestamisstrateegiat. Esimene strateegia põhineb kogu ahela keskmisel NLL-il, samas kui teine strateegia vaatleb keskmist erinevust NLL-is koos lõiguga ja ilma (P), küsimusega ja ilma (Q). StrategyQA saadaoleva 918 küsimuse puhul parandab see lähenemine märkimisväärselt vastuste kvaliteeti võrreldes CoT algtasemega (60%); mõlemad otsinguvalikud annavad umbes 66% (veidi kõrgema deltaga strateegia). Kuldsete faktide esitamisel on kvaliteet umbes 81%, mis on OPT ülempiir. Tundub, et Darklang läheb sinna kuhugi, kuid veidi teistmoodi.
Artikkel põhineb Telegramil pärast.
Loe AI kohta lähemalt:
Kaebused
Vastavalt Usaldusprojekti juhised, pange tähele, et sellel lehel esitatud teave ei ole mõeldud ega tohiks tõlgendada kui juriidilist, maksu-, investeerimis-, finants- või muud nõuannet. Oluline on investeerida ainult seda, mida saate endale lubada kaotada, ja kahtluste korral küsida sõltumatut finantsnõu. Lisateabe saamiseks soovitame vaadata nõudeid ja tingimusi ning väljaandja või reklaamija pakutavaid abi- ja tugilehti. MetaversePost on pühendunud täpsele ja erapooletule aruandlusele, kuid turutingimusi võidakse ette teatamata muuta.
Umbes Autor
Damir on ettevõtte meeskonnajuht, tootejuht ja toimetaja Metaverse Post, mis hõlmab selliseid teemasid nagu AI/ML, AGI, LLM-id, Metaverse ja Web3-seotud väljad. Tema artiklid meelitavad igal kuul tohutut vaatajaskonda, üle miljoni kasutaja. Ta näib olevat ekspert, kellel on 10-aastane SEO ja digitaalse turunduse kogemus. Damirit on mainitud ajakirjades Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto ja muud väljaanded. Ta reisib digitaalse nomaadina AÜE, Türgi, Venemaa ja SRÜ vahel. Damir omandas bakalaureusekraadi füüsikas, mis on tema arvates andnud talle kriitilise mõtlemise oskused, mida on vaja pidevalt muutuval Interneti-maastikul edukaks saamiseks.
Veel artikleid
Damir on ettevõtte meeskonnajuht, tootejuht ja toimetaja Metaverse Post, mis hõlmab selliseid teemasid nagu AI/ML, AGI, LLM-id, Metaverse ja Web3-seotud väljad. Tema artiklid meelitavad igal kuul tohutut vaatajaskonda, üle miljoni kasutaja. Ta näib olevat ekspert, kellel on 10-aastane SEO ja digitaalse turunduse kogemus. Damirit on mainitud ajakirjades Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto ja muud väljaanded. Ta reisib digitaalse nomaadina AÜE, Türgi, Venemaa ja SRÜ vahel. Damir omandas bakalaureusekraadi füüsikas, mis on tema arvates andnud talle kriitilise mõtlemise oskused, mida on vaja pidevalt muutuval Interneti-maastikul edukaks saamiseks.






