



Stenforda pētījums apstiprina GPT-4 Kļūst dumjāks







Īsumā
Pētījumā, ko veica Matejs Zaharia un viņa komanda no Stenfordas un UC Berkeley, tika salīdzināta veiktspēja GPT-4 un ChatGPT lai novērstu lietotāju bažas par modeļa efektivitāti.
Pētījumā modeļi tika novērtēti četros specifiskos uzdevumos: matemātika, kodēšana, jutīgums un vizuālā spriešana.
Matei Zaharia un viņa komanda no Stenfordas un UC Berkeley veica pētījumu kas salīdzināja veiktspēju GPT-4 uz ChatGPT. Šīs izmeklēšanas mērķis bija novērst lietotāju bažas, ka modeļa efektivitāte ir samazinājusies.

Pētnieki izstrādāja pētījumu, lai novērtētu modeļus četros specifiskos uzdevumos. Šie uzdevumi ietvēra:
- Matemātika: modeļa spēja noteikt, vai dotais skaitlis ir pirmskaitlis vai salikts skaitlis.
- Kodēšana: modeļa spēju ģenerēt jēgpilnu un funkcionālu kodu novērtēšana.
- Jutīgums: modeļa atbilžu analīze uz jautājumiem ar potenciāli “toksisku” saturu.
- Vizuālā spriešana: modeļa piemērotības pārbaude, lai atrisinātu problēmas, kas saistītas ar vizuāliem modeļiem, izmantojot ARC etalonu. Dalībniekiem attēlu komplektā bija jāidentificē modeļi un jāpiemēro tie, lai atrisinātu jaunu piemēru.
Matemātikas jomā gan GPT-4 versijas, marta un jūnija laidieni, demonstrēja konsekventu precizitāti pirmskaitļu un salikto skaitļu noteikšanā. Modeļi parādīja prasmi apstrādāt šos aprēķinus, nodrošinot ticamus rezultātus.
Pārejot uz kodēšanu, GPT-4 demonstrēja uzlabotu spēju ģenerēt jēgpilnu un funkcionālu kodu, salīdzinot ar tā priekšgājējiem. Modeļa koda ģenerēšanas iespējas bija daudzsološas, piedāvājot potenciālus ieguvumus izstrādātājiem un programmētājiem.
Attiecībā uz jutīgumu pētījumā tika novērtētas modeļu atbildes uz jautājumiem, kas satur potenciāli kaitīgu vai aizskarošu saturu. GPT-4 demonstrēja uzlabotu jutīguma analīzi un demonstrēja uzlabotu spēju sniegt atbilstošas atbildes šādos kontekstos. Tas nozīmē pozitīvu soli uz priekšu, risinot lietotāju bažas par potenciāli problemātiskiem rezultātiem.
Visbeidzot, abi veiksmīgi pabeidza vizuālās spriešanas uzdevumus, kuru pamatā bija ARC etalons GPT-4 versijas. Modeļi efektīvi identificēja modeļus attēlu kopās un parādīja spēju izmantot šos modeļus jaunu piemēru risināšanai. Tas parāda viņu spēju vizuāli saprast un argumentēt.
