



LLM programmas: jauns ceļš uz neironu modeļu precizēšanu sarežģītās situācijās







Īsumā
Autori piedāvā alternatīvu ceļu, ko sauc par LLM programmām, ko var uzskatīt par konteksta mācīšanās attīstību.
Problēmas risināšanas atslēga, izmantojot LLM programmu, ir spēja sadalīt problēmas risinājumu vienkāršāku darbību secībā.
Ir divas galvenās LLM pielāgošanas jomas: iepriekš sagatavotā bāzes modeļa precizēšana (vai papildu apmācība) un mācīšanās kontekstā. Precīzajai noregulēšanai ir nepieciešami ievērojami skaitļošanas resursi, datu apkopošana un infrastruktūra, lai to paveiktu un pēc tam mitinātu precizētus modeļus. Tikmēr konteksta mācīšanās ietver pareizās uzvednes apkopošanu ar problēmas risināšanas piemēriem, piemēram, domu ķēdi (CoT). Tomēr ir dažas grūtības, piemēram, ierobežotais teksta lielums, ko var iesniegt modelī, un tas, ka sarežģītā vairākkārtēju uzvednē darbības var traucēt viena otrai un modeļa uzmanību var kaut kas novērst. ka šobrīd nevajadzētu novērst uzmanību. Autori piedāvā alternatīvu ceļu, ko sauc LLM programmas, ko var uzskatīt par konteksta mācīšanās attīstību.

| Ieteicams: Prompt Engineering Ultimate Guide 2023 |
LLM ir iebūvēta programmā (parastajā programmēšanas valoda, piemēram, Python). Šis ārējais kods ir atbildīgs par stāvokļa saglabāšanu un modeļa uzturēšanu soli pa solim. Tam ir dažas būtiskas priekšrocības: programmēšanas valodas ir pielāgotas šim nolūkam, pieejamā konteksta apjoms pieaug, un darbības netraucē viena otrai. Problēmas risināšanas atslēga, izmantojot LLM programmu, ir spēja sadalīt problēmas risinājumu vienkāršāku darbību secībā. Šī pieeja atšķiras no iepriekšējiem darbiem, kur modelī tika izmantoti ārēji rīki, piemēram, kalkulatori vai kodu tulki uzturēt valsti. Šī pieeja ir laba, jo tādā veidā ir iespējams aprakstīt sarežģītu un izplatītu uzdevumu, atvieglojot testēšanu, atkļūdošanu un kvalitātes novērtēšanu.
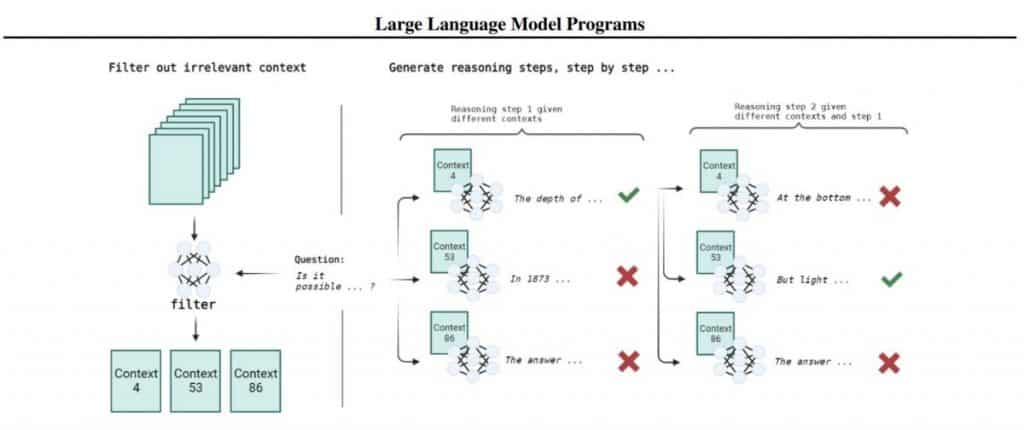
Turklāt starp soļiem nav traucējumu, kas atvieglo darbu ar LLM. Arī jautājumu-atbilžu sistēmas nav nekas jauns; tie ir pastāvējuši ilgi pirms LLM. Kā tagad tiek atrisināts uzdevums atbildēt uz jautājumiem?
