



8 asja, mida peaksite teadma suurte keelemudelite kohta






Põgusalt
Suured keelemudelid (LLM-id) kasutatakse loomuliku keele nüansside uurimiseks, masinate teksti mõistmise ja genereerimise võime parandamiseks ning selliste ülesannete automatiseerimiseks nagu hääletuvastus ja masintõlge.
LLM-ide haldamiseks pole lihtsat lahendust, kuid nad on sama võimekad kui inimesed.
Seoses loomuliku keeletöötluse arengu ja selle kasutamisega ettevõtluses kasvab huvi suurte keelemudelite vastu. Neid mudeleid kasutatakse loomuliku keele nüansside uurimiseks, masinate teksti mõistmise ja genereerimise võime parandamiseks ning selliste ülesannete automatiseerimiseks nagu hääletuvastus ja masintõlge. Siin on kaheksa olulist asja, mida peaksite suurte keelemudelite (LLM) kohta teadma.

- LLM-id on "võimekamad", kuna kulud kasvavad pidevalt
- Kiire ülevaade, kuidas GPT mudelid kohanduvad koolituskulude tõustes
- LLM-id õpivad mängima lauamänge, kasutades välismaailma esitusi
- LLM-i haldamiseks pole lihtsat lahendust
- Ekspertidel on raskusi LLM-i toimimise selgitamisega
- LLM-id on sama võimekad kui inimesed
- LLM-id peavad olema midagi enamat kui lihtsalt "kõigepealt"
- Modellid on „targemad”, kui inimesed esmamulje põhjal arvavad
LLM-id on "võimekamad", kuna kulud kasvavad pidevalt
LLM-id muutuvad kasvavate kuludega prognoositavalt "võimekamaks" isegi ilma lahedate uuendusteta. Peamine on siin etteaimatavus, mida näidati artiklis GPT-4: õpetati viis kuni seitse väikest mudelit eelarvega 0.1% lõplikust ja seejärel tehti selle põhjal ennustus hiiglaslikule mudelile. Ühe konkreetse ülesande alamvalimi segaduse ja mõõdikute üldiseks hindamiseks oli selline ennustus väga täpne. See prognoositavus on oluline ettevõtetele ja organisatsioonidele, kes loodavad oma tegevuses LLM-idele, kuna nad saavad vastavalt eelarvele koostada ja tulevasi kulusid planeerida. Siiski on oluline märkida, et kuigi kulude suurenemine võib kaasa tuua paremate võimete, võib paranemise määr lõpuks tasaneda, mistõttu on edasiminekuks vaja investeerida uutesse uuendustesse.
Kiire ülevaade, kuidas GPT mudelid kohanduvad koolituskulude tõustes
Konkreetsed olulised oskused kipuvad aga suurenemise kõrvalsaadusena ettearvamatult esile kerkima koolituskulud (pikem koolitus, rohkem andmeid, suurem mudel) — peaaegu võimatu ennustada, millal mudelid teatud ülesandeid täitma hakkavad. Uurisime teemat oma artiklis põhjalikumalt artikkel arenguloo kohta GPT mudelid. Pildil on mudelite kvaliteedi tõusu jaotus erinevate ülesannete lõikes. Ainult suured modellid saavad õppida erinevaid ülesandeid täitma. See graafik toob esile suuruse suurendamise olulise mõju GPT mudelid nende toimivuse kohta erinevates ülesannetes. Siiski on oluline märkida, et see on suurenenud arvutusressursside ja keskkonnamõju hinnaga.
LLM-id õpivad mängima lauamänge, kasutades välismaailma esitusi
LLM-id õpivad ja kasutavad sageli välismaailma esitusi. Siin on palju näiteid ja siin on üks neist: Koolitatud modellid mängida lauamänge üksikute käikude kirjelduste põhjal, nägemata kordagi pilti mänguväljast, õppida laua seisukorra sisemisi kujutisi igal liigutusel. Neid sisemisi esitusi saab seejärel kasutada ennustada tulevikku käigud ja tulemused, võimaldades mudelil mängida mängu kõrgel tasemel. See võime õppida ja kasutada representatsioone on võtmetähtsusega masinõppe aspekt ja tehisintellekt.