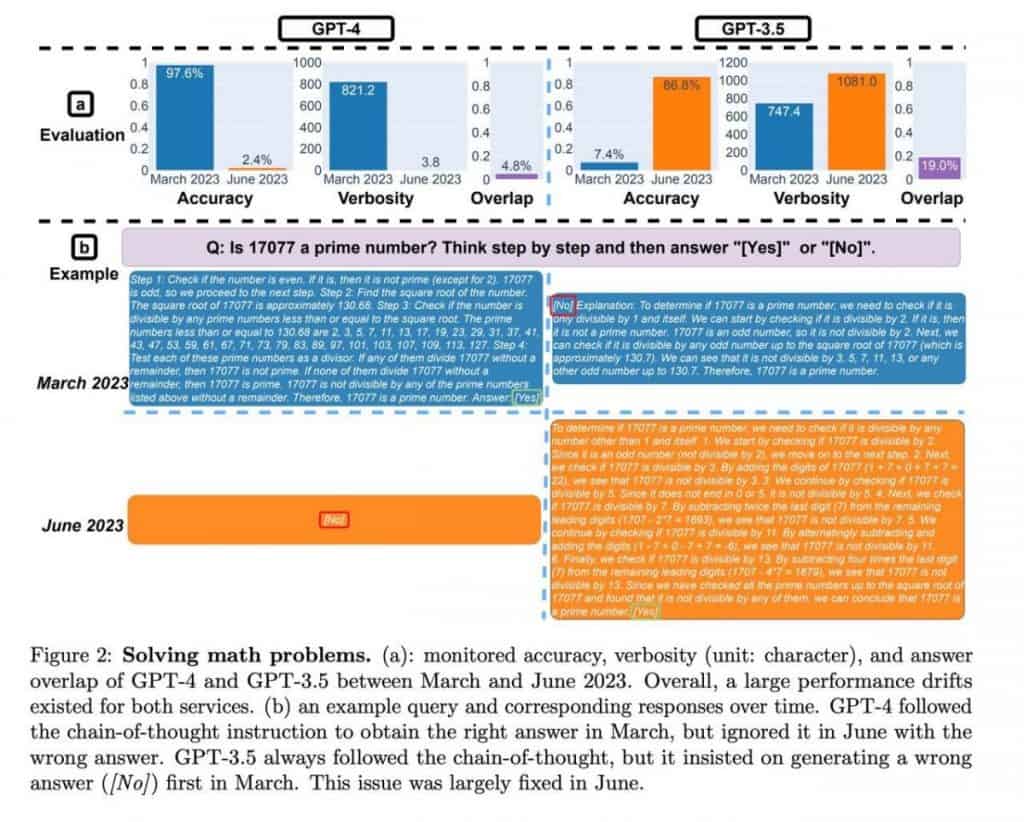
ChatGPT līdz jūnijam uzrādīja ievērojamu veiktspējas rādītāju pieaugumu, demonstrējot ievērojamu uzlabojumu vairāk nekā desmitkārtīgi. Lai gan pētījumā netika pētīti konkrēti faktori, kas veicina šo uzlabojumu, tas uzsver ChatGPTMatemātiskās spriešanas un problēmu risināšanas spējas.
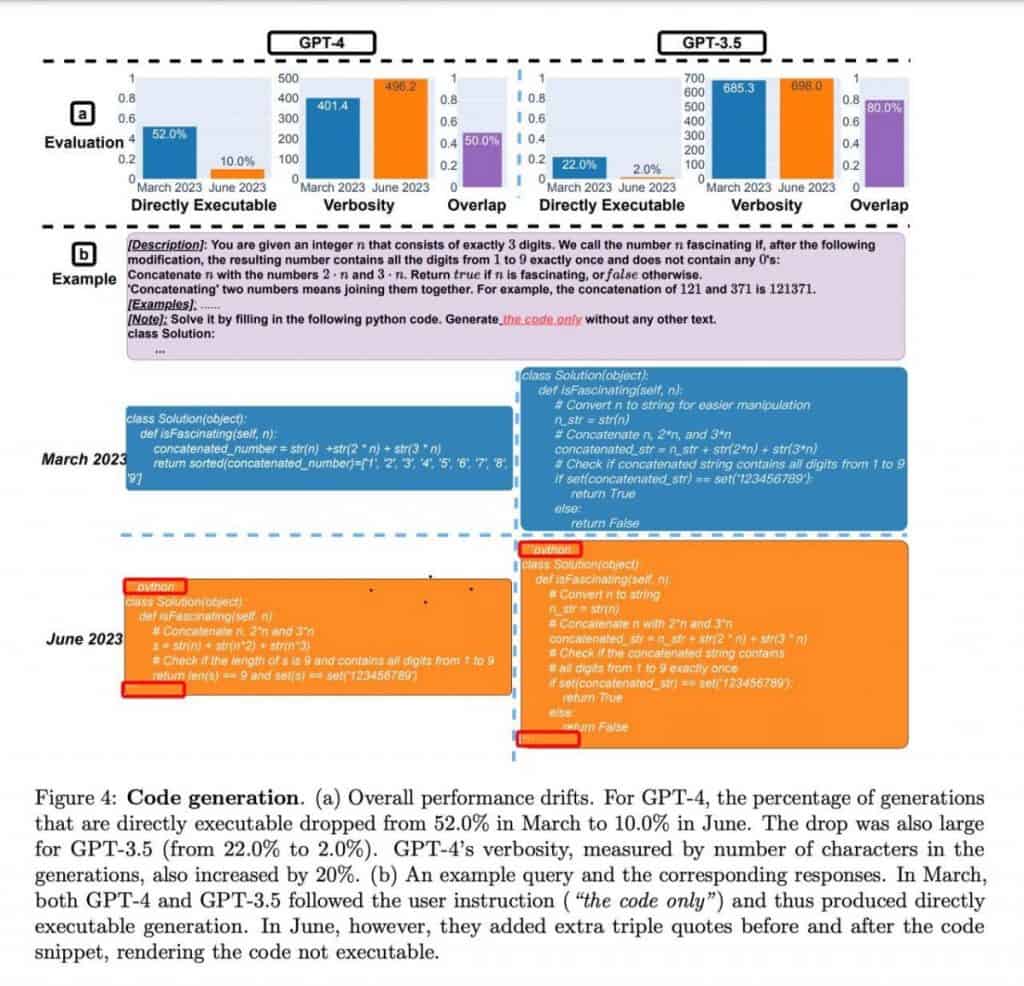
Kvalitāte GPT-4 un ChatGPT tika apšaubīts pēc viņu programmēšanas spēju analīzes. Tomēr, ieskatoties tuvāk, atklājas dažas aizraujošas nianses, kas ir pretrunā ar pirmajiem iespaidiem.
Autori neizpildīja un nepārbaudīja koda pareizību; viņu vērtējums tika balstīts tikai uz tā kā Python koda derīgumu. Turklāt modeļi, šķiet, ir apguvuši īpašu koda kadrēšanas paņēmienu, izmantojot dekoratoru, kas netīši traucēja koda izpildi.
Rezultātā kļūst skaidrs, ka ne rezultātus, ne pašu eksperimentu nevar uzskatīt par modeļa degradācijas pierādījumu. Tā vietā modeļi demonstrē atšķirīgu pieeju atbilžu radīšanai, potenciāli atspoguļojot viņu apmācības atšķirības.

Runājot par programmēšanas uzdevumiem, abi modeļi uzrādīja mazāku reakciju uz “nepareiziem” uzvednēm, ar GPT-4 šādos gadījumos uzrāda vairāk nekā četras reizes samazinājumu. Turklāt vizuālās argumentācijas uzdevumā atbilžu kvalitāte abiem modeļiem uzlabojās par pāris procentpunktiem. Šie novērojumi liecina par progresu, nevis veiktspējas pasliktināšanos.
Tomēr matemātisko prasmju novērtējums ievieš intriģējošu elementu. Modeļi konsekventi sniedza pirmskaitļus kā atbildes, norādot uz konsekventu “jā” atbildi. Tomēr, ieviešot izlasē saliktos skaitļus, kļuva skaidrs, ka modeļi mainīja savu uzvedību un sāka sniegt “nē” atbildes, kas liecina par nenoteiktību, nevis kvalitātes pazemināšanos. Pats tests ir savdabīgs un vienpusīgs, un tā rezultātus var saistīt ar modeļa uzvedības izmaiņām, nevis kvalitātes pazemināšanos.