Vietnes tiek bieži atjauninātas, tāpēc a saldēts modelis nav izvēles iespēja; tas ātri novecos un nespēs atbildēt uz jautājumiem par jauniem produktiem. Pastāvīga modeļa pārkvalificēšana katram atjauninājumam nav reāla iespēja: tā ir dārga un laikietilpīga. Tā vietā vietnes lapas parasti tiek indeksētas, ievietotas kaut kādā datu bāzē un bieži vien vektorizētas. Pēc lietotāja pieprasījuma attiecīgie dokumenti tiek izvilkti un nosūtīti kā konteksts LLM.
Šādā paradigmā problēma dabiski tiek atrisināta, izmantojot LLM programmu. Kā bonuss, tas kļūst iespējams lai ieviestu sarežģītāku vairākkārtēju loģiku, kas pilnībā neietilpst kontekstā.
Pārbaudīts uz StrategyQA datu kopa satur binārās klasifikācijas problēmas, kuru risināšana ietver daudzpusīgu spriešanu. Piemēram, "Vai saules gaisma iekļūst Melnās jūras dziļākajā vietā?". Lai atbildētu, jums jāatrod maksimālais dziļums (2 km) un cik dziļi gaisma iekļūst ūdenī (1 km), un pēc tam jāizdara secinājums. Apskatīsim vēl vienu jautājuma piemēru: “Vai Aristotelis izmantoja klēpjdatoru?” Šis jautājums nav tik vienkāršs un nepārprotami neseko argumentācijas darbību secībai kā “Vai Aristotelis bija dzīvs, kad tika izgudrots klēpjdators?” dara. Datu kopa koncentrējas uz jautājumiem, kur šāda secība ir netieša. Datu kopā ir tikai 2,780 jautājumi, no kuriem tikai 918 ir rindkopas ar pierādījumiem, kas pastiprina visus argumentācijas posmus. Pašreizējā darbā tas aprobežojas ar šo apakškopu; pretējā gadījumā mums būtu jāpaļaujas uz to, ka LLM priekšapmācības laikā uzzinās dažus faktus.
OPT-175B LLM pēc noklusējuma ne pārāk labi izpilda norādījumus; tai nebija jāprecizē norādījumi vai sarunvalodas dati. Lai atrisinātu ar pierādījumiem pamatotu jautājumu-atbilžu problēmu, tiek sadalīta datu filtrēšanas stadijā un koka meklēšanas posmā.
Filtrēšanas posmā izstrādātāji izpēta visas rindkopas un atlasa atbilstošākos. Piemēram, ar dažu metienu uzvedni palūdziet LLM atbildēt (jā/nē), vai dotā rindkopa attiecas uz uzdoto jautājumu. Pārbaudīts ar 300 StrategyQA apakškopu, kur katrs jautājums tika saskaņots ar rindkopu, kas atbilst vai neatbilst, 50/50. OPT-175B un text-davinci-002 nav a daudz augstāka kvalitāte nekā nejauša bāzes līnija: līdz 56%. Jo progresīvāks 11B Tk-Instruct nav daudz labāks — 61.6%.
Šīs pieejas sliktās kvalitātes dēļ tika izveidota alternatīva, kurā tiek ņemta vērā jautājuma vidējā negatīvā logaritmiskā iespējamība (NLL) kopā ar iepriekšējo teksta rindkopu un pēc tam sarindoti rezultāti. Novērtēts datu kopā, kur katram jautājumam bija 100 rindkopas, un tikai viena bija atbilstoša (tātad nejauša minēšana dod 1%). Mēs saņēmām labāko 1 precizitāti ar 79% un labāko 5 ar 93%. Šim aprēķinam parasti ir nepieciešama piekļuve pašam modelim, kas ne vienmēr tiek darīts API.