LLM-i haldamiseks pole lihtsat lahendust
LLM-i käitumise kontrollimiseks pole usaldusväärseid meetodeid. Kuigi mõningaid edusamme on tehtud erinevate probleemide mõistmisel ja leevendamisel (sh ChatGPT ja GPT-4 tagasiside abil), puudub üksmeel, kas suudame need lahendada. Kasvab mure, et sellest saab tulevikus tohutu, potentsiaalselt katastroofiline probleem, kui luuakse veelgi suuremaid süsteeme. Seetõttu uurivad teadlased uusi meetodeid, et tagada tehisintellektisüsteemide vastavus inimlike väärtuste ja eesmärkidega, nagu väärtuste ühtlustamine ja tasustamine. Selle tagamine on aga endiselt keeruline ülesanne LLM-ide ohutus ja töökindlus keerulistes reaalmaailma stsenaariumides.
Ekspertidel on raskusi LLM-i toimimise selgitamisega
Eksperdid ei saa veel tõlgendada LLM-i sisemist tööd. Ükski tehnika ei võimalda meil rahuldaval viisil väita, milliseid teadmisi, arutluskäike või eesmärke mudel kasutab, kui see annab tulemuse. See tõlgendatavuse puudumine tekitab muret LLM-i otsuste usaldusväärsuse ja õigluse pärast, eriti suurte panustega rakenduste puhul, nagu kriminaalõigus või krediidiskoor. Samuti rõhutab see vajadust läbipaistvamate ja vastutustundlikumate tehisintellekti mudelite väljatöötamiseks täiendavate uuringute järele.
LLM-id on sama võimekad kui inimesed
Kuigi LLM-e koolitatakse peamiselt selleks jäljendada teksti kirjutamisel inimkäitumist, võivad nad meid paljudes ülesannetes ületada. Seda on näha juba malet või Go-d mängides. See on tingitud nende võimest analüüsida tohutul hulgal andmeid ja teha selle analüüsi põhjal otsuseid kiirusel, millega inimesed ei suuda võrrelda. Kuid LLM-idel puudub endiselt inimestel omane loovus ja intuitsioon, mis muudab nad paljude ülesannete jaoks vähem sobivaks.
LLM-id peavad olema midagi enamat kui lihtsalt "kõigepealt"
LLM-id ei tohi väljendada oma loojate väärtusi ega väärtusi, mis on kodeeritud valikusse Internetist. Nad ei tohiks korrata stereotüüpe ega vandenõuteooriaid ega püüda kedagi solvata. Selle asemel tuleks LLM-id kavandada nii, et nad annaksid oma kasutajatele erapooletut ja faktipõhist teavet, austades samal ajal kultuurilisi ja ühiskondlikke erinevusi. Lisaks tuleks neid regulaarselt testida ja jälgida, et tagada nende vastavus nendele standarditele.
Modellid on „targemad”, kui inimesed esmamulje põhjal arvavad
Esmamulje põhjal tehtud hinnangud modelli võimekuse kohta on sageli eksitavad. Väga sageli peate välja mõtlema õige viipa, soovitama mudelit ja võib-olla ka näiteid näitama ning see hakkab palju paremini toime tulema. See tähendab, et see on "targem", kui esmapilgul tundub. Seetõttu on ülioluline anda mudelile õiglane võimalus ja varustada see parimal viisil toimimiseks vajalike ressurssidega. Õige lähenemise korral võivad isegi näiliselt ebaadekvaatsed mudelid meid oma võimalustega üllatada.