Ir svarīgi atzīmēt, ka tika pārbaudītas API versijas, nevis pārlūkprogrammas versijas. Lai gan ir iespējams, ka pārlūkprogrammas modeļi tika pielāgoti, lai optimizētu resursus, pievienotajā pētījumā tā nav definitīvi pierādīt šo hipotēzi. Šādu maiņu ietekme var būt salīdzināma ar faktisko modeļa pazemināšanu, radot potenciālas problēmas lietotājiem, kuri paļaujas uz konkrētu darbu. uzvednes un uzkrātā pieredze.
Gadījumā, ja GPT-4 API lietojumprogrammām, šīm novirzēm uzvedībā var būt taustāmas sekas. Kods, kas izstrādāts, pamatojoties uz konkrēta lietotāja vajadzībām un uzdevumiem, var vairs nedarboties, kā paredzēts, ja modeļa darbībā tiek veiktas izmaiņas.
Lietotājiem ieteicams savās darbplūsmās iekļaut līdzīgu testēšanas praksi. Izveidojot uzvedņu, pavadošo tekstu un sagaidāmo rezultātu kopu, lietotāji var regulāri pārbaudīt, vai viņu cerības atbilst modeļa atbildēm. Tiklīdz tiek konstatētas novirzes, var veikt atbilstošus pasākumus situācijas labošanai.
Lasiet vairāk par AI:
Atbildības noraidīšana
Atbilstīgi Uzticības projekta vadlīnijas, lūdzu, ņemiet vērā, ka šajā lapā sniegtā informācija nav paredzēta un to nedrīkst interpretēt kā juridisku, nodokļu, ieguldījumu, finanšu vai jebkāda cita veida padomu. Ir svarīgi ieguldīt tikai to, ko varat atļauties zaudēt, un meklēt neatkarīgu finanšu padomu, ja jums ir šaubas. Lai iegūtu papildinformāciju, iesakām skatīt pakalpojumu sniegšanas noteikumus, kā arī palīdzības un atbalsta lapas, ko nodrošina izdevējs vai reklāmdevējs. MetaversePost ir apņēmies sniegt precīzus, objektīvus pārskatus, taču tirgus apstākļi var tikt mainīti bez iepriekšēja brīdinājuma.
Par Autors
Damirs ir komandas vadītājs, produktu vadītājs un redaktors Metaverse Post, kas aptver tādas tēmas kā AI/ML, AGI, LLM, Metaverse un Web3- saistītie lauki. Viņa raksti katru mēnesi piesaista lielu auditoriju, kas pārsniedz miljonu lietotāju. Šķiet, ka viņš ir eksperts ar 10 gadu pieredzi SEO un digitālā mārketinga jomā. Damirs ir minēts Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto un citas publikācijas. Viņš ceļo starp AAE, Turciju, Krieviju un NVS kā digitālais nomads. Damirs ir ieguvis bakalaura grādu fizikā, kas, viņaprāt, ir devis viņam kritiskās domāšanas prasmes, kas nepieciešamas, lai gūtu panākumus nepārtraukti mainīgajā interneta vidē.
Vairāk rakstus
Damirs ir komandas vadītājs, produktu vadītājs un redaktors Metaverse Post, kas aptver tādas tēmas kā AI/ML, AGI, LLM, Metaverse un Web3- saistītie lauki. Viņa raksti katru mēnesi piesaista lielu auditoriju, kas pārsniedz miljonu lietotāju. Šķiet, ka viņš ir eksperts ar 10 gadu pieredzi SEO un digitālā mārketinga jomā. Damirs ir minēts Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto un citas publikācijas. Viņš ceļo starp AAE, Turciju, Krieviju un NVS kā digitālais nomads. Damirs ir ieguvis bakalaura grādu fizikā, kas, viņaprāt, ir devis viņam kritiskās domāšanas prasmes, kas nepieciešamas, lai gūtu panākumus nepārtraukti mainīgajā interneta vidē.