Nākamais nāk izvades ķēžu veidošanas posms. To veic, meklējot kokā, kur jautājums ir sakne, un katrā līmenī ir daudz rindkopu ar iespējamiem pierādījumiem, ko izmanto kā kontekstu, lai ģenerētu nākamo darbību. Katrs ceļš caur koku ir potenciāla izvades ķēde. Ir nereāli izdarīt secinājumus par visām iespējamām ķēdēm, tāpēc visas pieejamās ķēdes tiek sarindotas, un augstākā ranga ķēde tiek paplašināta. Šī ir tāda staru meklēšanas variācija. Process apstājas, kad tiek sniegta atbilde vai ir pagājis maksimālais atļautais darbību skaits.
Vissvarīgākā informācija ir divas ranžēšanas stratēģijas, kas pārbaudītas koka meklēšanas solī. Pirmā stratēģija ir balstīta uz visas ķēdes vidējo NLL, savukārt otrā stratēģija aplūko vidējo NLL atšķirību ar un bez rindkopas (P), ar un bez jautājuma (Q). Uz pieejamajiem 918 jautājumiem no StrategyQA šī pieeja ievērojami uzlabo atbilžu kvalitāti salīdzinājumā ar CoT bāzes līmeni (60%); abas meklēšanas iespējas sniedz aptuveni 66% (stratēģija ar nedaudz augstāku delta). Ja tiek iesniegti zelta fakti, kvalitāte kļūst aptuveni 81%, kas ir OPT augšējā robeža. Šķiet, ka Darklang tur kaut kur dodas, bet nedaudz savādāk.
Raksta pamatā ir Telegram nosūtīt.
Lasiet vairāk par AI:
Atbildības noraidīšana
Atbilstīgi Uzticības projekta vadlīnijas, lūdzu, ņemiet vērā, ka šajā lapā sniegtā informācija nav paredzēta un to nedrīkst interpretēt kā juridisku, nodokļu, ieguldījumu, finanšu vai jebkāda cita veida padomu. Ir svarīgi ieguldīt tikai to, ko varat atļauties zaudēt, un meklēt neatkarīgu finanšu padomu, ja jums ir šaubas. Lai iegūtu papildinformāciju, iesakām skatīt pakalpojumu sniegšanas noteikumus, kā arī palīdzības un atbalsta lapas, ko nodrošina izdevējs vai reklāmdevējs. MetaversePost ir apņēmies sniegt precīzus, objektīvus pārskatus, taču tirgus apstākļi var tikt mainīti bez iepriekšēja brīdinājuma.
Par Autors
Damirs ir komandas vadītājs, produktu vadītājs un redaktors Metaverse Post, kas aptver tādas tēmas kā AI/ML, AGI, LLM, Metaverse un Web3- saistītie lauki. Viņa raksti katru mēnesi piesaista lielu auditoriju, kas pārsniedz miljonu lietotāju. Šķiet, ka viņš ir eksperts ar 10 gadu pieredzi SEO un digitālā mārketinga jomā. Damirs ir minēts Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto un citas publikācijas. Viņš ceļo starp AAE, Turciju, Krieviju un NVS kā digitālais nomads. Damirs ir ieguvis bakalaura grādu fizikā, kas, viņaprāt, ir devis viņam kritiskās domāšanas prasmes, kas nepieciešamas, lai gūtu panākumus nepārtraukti mainīgajā interneta vidē.
Vairāk rakstus
Damirs ir komandas vadītājs, produktu vadītājs un redaktors Metaverse Post, kas aptver tādas tēmas kā AI/ML, AGI, LLM, Metaverse un Web3- saistītie lauki. Viņa raksti katru mēnesi piesaista lielu auditoriju, kas pārsniedz miljonu lietotāju. Šķiet, ka viņš ir eksperts ar 10 gadu pieredzi SEO un digitālā mārketinga jomā. Damirs ir minēts Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto un citas publikācijas. Viņš ceļo starp AAE, Turciju, Krieviju un NVS kā digitālais nomads. Damirs ir ieguvis bakalaura grādu fizikā, kas, viņaprāt, ir devis viņam kritiskās domāšanas prasmes, kas nepieciešamas, lai gūtu panākumus nepārtraukti mainīgajā interneta vidē.






