



Nvidia va anunciar eDiff-I: nova IA generativa per a la síntesi de text i imatges amb transferència instantània d'estils






En breu
Nvidia llança eDiff-I per ajudar les empreses a crear imatges atractives i d'alta qualitat
La tècnica eDiff-I produeix regularment una qualitat de síntesi més gran que DALL-E2 i Stable diffusion
eDiff-I és una nova eina de creació de contingut d'IA que proporciona capacitats de síntesi de text a imatge sense precedents per als venedors i les empreses, tal com va anunciar recentment Nvidia. Amb eDiff-I, les empreses poden crear de manera ràpida i senzilla imatges atractives i d'alta qualitat sense necessitat d'equips costosos o ajuda professional. eDiff-I utilitza el processament del llenguatge natural (NLP) per interpretar l'entrada de l'usuari i generar les imatges corresponents. A continuació, l'IA analitza les imatges i tria la més adequada en funció del context. El resultat és una imatge d'alta qualitat i d'aspecte professional que es pot utilitzar per a diversos propòsits, com ara materials de màrqueting, publicacions a les xarxes socials, campanyes de correu electrònic i molt més.
eDiff-I és a IA generativa de nova generació eina de creació de contingut que ofereix sense precedents text a imatge síntesi, transferència d'estil ràpida i pintura intuïtiva amb paraules. Com a model de difusió per crear imatges a partir de text, eDiff-I suggereix entrenar un conjunt de xarxes expertes de reducció de soroll, cadascuna especialitzada per a un interval de soroll particular, en resposta a la troballa empírica que el comportament dels models de difusió varia en diferents fases del mostreig.

Les incrustacions de text T5, les incrustacions d'imatges CLIP i les incrustacions de text CLIP proporcionen la base per al concepte eDiff-I. Aquesta metodologia pot produir gràfics fotorealistes en resposta a qualsevol consulta de text.
Presenta dues capacitats addicionals a més de la síntesi de text a imatge: (1) transferència d'estil, que ens permet controlar l'estil de la mostra generada mitjançant una imatge d'estil de referència i (2) "Pintar amb paraules", una eina. que permet als usuaris crear imatges pintant mapes de segmentació sobre llenç.
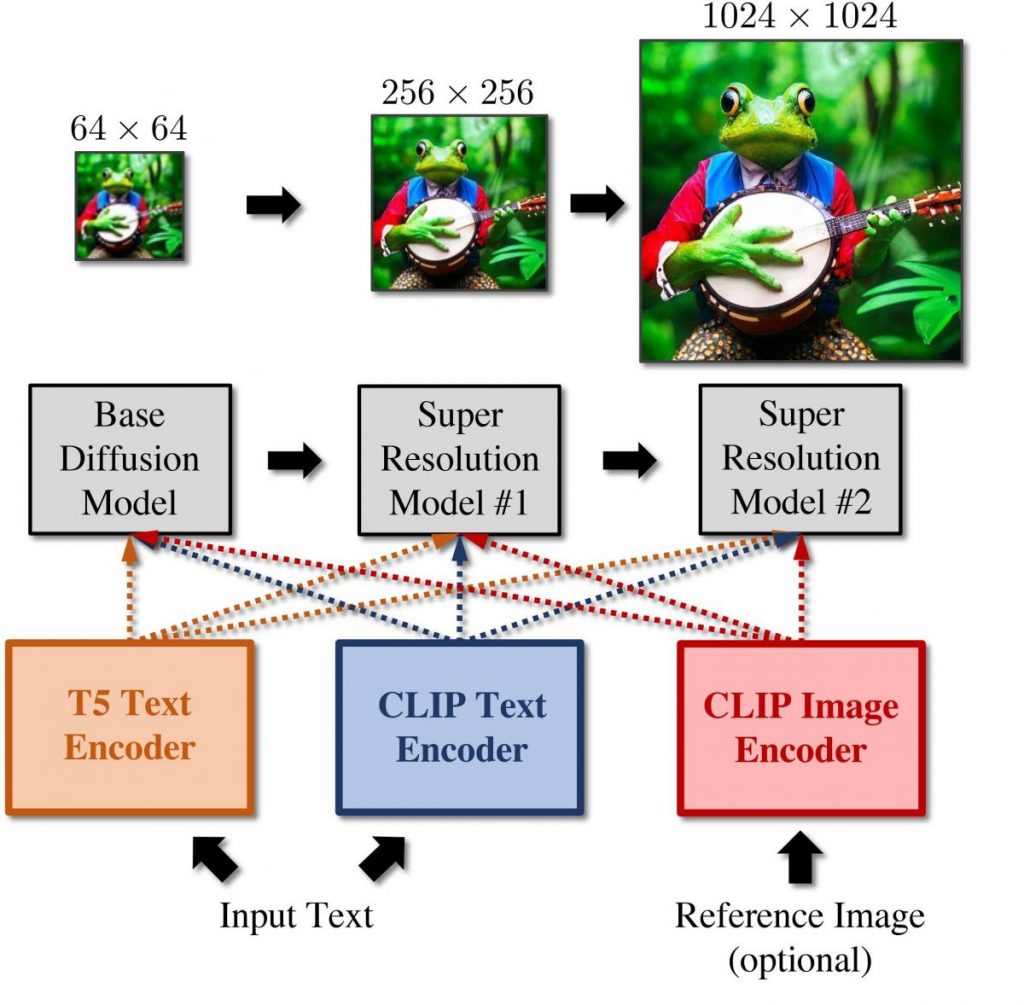
El pipeline consta d'una cascada de tres models de difusió: un model base que pot crear mostres amb una resolució de 64 × 64 i dues piles de superresolució que poden augmentar gradualment les imatges a resolucions de 256 × 256 i 1024 × 1024, respectivament. Els models calculen T5 XXL i la incrustació de text després de rebre un subtítol com a entrada. Aquestes incrustacions d'imatges es poden utilitzar com a vector d'estil. A continuació, introduïu aquestes incrustacions a la nostra cascada models de difusió, que produeixen imatges gradualment amb una resolució de 1024 x 1024.
L'enfocament eDiff-I dóna com a resultat una millor qualitat de síntesi en comparació amb els algorismes de codi obert de text a imatge (Stable diffusion) i (DALL-E2).

