



L'estudi de Stanford confirma GPT-4 S'està tornant més tonto







En breu
Un estudi de Matei Zaharia i el seu equip de Stanford i UC Berkeley va comparar el rendiment de GPT-4 i ChatGPT per atendre les preocupacions dels usuaris sobre l'eficàcia del model.
L'estudi va avaluar els models en quatre tasques específiques: matemàtiques, codificació, sensibilitat i raonament visual.
Matei Zaharia i el seu equip de Stanford i UC Berkeley va dur a terme un estudi que comparava el rendiment de GPT-4 a ChatGPT. Aquesta investigació pretenia resoldre les preocupacions dels usuaris que l'eficàcia del model havia disminuït.

Els investigadors van dissenyar l'estudi per avaluar els models en quatre tasques específiques. Aquestes tasques incloïen:
- Matemàtiques: capacitat del model per determinar si un nombre donat és primer o compost.
- Codificació: avaluació de la capacitat del model per generar codi significatiu i funcional.
- Sensibilitat: anàlisi de les respostes del model a preguntes amb contingut potencialment "tòxic".
- Raonament visual: prova de l'aptitud del model per resoldre problemes que impliquen patrons visuals, utilitzant el benchmark ARC. Els participants havien d'identificar patrons en un conjunt d'imatges i aplicar-los per resoldre un nou exemple.
En l'àmbit de les matemàtiques, tots dos GPT-4 Les versions, les versions de març i juny, van mostrar una precisió constant en la determinació de nombres primers i compostos. Els models van mostrar competència en el maneig d'aquests càlculs, proporcionant resultats fiables.
Passant a la codificació, GPT-4 va mostrar una capacitat millorada per generar codi significatiu i funcional en comparació amb els seus predecessors. Les capacitats de generació de codi del model eren prometedores, oferint beneficis potencials per als desenvolupadors i programadors.
Pel que fa a la sensibilitat, l'estudi va avaluar les respostes dels models a preguntes que contenien contingut potencialment nociu o ofensiu. GPT-4 va demostrar una anàlisi de sensibilitat millorada i va mostrar una capacitat millorada per proporcionar respostes adequades en aquests contextos. Això significa un pas positiu endavant per abordar les preocupacions dels usuaris sobre els resultats potencialment problemàtics.
Finalment, ambdós van completar amb èxit les tasques de raonament visual basades en el benchmark ARC GPT-4 versions. Els models van identificar eficaçment patrons dins dels conjunts d'imatges i van demostrar la capacitat d'aplicar aquests patrons per resoldre nous exemples. Això demostra la seva capacitat de comprensió i raonament visual.
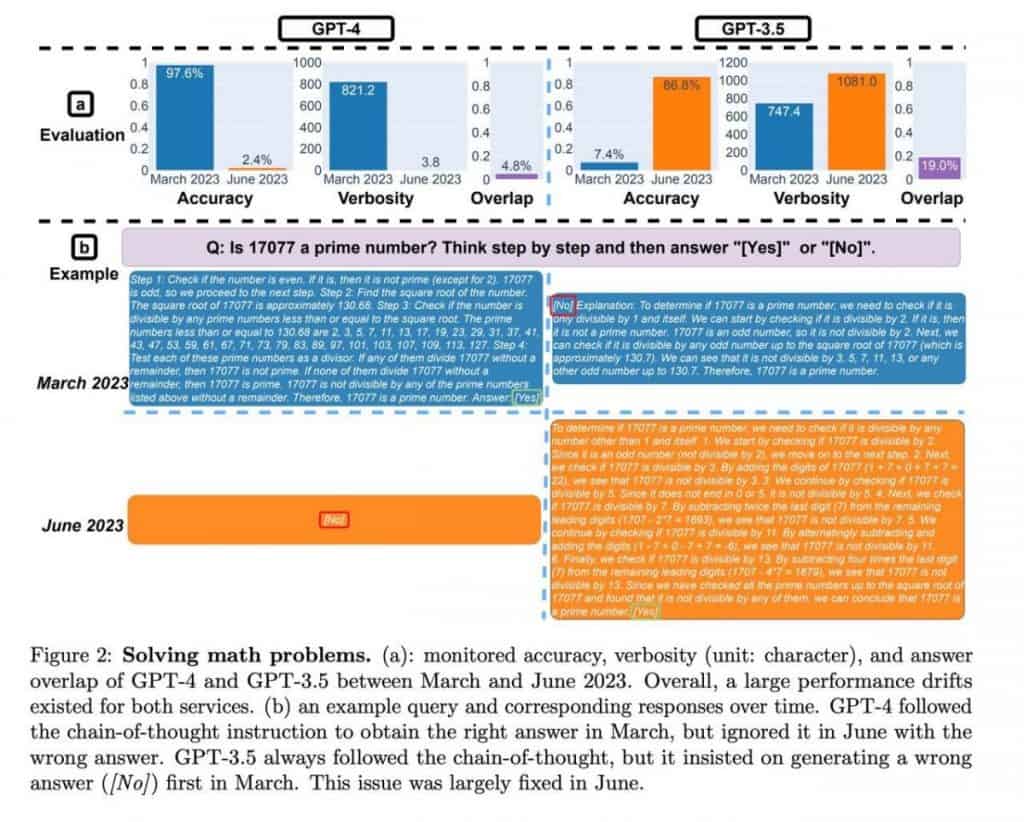
ChatGPT va demostrar un creixement substancial en les mètriques de rendiment al juny, mostrant una millora notable de més de deu vegades. Tot i que l'estudi no va aprofundir en els factors específics que contribueixen a aquesta millora, en destaca ChatGPTl'avenç en el raonament matemàtic i les capacitats de resolució de problemes.