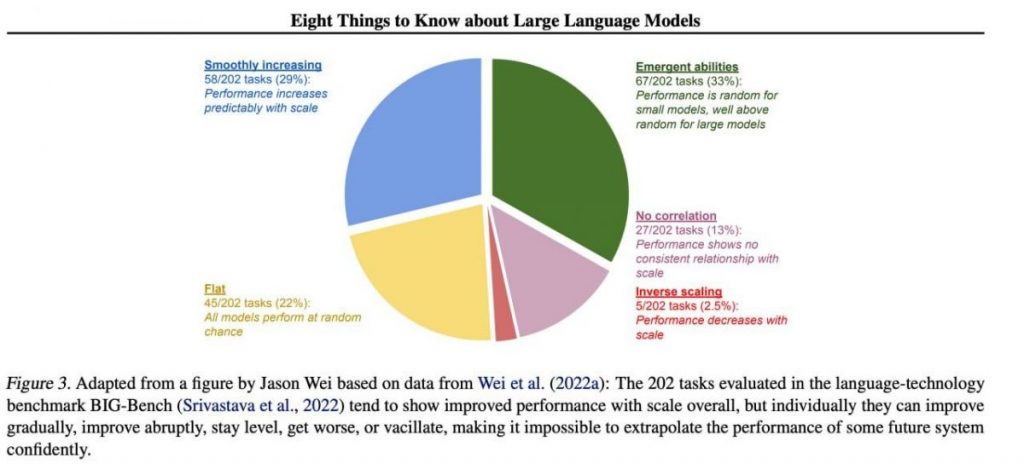
Kui keskendume BIG-Benchi andmestiku 202 ülesande valimile (selle testimine oli spetsiaalselt raskendatud keelemudelid alates ja kuni), siis reeglina (keskmiselt) näitavad mudelid kvaliteedi tõusu skaala suurenedes, kuid üksikult võivad ülesannete mõõdikud:
- paraneb järk-järgult,
- drastiliselt paraneda,
- jääb muutumatuks,
- vähenema,
- korrelatsiooni ei näita.
Kõik see viib selleni, et mis tahes tulevase süsteemi jõudlust ei ole võimalik enesekindlalt ekstrapoleerida. Eriti huvitav on roheline osa — just siin hüppavad kvaliteedinäitajad täiesti põhjuseta järsult üles.
Loe AI kohta lähemalt:
Kaebused
Vastavalt Usaldusprojekti juhised, pange tähele, et sellel lehel esitatud teave ei ole mõeldud ega tohiks tõlgendada kui juriidilist, maksu-, investeerimis-, finants- või muud nõuannet. Oluline on investeerida ainult seda, mida saate endale lubada kaotada, ja kahtluste korral küsida sõltumatut finantsnõu. Lisateabe saamiseks soovitame vaadata nõudeid ja tingimusi ning väljaandja või reklaamija pakutavaid abi- ja tugilehti. MetaversePost on pühendunud täpsele ja erapooletule aruandlusele, kuid turutingimusi võidakse ette teatamata muuta.
Umbes Autor
Damir on ettevõtte meeskonnajuht, tootejuht ja toimetaja Metaverse Post, mis hõlmab selliseid teemasid nagu AI/ML, AGI, LLM-id, Metaverse ja Web3-seotud väljad. Tema artiklid meelitavad igal kuul tohutut vaatajaskonda, üle miljoni kasutaja. Ta näib olevat ekspert, kellel on 10-aastane SEO ja digitaalse turunduse kogemus. Damirit on mainitud ajakirjades Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto ja muud väljaanded. Ta reisib digitaalse nomaadina AÜE, Türgi, Venemaa ja SRÜ vahel. Damir omandas bakalaureusekraadi füüsikas, mis on tema arvates andnud talle kriitilise mõtlemise oskused, mida on vaja pidevalt muutuval Interneti-maastikul edukaks saamiseks.
Veel artikleid
Damir on ettevõtte meeskonnajuht, tootejuht ja toimetaja Metaverse Post, mis hõlmab selliseid teemasid nagu AI/ML, AGI, LLM-id, Metaverse ja Web3-seotud väljad. Tema artiklid meelitavad igal kuul tohutut vaatajaskonda, üle miljoni kasutaja. Ta näib olevat ekspert, kellel on 10-aastane SEO ja digitaalse turunduse kogemus. Damirit on mainitud ajakirjades Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto ja muud väljaanded. Ta reisib digitaalse nomaadina AÜE, Türgi, Venemaa ja SRÜ vahel. Damir omandas bakalaureusekraadi füüsikas, mis on tema arvates andnud talle kriitilise mõtlemise oskused, mida on vaja pidevalt muutuval Interneti-maastikul edukaks saamiseks.