Quan s'utilitzen les incrustacions d'imatge CLIP, l'enfocament eDiff-I facilita la transferència d'estil. eDiff-I extreu primer el CLIP incrustacions d'imatges a partir d'una imatge d'estil de referència, que es pot utilitzar com a vector de referència d'estil. Es pot veure una referència estilística al plafó esquerre de la figura següent. Els resultats quan s'activa el condicionament d'estil es mostren al tauler central. Els resultats quan el condicionament d'estil està desactivat es mostren al tauler de la dreta. Quan s'aplica el condicionament d'estil, el model eDiff-I també crea sortides fidels a l'estil del subtítol d'entrada. Quan el condicionament d'estil està desactivat, es produeixen fotos d'aspecte natural.

Escollint frases i gargotejant-les a la imatge, els usuaris del mètode eDiff-I poden canviar la ubicació de les coses que s'enumeren al missatge de text. Després d'això, el model utilitza el prompte i els mapes per crear imatges que són compatibles tant amb el subtítol com amb el mapa d'entrada.
Llegeix articles relacionats:
renúncia
En línia amb la Directrius del projecte Trust, si us plau, tingueu en compte que la informació proporcionada en aquesta pàgina no pretén ni s'ha d'interpretar com a assessorament legal, fiscal, d'inversió, financer o de cap altra forma. És important invertir només el que et pots permetre perdre i buscar assessorament financer independent si tens dubtes. Per obtenir més informació, us suggerim que feu referència als termes i condicions, així com a les pàgines d'ajuda i assistència proporcionades per l'emissor o l'anunciant. MetaversePost es compromet a fer informes precisos i imparcials, però les condicions del mercat estan subjectes a canvis sense previ avís.
About The Autor
Damir és el líder d'equip, cap de producte i editor de Metaverse Post, que cobreix temes com AI/ML, AGI, LLMs, Metaverse i Web3-camps relacionats. Els seus articles atrauen una audiència massiva de més d'un milió d'usuaris cada mes. Sembla ser un expert amb 10 anys d'experiència en SEO i màrqueting digital. Damir ha estat esmentat a Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto i altres publicacions. Viatja entre els Emirats Àrabs Units, Turquia, Rússia i la CEI com a nòmada digital. Damir va obtenir una llicenciatura en física, que creu que li ha donat les habilitats de pensament crític necessàries per tenir èxit en el paisatge en constant canvi d'Internet.
més articles
Damir és el líder d'equip, cap de producte i editor de Metaverse Post, que cobreix temes com AI/ML, AGI, LLMs, Metaverse i Web3-camps relacionats. Els seus articles atrauen una audiència massiva de més d'un milió d'usuaris cada mes. Sembla ser un expert amb 10 anys d'experiència en SEO i màrqueting digital. Damir ha estat esmentat a Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto i altres publicacions. Viatja entre els Emirats Àrabs Units, Turquia, Rússia i la CEI com a nòmada digital. Damir va obtenir una llicenciatura en física, que creu que li ha donat les habilitats de pensament crític necessàries per tenir èxit en el paisatge en constant canvi d'Internet.