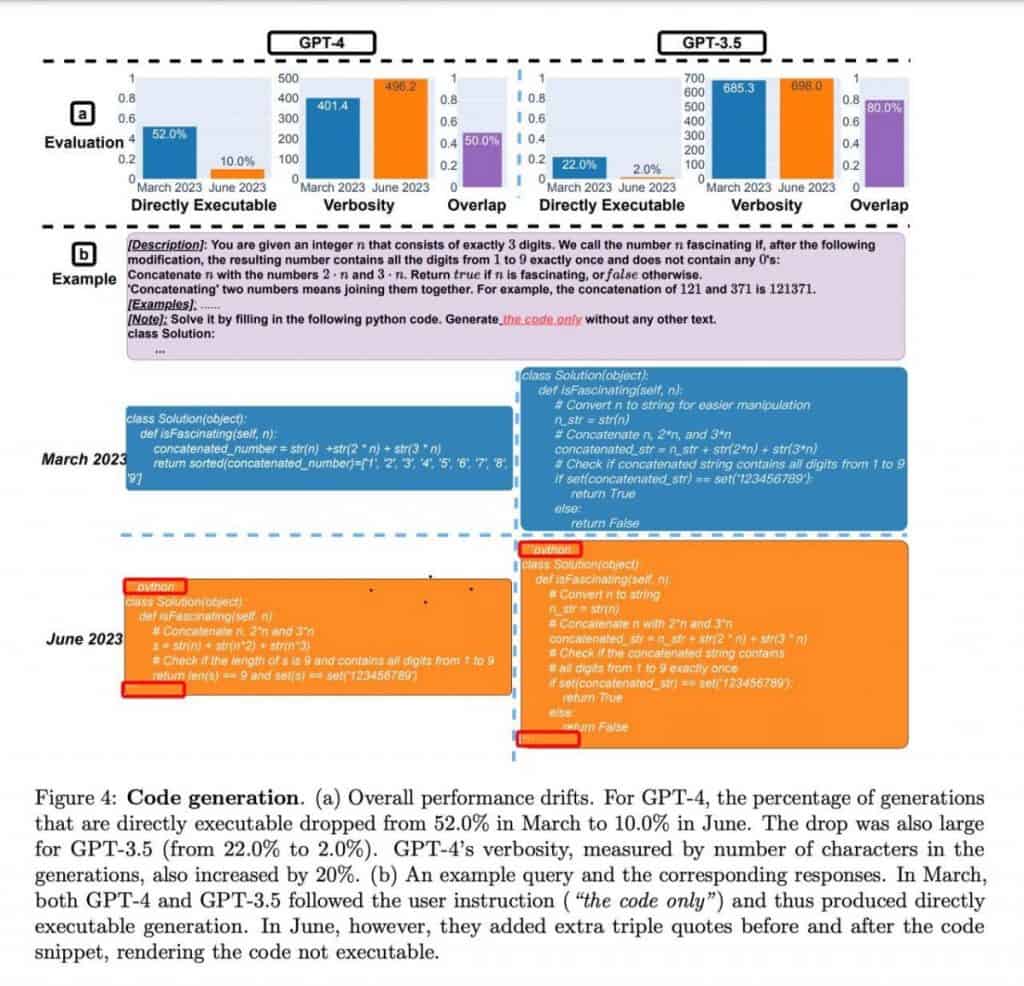
La qualitat de GPT-4 i ChatGPT ha estat qüestionat després d'una anàlisi de les seves capacitats de programació. No obstant això, una mirada més propera revela alguns matisos fascinants que contradiuen les primeres impressions.
Els autors no van executar ni verificar la correcció del codi; la seva avaluació es va basar únicament en la seva validesa com a codi Python. A més, els models semblaven haver après una tècnica específica d'enquadrament de codi mitjançant un decorador, la qual cosa impedia involuntàriament l'execució del codi.
Com a resultat, es fa evident que ni els resultats ni l'experiment en si es poden considerar com a evidència de la degradació del model. En canvi, els models demostren un enfocament diferent per generar respostes, que poden reflectir variacions en la seva formació.

Pel que fa a les tasques de programació, ambdós models van mostrar una disminució en la resposta a les indicacions "equivocades", amb GPT-4 mostrant una reducció de més de quatre vegades en aquests casos. A més, a la tasca de raonament visual, la qualitat de les respostes va millorar un parell de punts percentuals per als dos models. Aquestes observacions indiquen progrés en lloc de degradació del rendiment.
Tanmateix, l'avaluació de les habilitats matemàtiques introdueix un element intrigant. Els models van proporcionar de manera consistent nombres primers com a respostes, indicant una resposta "sí" consistent. No obstant això, en introduir números compostos a la mostra, es va fer evident que els models van canviar el seu comportament i van començar a donar respostes "no", cosa que suggereix incertesa més que una disminució de la qualitat. La prova en si és peculiar i unilateral, i els seus resultats es poden atribuir a canvis en el comportament del model més que a una disminució de la qualitat.
És important tenir en compte que es van provar les versions de l'API i no les versions basades en navegador. Tot i que és possible que els models del navegador hagin sofert ajustos per optimitzar els recursos, l'estudi adjunt no ho fa defidemostrar de manera nitiva aquesta hipòtesi. L'impacte d'aquests canvis pot ser comparable a les rebaixes reals dels models, la qual cosa comporta possibles reptes per als usuaris que depenen d'un treball específic. avisa i experiència acumulada.
En el cas de GPT-4 Aplicacions API, aquestes desviacions de comportament poden tenir conseqüències tangibles. El codi desenvolupat en funció de les necessitats i tasques d'un usuari específic pot deixar de funcionar com es pretenia si el model experimenta canvis en el seu comportament.
Es recomana que els usuaris incorporin pràctiques de prova similars als seus fluxos de treball. Mitjançant la creació d'un conjunt d'indicacions, textos d'acompanyament i resultats esperats, els usuaris poden comprovar regularment la coherència entre les seves expectatives i les respostes del model. Tan bon punt es detecti qualsevol desviació, es poden prendre les mesures oportunes per corregir la situació.
Llegeix més sobre AI:
renúncia
En línia amb la Directrius del projecte Trust, si us plau, tingueu en compte que la informació proporcionada en aquesta pàgina no pretén ni s'ha d'interpretar com a assessorament legal, fiscal, d'inversió, financer o de cap altra forma. És important invertir només el que et pots permetre perdre i buscar assessorament financer independent si tens dubtes. Per obtenir més informació, us suggerim que feu referència als termes i condicions, així com a les pàgines d'ajuda i assistència proporcionades per l'emissor o l'anunciant. MetaversePost es compromet a fer informes precisos i imparcials, però les condicions del mercat estan subjectes a canvis sense previ avís.
About The Autor
Damir és el líder d'equip, cap de producte i editor de Metaverse Post, que cobreix temes com AI/ML, AGI, LLMs, Metaverse i Web3-camps relacionats. Els seus articles atrauen una audiència massiva de més d'un milió d'usuaris cada mes. Sembla ser un expert amb 10 anys d'experiència en SEO i màrqueting digital. Damir ha estat esmentat a Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto i altres publicacions. Viatja entre els Emirats Àrabs Units, Turquia, Rússia i la CEI com a nòmada digital. Damir va obtenir una llicenciatura en física, que creu que li ha donat les habilitats de pensament crític necessàries per tenir èxit en el paisatge en constant canvi d'Internet.
més articles
Damir és el líder d'equip, cap de producte i editor de Metaverse Post, que cobreix temes com AI/ML, AGI, LLMs, Metaverse i Web3-camps relacionats. Els seus articles atrauen una audiència massiva de més d'un milió d'usuaris cada mes. Sembla ser un expert amb 10 anys d'experiència en SEO i màrqueting digital. Damir ha estat esmentat a Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto i altres publicacions. Viatja entre els Emirats Àrabs Units, Turquia, Rússia i la CEI com a nòmada digital. Damir va obtenir una llicenciatura en física, que creu que li ha donat les habilitats de pensament crític necessàries per tenir èxit en el paisatge en constant canvi d'Internet.






